BlahST
Multilingual BlahST
Blah s Peech-to exting le permite tener un texto que ingrese Bla (H) ST del discurso en Linux, con atajos de teclado y susurros.cpp. Enciende tu micrófono y realiza un reconocimiento de voz multilingüe de alta calidad fuera de línea. Extendido con LLM locales, se convierte en una herramienta potente para conversar con su computadora Linux.
Blahst es probablemente la herramienta de entrada de voz a texto basada en el habla más delgada para Linux, que se encuentra encima de Whisper.cpp.
wsiml dedicadoUtilizando herramientas de línea de comandos optimizadas de baja recursos, la entrada de texto hablado ocurre muy rápido. Aquí hay un video de demostración (por favor, active el audio) con algunas características locales de LLM (asistente de IA, traductor, programador, guía de CLI en la etapa de prueba):
En el video anterior, el audio comienza con el sistema que anuncia el screencasting (mi extensión de gnomo "voluble" habla sobre todas las notificaciones de escritorio Gnome), seguido de múltiples giros de entrada/reconocimiento del habla. Al final, se demuestra una de las "funciones de IA" que utiliza el texto transcrito por Blahst (Whisper.cpp), lo formatea en un mensaje LLM y lo envía a un LLM multilingüe local (llama.cpp o llamafile) que devuelve la traducción china como texto y también lo habla con un TTS neural. Orquestando esto desde la línea de comando con ejecutables Lean deja el sistema sorprendentemente ágil (desde el video puede ver que la PC apenas rompe el sudor: las temperaturas permanecen bajas).
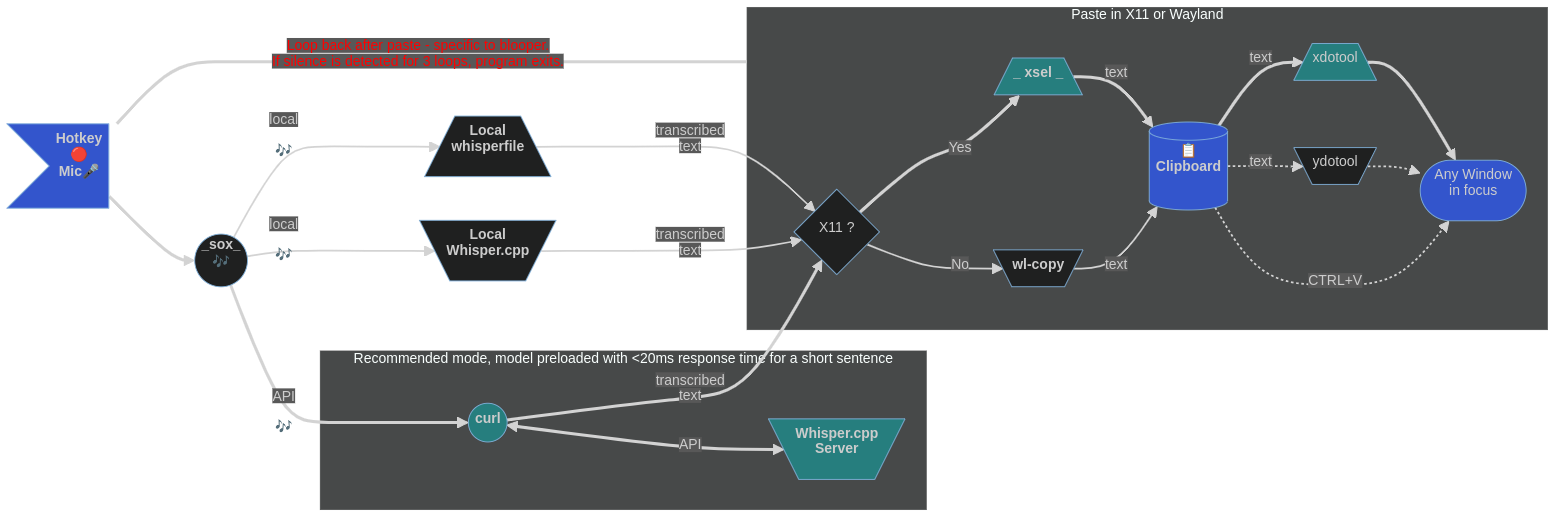
El video anterior (inmerso) demuestra el uso de Blooper, modificado de WSI para transcribir en un bucle, hasta que el usuario termine la entrada del habla con una pausa más larga (~ 3sec como preestablecido). Con el uso de XDotool (o YdoTool para usuarios de Wayland), el texto se pega automáticamente en cualquier pausa (o en interpción de llave de acceso rápido). Para el video de arriba, el discurso se genera con una voz sintética y recopila por el micrófono. Esto me permite editar el texto simultáneamente (multitarea, no intente esto en casa :). Al final, el ícono del micrófono de la barra superior debe desaparecer, lo que indica la salida del programa. No sucede en el video porque la utilidad Screencast también tiene un reclamo sobre el ícono.
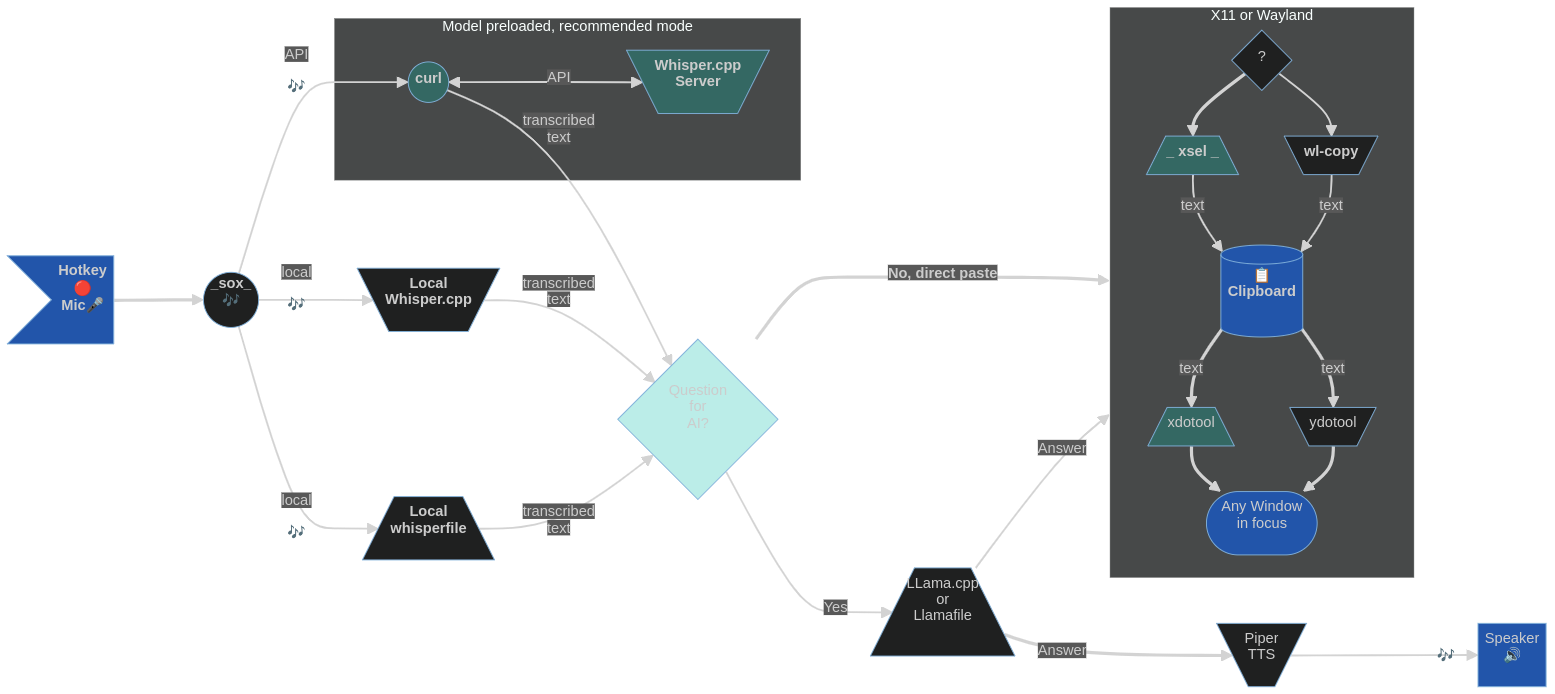
La idea con Blahst es ser el software sin UI equivalente a una redada mongol; Breve y potente estallido de acción de CPU/GPU y luego se ha ido por completo, con solo rastros textuales en el portapapeles y la paz relativa de escritorio. Simplemente use un par de teclas de acceso rápido para comenzar y dejar de grabar desde el micrófono y enviar el discurso grabado a Whisper.cpp [servidor] que descarga texto transcrito en el portapapeles (a menos que lo pase por un LLM local antes de eso). Un enfoque universal que debería funcionar en la mayoría de los entornos y distribuciones de escritorio de Linux.
El trabajo lo realiza uno de los guiones:
El reconocimiento de voz es realizado por Whisper.cpp, que debe precompilarse en su sistema Linux o disponible como instancia de servidor en su LAN o localhost. Alternativamente, puede elegir simplemente descargar y usar un ejecutable realmente portátil (con un modelo de susurro incrustado) Whisperfile, ahora parte del repositorio de LlamaFile.
Cuando la entrada del habla se inicia con una tecla de acceso rápido, aparece un indicador de micrófono en la barra superior (al menos en gnomo) y se muestra durante la duración de la grabación (se puede interrumpir con otra tecla de acceso rápido). La desaparición del icono del micrófono desde la barra superior indica la finalización y el texto transcrito se puede pegar desde el portapapeles. En los sistemas más lentos puede haber un ligero retraso después de que el icono del micrófono desaparece y antes de que el texto llegue al portapapeles debido a un mayor tiempo de transcripción. En mi computadora, a través de la API del servidor Whisper.CPP, es de menos de 150 ms (300 ms con Whisper.cpp local) para un párrafo promedio de texto hablado.
Para la operación de solo teclado, con el CTRL+V estándar, por ejemplo, el portapapeles estándar se usará en X11 y Wayland ( wsi o wsiml ), mientras que wsi -p (o wsiml -p ) usa la venta principal y el texto se pega con el botón del mouse medio). Para la pasta izquierda, la grabación del habla se puede relegarse a teclas de acceso rápido activado con la mano derecha. ** Por ejemplo, he configurado las teclas "+" (Iniciar grabación) e "Insertar" (Insertar "(Stop Granding) no utilizados en el teclado numérico.
install-wsi maneja la mayoría de estos).Descargo de responsabilidad: el autor no toma crédito ni asume ninguna responsabilidad por ningún resultado que pueda o no resultar de interactuar con el contenido de este documento. Las acciones y automatidades propuestas (por ejemplo, ubicaciones de instalación, etc.) son simplemente sugerencias y se basan en la elección y la opinión del autor. Como pueden no encajar en el sabor o la situación particular de todos, por favor, ajuste según sea necesario.
En una carpeta de su elección, clone el repositorio de Blahst y luego elija un método de instalación desde abajo:
git clone https://github.com/QuantiusBenignus/BlahST.git
cd ./BlahST
(Suponiendo que Whisper.cpp está instalado y el ejecutable "principal" compilado con 'Make' en el clonado Whisper.cpp Repo. Consulte la sección Requisitos previos)
cd $HOME/.local/bin; chmod +x wsi wsiAI wsiml
$HOME/.local/bin/ (parte de su ruta $) con ln -s /full/path/to/whisper.cpp/main $HOME/.local/bin/transcribe
Si Transcribe no está en su ruta $, edite la llamada en WSI para incluir la ruta absoluta o agregar su ubicación a la variable de ruta $. De lo contrario, el script fallará. Si prefiere no compilar Whisper.cpp, o además de eso, descargue y establezca la bandera ejecutable de un Whisperfile adecuado, por ejemplo:
cd $HOME/.local/bin
wget https://huggingface.co/Mozilla/whisperfile/resolve/main/whisper-tiny.en.llamafile
chmod +x whisper-tiny.en.llamafile
Dentro del script wsi , wsiAI , wsiml o blooper , cerca del comienzo, hay una sección claramente marcada, llamada "Bloque de configuración del usuario" , donde se han recopilado todas las variables configurables por el usuario. La mayoría se puede dejar como está, pero los importantes son la ubicación de los archivos de modelo (Whisper, LLM, TTS) que desea usar durante la transcripción (o el número de puerto y el número de puerto para el servidor Whisper.cpp). Si usa un Whisperfile, por favor, establezca la variable Whisperfile en el nombre de archivo del ejecutable Whisperfile anteriormente descargado, es decir, WHISPERFILE=whisper-tiny.en.llamafile (debe estar en la ruta $).
Para iniciar y detener la entrada del habla, para la instalación manual y automática
/home/yourusername/.local/bin/wsi -p para usar el botón Medio Mouse o cambiarlo a .../wsi para usar el portapapeles.wsi arriba con wsiml y si usa un Whisperfile, agregue la bandera -w , es decir /home/yourusername/.local/bin/wsi -w ). Finalmente, para probar las funciones de LLM, reemplace wsi con wsiAI .El script del orquestador tiene un filtro de detección de silencio en la llamada a los SOX (REC) y dejaría de grabar (en el mejor de los mejores) en 2 segundos de silencio. Además, si uno no quiere esperar o tiene problemas con el umbral de detección de silencio:
Para aquellos que desean poder interrumpir la grabación manualmente con una combinación clave, en el espíritu de grandes hacks, vamos a usar las características incorporadas del sistema:
pkill --signal 2 recEso simple. Solo asegúrese de que el nuevo enlace clave ya no se haya configurado para otra cosa. Ahora, cuando el guión está grabando el discurso, se puede detener con el nuevo combo de teclas y la transcripción comenzará de inmediato.
/home/yourusername/.local/bin/wsi -p o .../wsi para usar el portapapeles.wsi arriba con wsiml y si usa un Whisperfile, agregue la bandera -w , es decir /home/yourusername/.local/bin/wsi -w ). Finalmente, para probar las funciones de LLM, reemplace wsi con wsiAI .pkill --signal 2 rec ./home/yourusername/.local/bin/wsi o .../wsi -pwsi arriba con wsiml y si usa un Whisperfile, agregue la bandera -w , es decir /home/yourusername/.local/bin/wsi -w ). Finalmente, para probar las funciones de LLM, reemplace wsi con wsiAI .pkill --signal 2 rec .Tenga en cuenta que puede haber ligeras variaciones en los pasos anteriores dependiendo de la versión instalada en su sistema. Para muchos otros entornos, como Mate, Cinnamon, LXQT, Deepin , etc. Los pasos deben ser algo similares a los ejemplos anteriores. Por favor, consulte la documentación para su entorno de escritorio de sistemas.
En la presión de un combo de tecla de acceso rápido, el script wsi -p registrará el discurso (detenido con una tecla de acceso rápido o por detección de silencio), use una copia local de Whisper.cpp y enviará el texto transcrito a la selección primaria debajo, X11 o Wayland. Entonces, todo lo que uno tiene que hacer es pegarlo con el botón del mouse central en cualquier lugar que desee. (Para las personas que sostienen el mouse con su mano derecha, el discurso grabando teclas de acceso rápido para la mano izquierda tendría sentido).
Si usa wsi sin banderas (los enfoques pueden coexistir, simplemente configurar diferentes conjuntos de teclas de acceso rápido), el texto transcrito se envía al portapapeles (no la selección primaria) debajo, ya sea X11 o Wayland. Luego, el pastoreo ocurre con el CTRL+V ( CTRL+SHIFT+V para el terminal GNOME) o SHIFT+INSert teclas como de costumbre. (Para la mayoría de las personas, las teclas de acceso rápido de mano derecha funcionarían bien).
Si se transcribe a través de la red con wsi -n (seleccionado con una tecla de acceso rápido propio), el script intentará enviar el audio grabado a un servidor Whisper.cpp en ejecución correctamente (en el LAN o localhost ). Luego recopilará la respuesta textual y la formateará para pegar con el CTRL+V ( CTRL+SHIFT+V para el terminal GNOME) o SHIFT+INSert Keys (para pegar con el botón del mouse medio use wsi -n -p en su lugar).
Si usa un whisperfile en lugar de, o además de un whisper compilado.cpp, invoca con wsi -w ... y el script usará el ejecutable realmente portátil preestablecido con el modelo de elección de la elección incrustado.
Para usuarios multilingües, además de las características de WSI, wsiml proporciona la capacidad de especificar un idioma, por ejemplo -l fr y la opción de traducirse al inglés con -t . En principio, el usuario puede asignar múltiples teclas de acceso rápido a los diversos idiomas que transcribe o traduce. Por ejemplo, se pueden establecer dos teclas de acceso rápido adicional, una para la transcripción y otra para traducir del francés asignando los comandos wsiml -l fr y wsiml -l fr -t correspondientemente.
Experimental: los usuarios pueden usar el blooper de script suministrado para la entrada de voz a texto automática continua (no es necesario presionar CTRL+V o hacer clic en el botón Medio del mouse). Esto se demuestra en el segundo video anterior. Tenga en cuenta que el portapapeles se usa de forma predeterminada, el texto se estará automáticamente debajo del teclado Carret, pero en principio la selección primaria se puede configurar en su lugar, se simulará un clic del botón medio del mouse y el texto pegado en la posición actual del puntero del mouse en el tiempo (algo arbitrario) del texto está disponible. Tenga en cuenta que esto se basa en la detección de silencio, que depende de su entorno físico. En entornos ruidosos, use la clave caliente para dejar de grabar.
No podemos elevar el umbral arbitrariamente porque, si uno baja constantemente su voz (desvanecimiento) al final del habla, puede cortarse si el umbral es alto. Búscalo en ese caso a unos %.
Es mejor tratar de hacer que el habla se distinguida del ruido por amplitud (hable claramente, cerca del micrófono), al tiempo que minimiza el ruido externo (ubicación protegida del micrófono, hardware de cancelación de ruido, etc.) con un buen nivel de señal de voz, el umbral puede ser más efectivo, ya que SNR (relación de voz a ruido :-) aumenta efectivamente.
Después de capturar el discurso, se pasará para transcribe (whisper.cpp) para el reconocimiento del habla. Esto sucederá más rápido que en tiempo real (especialmente con una CPU rápida o si su Instalación Whisper.CPP usa CUDA). Se puede ajustar el número de subprocesos de procesamiento utilizados agregando -tn a los parámetros de la línea de comando de Transcribe (por favor, consulte la documentación Whisper.cpp). Luego, el script analizará el texto para eliminar los artefactos sin voz, los formateará y lo enviará a la selección primaria (portapapeles) utilizando herramientas X11 o Wayland.
En principio, Whisper (Whisper.cpp) es multilingüe y con el archivo de modelo correcto, esta aplicación emitirá el texto UTF-8 transcrito en el idioma correcto. El script wsiml está dedicado al uso multilingüe y con él el usuario puede elegir el idioma para la entrada del habla (usando el indicador -l LC donde LC es el código de idioma) y también puede traducir el habla en el idioma de entrada elegido al inglés con el indicador -t . El usuario puede asignar múltiples teclas de acceso rápido a los diversos idiomas que desea transcribir o traducir. Por ejemplo, se pueden establecer dos teclas de acceso rápido adicional, una para la transcripción y otra para traducir del francés asignando los comandos wsiml -l fr y wsiml -l fr -t correspondientemente.
Tenga en cuenta que al usar el modo de servidor, ahora tiene 2 opciones. Puede tener el servidor Whisper.cpp Precompiled o el Whisperfile descargado (en modo servidor) escuchar en el número de host y de puerto preconfigurado. El script del orquestador se acerca a ellos de la misma manera.
La transcripción de voz a texto es tarea intensiva en memoria y CPU y el almacenamiento rápido para el acceso a lectura y escritura solo puede ayudar. Es por eso que WSI almacena archivos temporales y de recursos en la memoria, para la velocidad y para reducir SSD/HDD "Grinding": TEMPD='/dev/shm' . Este punto de montaje de tipo "TMPFS" se crea en RAM (supongamos que tiene suficiente, por ejemplo, al menos 8GB) y está disponible por el kernel para aplicaciones de espacio de usuario. Cuando se apaga la computadora, se anote automáticamente, lo cual está bien ya que no necesitamos los archivos intermedios. De hecho, para algunos tipos de aplicaciones (mirándolo), sería beneficioso (en mi humilde opinión) que el punto de montaje del sistema /TMP también se mantenga en RAM. Mover /TMP a RAM puede acelerar un poco el inicio de la aplicación. Una aceleración de bienvenida para cualquier aplicación de electrones. En su forma más simple, esta transición es fácil, solo ejecuta:
echo "tmpfs /tmp tmpfs rw,nosuid,nodev" | sudo tee -a /etc/fstab y luego reinicie su computadora Linux. Por las razones antes mencionadas, especialmente si HDD es el principal medio de almacenamiento, uno también puede mover los archivos del modelo ASR necesarios por Whisper.cpp en la misma ubicación (/dev/shm). Estos son archivos grandes, que se pueden transferir a esta ubicación al comienzo de una sesión de terminal (o al inicio del sistema). Esto se puede hacer usando su archivo .profile colocando algo como esto en él:
([ -f /dev/shm/ggml-base.en.bin ] || cp /path/to/your/local/whisper.cpp/models/ggml* /dev/shm/)


