BlahST
Multilingual BlahST
Blah s peech-to- t ext-ext que vous avez un Bla (h) striant le texte de la parole sur Linux, avec des raccourcis clavier et Whisper.cpp. Allumez votre microphone et effectuez une reconnaissance vocale multilingue de haute qualité hors ligne. Étendue avec les LLM locales, il devient un puissant outil pour converser avec votre ordinateur Linux.
Blahst est probablement l'outil d'entrée de la parole à whisper le plus maigre pour Linux, assis au-dessus de Whisper.cpp.
wsiml dédiéEn utilisant des outils de ligne de commande optimisés à faible ressource, l'entrée du texte parlé se produit très rapidement. Voici une vidéo de démonstration (s'il vous plaît, réactiver l'audio) avec certaines fonctionnalités LLM locales (assistant AI, traducteur, planificateur, guide CLI en étape de test):
Dans la vidéo ci-dessus, l'audio commence par le système anormant le screencasting (mon gnome d'extension "voluble" parle de toutes les notifications de bureau GNOME), suivie de plusieurs tours d'entrée / reconnaissance de la parole. Il est démontré à la fin de l'une des "fonctions AI" qui utilise le texte transcrit par Blahst (Whisper.CPP), le formate en une invite LLM et l'envoie à un LLM multilingue local (Llama.cpp ou Llafile) qui renvoie la traduction chinoise en tant que texte et le parle également en utilisant un TTs neural. L'orchestrer à partir de la ligne de commande avec des exécutables Lean laisse le système étonnamment accrocheur (à partir de la vidéo, vous pouvez voir que le PC casse à peine n'importe quelle sueur - les températures restent faibles.)
La vidéo ci-dessus (réactivité s'il vous plaît) démontre l'utilisation de Blooper, modifiée à partir de WSI pour transcrire dans une boucle, jusqu'à ce que l'utilisateur met fin à l'entrée de la parole avec une pause plus longue (~ 3sec comme préréglé). Avec l'utilisation de XDOTOOL (ou YDOTOOL pour les utilisateurs de Wayland), le texte est collé automatiquement sur toute pause (ou sur l'interuption de la hottesrie). Pour la vidéo ci-dessus, la parole est générée avec une voix synthétique et collectée par le microphone. Cela me permet de modifier le texte simultanément (multitâches, n'essayez pas cela à la maison :). À la fin, l'icône de microphone supérieur devrait disparaître, indiquant la sortie du programme. Cela ne se produit pas dans la vidéo car le service d'écran de screencast a également une réclamation sur l'icône.
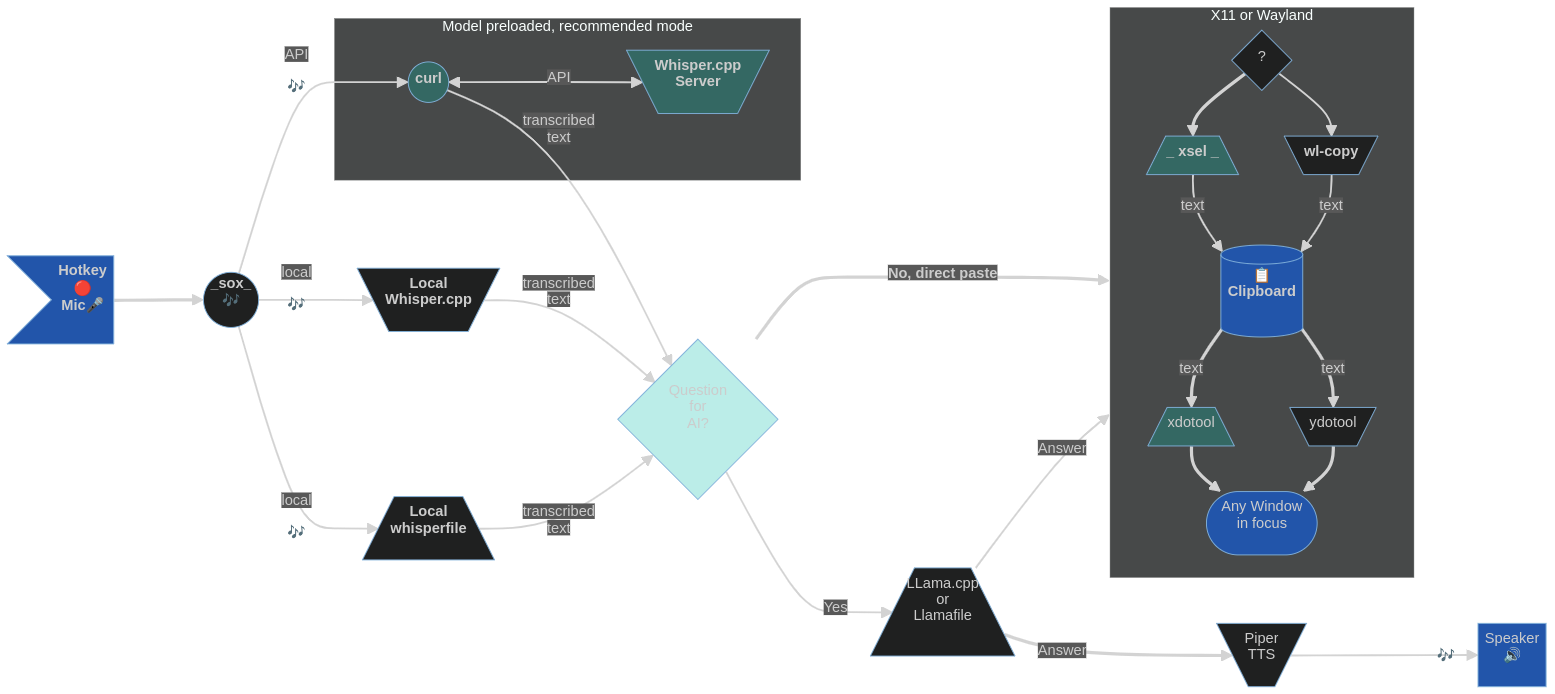
L'idée avec Blahst est d'être l'équivalent logiciel sans interface utilisateur d'un raid mongol; Éclatement court et puissant d'action CPU / GPU, puis il a complètement disparu, avec seulement des traces textuelles dans le presse-papiers et la paix relative de bureau. Utilisez simplement une paire de raccourcis clavier pour démarrer et arrêter l'enregistrement du microphone et envoyer le discours enregistré pour chuchoter.cpp [serveur] qui vide du texte transcrit dans le presse-papiers (sauf si vous le transmettez par un LLM local avant cela). Une approche universelle qui devrait fonctionner dans la plupart des environnements et distributions de bureau Linux.
Le travail est effectué par l'un des scripts:
La reconnaissance vocale est effectuée par Whisper.cpp qui doit être précompilée sur votre système Linux ou disponible sous forme d'instance de serveur sur votre LAN ou localhost. Alternativement, vous pouvez choisir de simplement télécharger et utiliser un exécutable réellement portable (avec un modèle de chuchotement intégré) Whisperfile, qui fait maintenant partie du référentiel de Llafile.
Lorsque l'entrée de la parole est lancée avec une touche de fortune, un indicateur de microphone apparaît dans la barre supérieure (au moins dans GNOME) et est montré pour la durée de l'enregistrement (peut être interrompu avec une autre cure de pavillon). La disparition de l'icône de microphone de la barre supérieure indique l'achèvement et le texte transcrit peut être collé à partir du presse-papiers. Sur les systèmes plus lents, il peut y avoir un léger retard après la disparition de l'icône de microphone et avant que le texte n'atteigne le presse-papiers en raison d'un temps de transcription plus long. Sur mon ordinateur, via l'API du serveur Whisper.cpp, il est inférieur à 150 ms (300 ms avec Whisper.CPP local) pour un paragraphe moyen de texte parlé.
Pour le fonctionnement uniquement du clavier, avec le CTRL+V standard par exemple, le presse-papiers standard sera utilisé sous X11 et Wayland ( wsi ou wsiml ), tandis que wsi -p (ou wsiml -p ) utilise la vente primaire et le texte est collé avec le bouton de la souris intermédiaire). Pour la pâte de main gauche, l'enregistrement de la parole peut être relégué aux raccourcis clavier déclenchés avec la main droite. ** Par exemple, j'ai configuré les touches "+" (démarrer l'enregistrement) et "insérer" (arrêter l'enregistrement) sur le clavier numérique.
install-wsi gère la plupart d'entre eux).Avertissement: L'auteur ne prend ni crédit ni assume aucune responsabilité pour tout résultat qui peut ou non résulter de l'interaction avec le contenu de ce document. Les actions et les automatisations proposées (par exemple, les lieux d'installation, etc.) ne sont que des suggestions et ne sont pas basées sur le choix et l'opinion de l'auteur. Comme ils peuvent ne pas correspondre au goût ou à la situation particulière de tout le monde, s'il vous plaît, ajustez-la au besoin.
Dans un dossier de votre choix, clonez le référentiel Blahst, puis choisissez une méthode d'installation ci-dessous:
git clone https://github.com/QuantiusBenignus/BlahST.git
cd ./BlahST
(En supposant que Whisper.cpp est installé et l'exécutable "principal" compilé avec «Make» dans le repo Cloned Whisper.cpp. Voir la section préalable)
cd $HOME/.local/bin; chmod +x wsi wsiAI wsiml
$HOME/.local/bin/ (partie de votre $ Path) avec ln -s /full/path/to/whisper.cpp/main $HOME/.local/bin/transcribe
Si Transcribe n'est pas dans votre chemin $, modifiez l'appel dans WSI pour inclure le chemin absolu, ou ajoutez son emplacement à la variable de chemin $. Sinon, le script échouera. Si vous préférez ne pas compiler Whisper.cpp, ou en plus de cela, téléchargez et définissez l'indicateur exécutable d'un whisperfile approprié, par exemple:
cd $HOME/.local/bin
wget https://huggingface.co/Mozilla/whisperfile/resolve/main/whisper-tiny.en.llamafile
chmod +x whisper-tiny.en.llamafile
À l'intérieur du script wsi , wsiAI , wsiml ou blooper , près du début, il existe une section clairement marquée, nommée "Block de configuration utilisateur" , où toutes les variables configurables de l'utilisateur ont été collectées. La plupart peuvent être laissés tels quels, mais les importants sont l'emplacement des fichiers de modèle (Whisper, LLM, TTS) que vous souhaitez utiliser pendant la transcription (ou le numéro IP et le port pour le serveur Whisper.cpp). Si vous utilisez un Whisperfile, s'il vous plaît, définissez la variable Whisperfile sur le nom de fichier de l'exécutable Whisperfile précédemment téléchargé, c'est-à-dire WHISPERFILE=whisper-tiny.en.llamafile (doit être sur le chemin $).
Pour démarrer et arrêter l'entrée de la parole, pour l'installation manuelle et automatique
/home/yourusername/.local/bin/wsi -p pour utiliser le bouton de la souris moyenne ou le modifier en .../wsi pour utiliser le presse-papiers.wsi ci-dessus par wsiml et si vous utilisez un whisperfile, ajoutez l'indicateur -w , c'est-à-dire /home/yourusername/.local/bin/wsi -w ). Enfin, pour goûter les fonctions LLM, remplacez wsi par wsiAI .Le script d'orchestrateur a un filtre de détection de silence dans l'appel à Sox (REC) et arrêterait d'enregistrer (dans le meilleur cas) sur 2 secondes de silence. De plus, si l'on ne veut pas attendre ou a des problèmes avec le seuil de détection de silence:
Pour ceux qui veulent être en mesure d'interrompre l'enregistrement manuellement avec une combinaison clé, dans l'esprit de grands hacks, nous allons utiliser les fonctionnalités intégrées du système:
pkill --signal 2 recAussi simple. Assurez-vous simplement que la nouvelle liaison clé n'a pas déjà été configurée pour autre chose. Maintenant, lorsque le script enregistre le discours, il peut être arrêté avec le nouveau combo clé et la transcription commencera immédiatement.
/home/yourusername/.local/bin/wsi -p ou .../wsi pour utiliser le presse-papiers.wsi ci-dessus par wsiml et si vous utilisez un whisperfile, ajoutez l'indicateur -w , c'est-à-dire /home/yourusername/.local/bin/wsi -w ). Enfin, pour goûter les fonctions LLM, remplacez wsi par wsiAI .pkill --signal 2 rec ./home/yourusername/.local/bin/wsi ou .../wsi -pwsi ci-dessus par wsiml et si vous utilisez un whisperfile, ajoutez l'indicateur -w , c'est-à-dire /home/yourusername/.local/bin/wsi -w ). Enfin, pour goûter les fonctions LLM, remplacez wsi par wsiAI .pkill --signal 2 rec .Veuillez noter qu'il peut y avoir de légères variations dans les étapes ci-dessus en fonction de la version installée sur votre système. Pour de nombreux autres environnements, tels que Mate, Cinnamon, LXQT, Deepin , etc. Les étapes doivent être quelque peu similaires aux exemples ci-dessus. Veuillez consulter la documentation de votre environnement de bureau Systems.
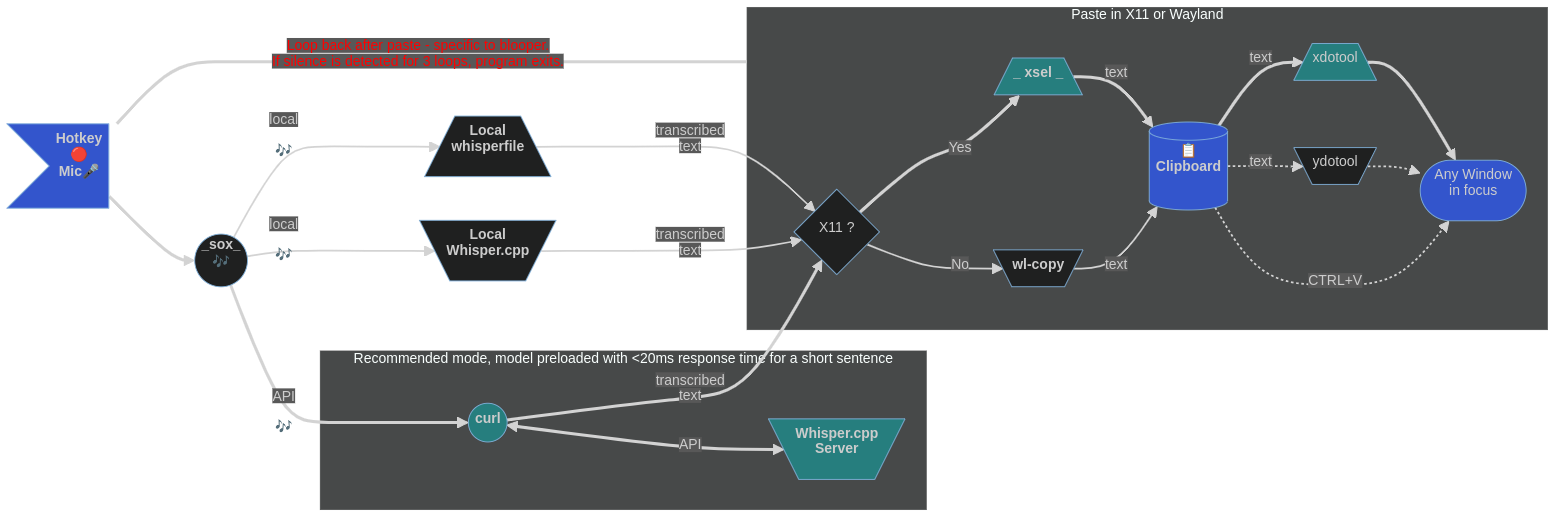
En appuyant sur un combo de hot-clé, le script wsi -p enregistrera la parole (arrêtée avec une cure de poule réduite ou par détection de silence), utilisez une copie locale de Whisper.cpp et envoyez le texte transcrit à la sélection primaire sous, soit x11 ou wayland. Ensuite, tout ce que l'on a à faire est de le coller avec le bouton Middle Mouse où ils le souhaitent. (Pour les personnes qui tiennent la souris avec leur main droite, le discours enregistrant des raccourcis clavier pour la main gauche aurait du sens.)
Si vous utilisez wsi sans drapeaux (les approches peuvent coexister, il suffit de configurer différents ensembles de raccourcis clavier), le texte transcrit est envoyé au presse-papiers (pas la sélection primaire) sous, soit x11 ou wayland. Le collage se produit ensuite avec le CTRL+V ( CTRL+SHIFT+V pour la borne GNOME) ou les touches SHIFT+INSert comme d'habitude. (Pour la plupart des gens, les raccourcis de droite fonctionneraient bien.)
Si vous transcrivez sur le réseau avec wsi -n (sélectionné avec une touche de putain de son propre), le script tentera d'envoyer l'audio enregistré dans un serveur Whisper.cpp correctement en cours d'exécution (sur le LAN ou localhost ). Il collectera ensuite la réponse textuelle et le formatera pour coller avec le CTRL+V ( CTRL+SHIFT+V pour GNOME Terminal) ou SHIFT+INSert des touches (pour coller avec le bouton de souris moyen Utilisez wsi -n -p à la place).
Si vous utilisez un whisperfile au lieu de, ou en plus d'un Whisper.CPP compilé, invoquez avec wsi -w ... et le script utilisera le préréglage réellement portable avec le modèle Whisper embarqué de choix de choix.
Pour les utilisateurs multilingues, en plus des fonctionnalités de WSI, wsiml offre la possibilité de spécifier une langue, par -l fr et l'option de traduire en anglais avec -t . L'utilisateur peut en principe attribuer plusieurs raccourcis clavier aux différentes langues dont il transcrit ou traduire. Par exemple, deux raccourcis clavier supplémentaires peuvent être définis, l'un pour la transcription et un autre pour la traduction de French en attribuant les commandes wsiml -l fr et wsiml -l fr -t en conséquence.
Expérimental: les utilisateurs peuvent utiliser le Blooper de script fourni pour une entrée automatique parole automatique à texte (pas besoin d'appuyer sur Ctrl + V ou cliquez sur le bouton de la souris moyenne.) Ceci est démontré dans la deuxième vidéo ci-dessus. Veuillez noter que le presse-papiers est utilisé par défaut, le texte sera automatiquement sous la carret de clavier, mais en principe, la sélection principale peut être configurée à la place, un clic de la souris du milieu sera simulé et le texte collé à la position actuelle du pointeur de la souris au moment (quelque peu arbitraire) du texte. Veuillez noter que cela repose sur la détection du silence, qui dépend de votre environnement physique. Dans les environnements bruyants, utilisez la touche de chaleur pour arrêter l'enregistrement.
Nous ne pouvons pas augmenter le seuil arbitrairement parce que, si l'on abaisse constamment leur voix (Fadeout) à la fin du discours, cela peut être coupé si le seuil est élevé. Abaissez-le dans ce cas à quelques%.
Il est préférable d'essayer de faire en sorte que la parole se distingue du bruit par amplitude (parlez clairement, près du microphone), tout en minimisant le bruit externe (emplacement abrité du microphone, matériel d'annulation du bruit, etc.) avec un bon niveau de signal de parole, le seuil peut ensuite être augmenté.
Une fois le discours capturé, il sera transmis pour transcribe (whisper.cpp) pour la reconnaissance vocale. Cela se produira plus rapidement que le temps réel (en particulier avec un CPU rapide ou si votre installation Whisper.cpp utilise CUDA). On peut ajuster le nombre de threads de traitement utilisés en ajoutant -tn aux paramètres de ligne de commande de transcribe (s'il vous plaît, voir Whisper.cpp Documentation). Le script analysera ensuite le texte pour supprimer les artefacts de non-discours, le formater et l'envoyer à la sélection principale (presse-papiers) à l'aide d'outils X11 ou Wayland.
En principe, Whisper (Whisper.cpp) est multilingue et avec le fichier de modèle correct, cette application sortira le texte UTF-8 transcrit dans la langue correcte. Le script wsiml est dédié à une utilisation multilingue et avec lui, l'utilisateur est capable de choisir la langue pour la saisie de la parole (en utilisant l'indicateur -l LC où LC est le code de la langue) et peut également traduire le discours dans la langue d'entrée choisie en anglais avec l'indicateur -t . L'utilisateur peut attribuer plusieurs raccourcis clavier aux différentes langues dont il souhaite transcrire ou traduire. Par exemple, deux raccourcis clavier supplémentaires peuvent être définis, l'un pour la transcription et un autre pour la traduction de French en attribuant les commandes wsiml -l fr et wsiml -l fr -t en conséquence.
Veuillez noter que lorsque vous utilisez le mode serveur, vous avez maintenant 2 choix. Vous pouvez avoir le serveur Whisper.CPP précompilé ou le Whisperfile téléchargé (en mode serveur) écouter l'hôte et le numéro de port préconfigurés. Le script d'orchestrateur les aborde de la même manière.
La transcription de la parole en texte est la tâche à forte intensité de mémoire et de processeur et le stockage rapide pour l'accès à la lecture et à l'écriture ne peut que vous aider. C'est pourquoi WSI stocke les fichiers temporaires et de ressources en mémoire, pour la vitesse et pour réduire le SSD / HDD "broyage": TEMPD='/dev/shm' . Ce point de montage de type "TMPFS" est créé dans RAM (supposons que vous en avez assez, par exemple, au moins 8 Go) et est mis à disposition par le noyau pour les applications d'espace utilisateur. Lorsque l'ordinateur est arrêté, il est automatiquement anéanti, ce qui est bien car nous n'avons pas besoin des fichiers intermédiaires. En fait, pour certains types d'applications (en vous regardant électron), il serait avantageux (IMHO) d'avoir le point de montage à l'échelle du système / TMP également conservé en RAM. Le déplacement / TMP vers RAM peut accélérer un peu le démarrage de l'application. Une accélération de bienvenue pour toute application électronique. Dans sa forme la plus simple, cette transition est facile, il suffit de courir:
echo "tmpfs /tmp tmpfs rw,nosuid,nodev" | sudo tee -a /etc/fstab , puis redémarrez votre ordinateur Linux. Pour les raisons susmentionnées, surtout si le disque dur est le principal support de stockage, on peut également déplacer les fichiers du modèle ASR nécessaires à Whisper.cpp au même emplacement (/ dev / shm). Ce sont des fichiers grands, qui peuvent être transférés à cet emplacement au début d'une session terminale (ou au démarrage du système). Cela peut être fait en utilisant votre fichier .profile en plaçant quelque chose comme ça:
([ -f /dev/shm/ggml-base.en.bin ] || cp /path/to/your/local/whisper.cpp/models/ggml* /dev/shm/)


