pytorch metric learning
v2.8.1

11 de dezembro : v2.8.0
2 de novembro : v2.7.0
Consulte a pasta Exemplos para notebooks que você pode baixar ou executar no Google Colab.
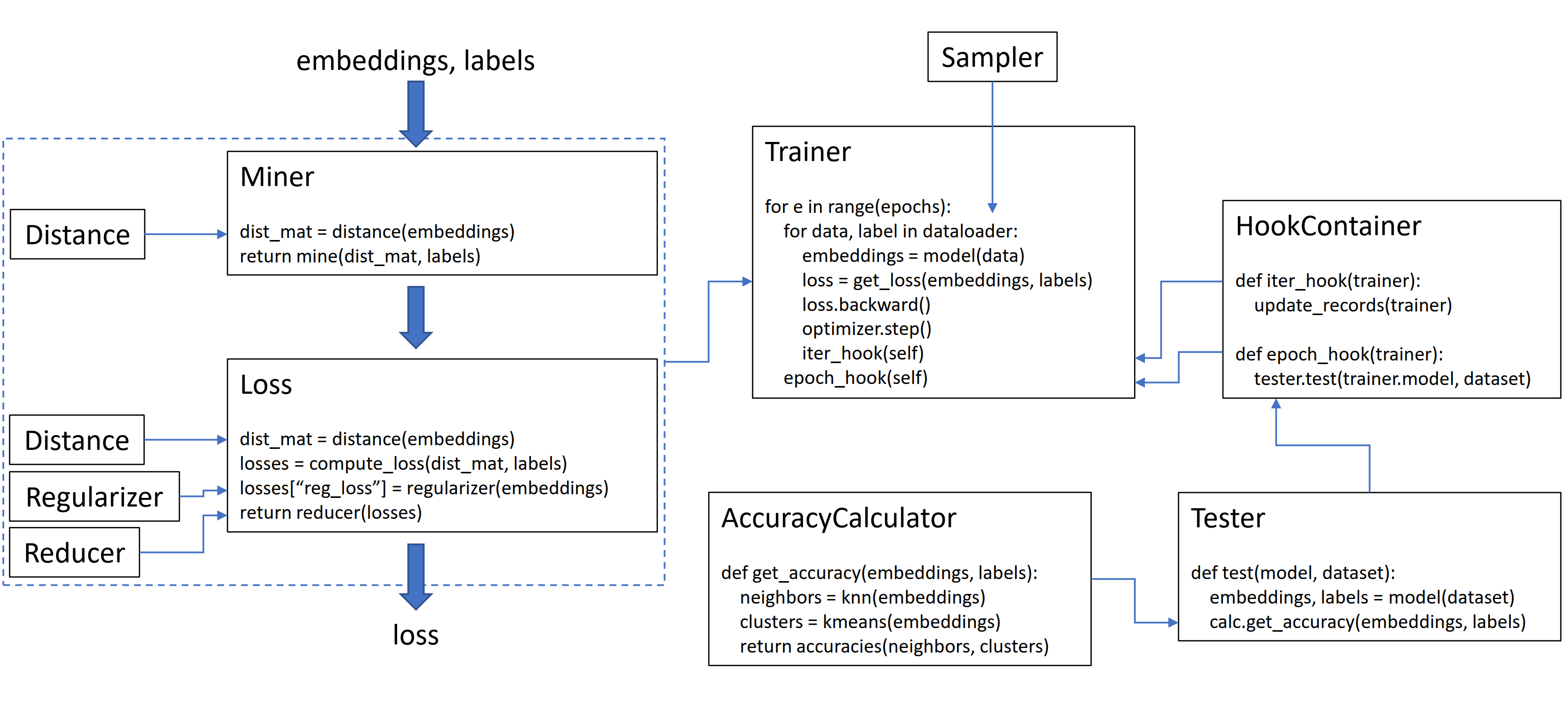
Esta biblioteca contém 9 módulos, cada um dos quais pode ser usado de forma independente na sua base de código existente ou combinada para um fluxo de trabalho completo de trem/teste.
Vamos inicializar um tripletmarginloss simples:
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ()Para calcular a perda em seu loop de treinamento, passe nas incorporações calculadas pelo seu modelo e pelos rótulos correspondentes. As incorporações devem ter tamanho (n, incorporar_size) e os rótulos devem ter tamanho (n), onde n é o tamanho do lote.
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
loss = loss_func ( embeddings , labels )
loss . backward ()
optimizer . step ()O tripletmarginloss calcula todos os trigêmeos possíveis dentro do lote, com base nos rótulos que você passa para ele. Pares positivos para âncora são formados por incorporações que compartilham o mesmo rótulo, e os pares negativos da âncora são formados por incorporações que possuem rótulos diferentes.
Às vezes, pode ajudar a adicionar uma função de mineração:
from pytorch_metric_learning import miners , losses
miner = miners . MultiSimilarityMiner ()
loss_func = losses . TripletMarginLoss ()
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
hard_pairs = miner ( embeddings , labels )
loss = loss_func ( embeddings , labels , hard_pairs )
loss . backward ()
optimizer . step ()No código acima, o mineiro encontra pares positivos e negativos que acha particularmente difíceis. Observe que, embora o tripletmarginloss opere em trigêmeos, ainda é possível passar em pares. Isso ocorre porque a biblioteca converte automaticamente pares em trigêmeos e trigêmeos em pares, quando necessário.
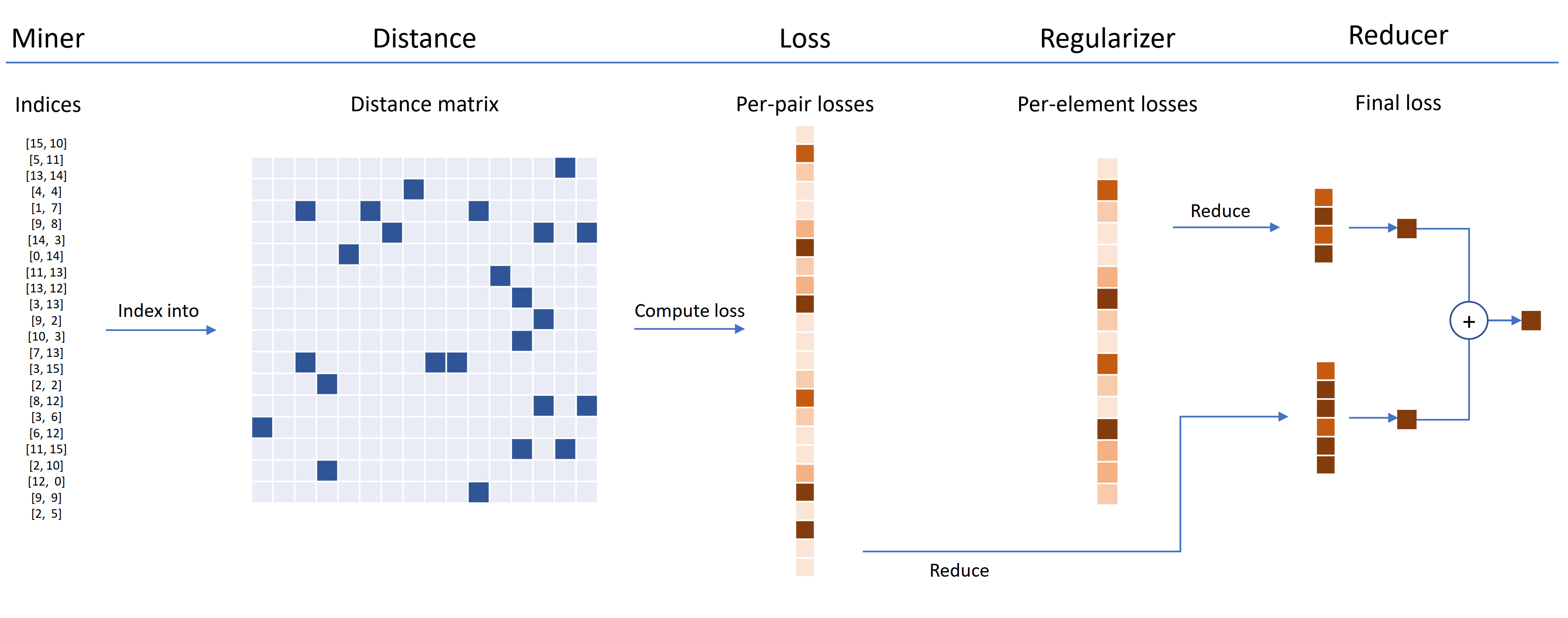
As funções de perda podem ser personalizadas usando distâncias, redutores e regularizadores. No diagrama abaixo, um mineiro encontra os índices de pares duros dentro de um lote. Eles são usados para indexar na matriz de distância, calculada pelo objeto de distância. Para este diagrama, a função de perda é baseada em pares, por isso calcula uma perda por par. Além disso, um regularizador foi fornecido, portanto, uma perda de regularização é calculada para cada incorporação no lote. As perdas por par e por elemento são passadas para o redutor, que (neste diagrama) mantém apenas perdas com um valor alto. As médias são calculadas para as perdas de par e elementos de alto valor e são adicionadas para obter a perda final.
Agora, aqui está um exemplo de um TripletMarginloss personalizado:
from pytorch_metric_learning . distances import CosineSimilarity
from pytorch_metric_learning . reducers import ThresholdReducer
from pytorch_metric_learning . regularizers import LpRegularizer
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ( distance = CosineSimilarity (),
reducer = ThresholdReducer ( high = 0.3 ),
embedding_regularizer = LpRegularizer ())Esta perda de trigêmeo personalizada tem as seguintes propriedades:
Um invólucro SelfSupervisedLoss é fornecido para o aprendizado auto-supervisionado:
from pytorch_metric_learning . losses import SelfSupervisedLoss
loss_func = SelfSupervisedLoss ( TripletMarginLoss ())
# your training for-loop
for i , data in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = your_model ( data )
augmented = your_model ( your_augmentation ( data ))
loss = loss_func ( embeddings , augmented )
loss . backward ()
optimizer . step ()Se você estiver interessado na auto-supervisão do estilo MOCO, dê uma olhada no MOCO no CIFAR10 Notebook. Ele usa o CrossBatchMemory para implementar a fila do codificador de momento, o que significa que você pode usar qualquer perda de tupla e qualquer mineiro de tupla para extrair amostras duras da fila.
Se você estiver com pouco tempo e deseja um fluxo de trabalho de trem/teste completo, consulte o exemplo do Google Colab Notebooks.
Para saber mais sobre tudo isso acima, consulte a documentação.
pytorch-metric-learning >= v0.9.90 requer torch >= 1.6pytorch-metric-learning < v0.9.90 não tem um requisito de versão, mas foi testado com torch >= 1.2 Outras dependências: numpy, scikit-learn, tqdm, torchvision
pip install pytorch-metric-learning
Para obter a versão mais recente de desenvolvimento :
pip install pytorch-metric-learning --pre
Para instalar no Windows :
pip install torch===1.6.0 torchvision===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-metric-learning
Para instalar com recursos de avaliação e log
(Isso instalará a versão Pypi não oficial da FAISS-GPU, mais o registro e o tensorboard):
pip install pytorch-metric-learning[with-hooks]
Para instalar com os recursos de avaliação e log (CPU)
(Isso instalará a versão PyPI não oficial do FAISS-CPU, mais o registro e o tensorboard):
pip install pytorch-metric-learning[with-hooks-cpu]
conda install -c conda-forge pytorch-metric-learning
Para usar o módulo de teste, você precisará de FAISS, que também pode ser instalado via CONDA. Veja as instruções de instalação para o FAISS.
Consulte o poderoso benchmarker para visualizar os resultados da referência e usar a ferramenta de benchmarking.
O desenvolvimento é feito na filial dev :
git checkout dev
Os testes de unidade podem ser executados com a Biblioteca Padrão unittest :
python -m unittest discoverVocê pode especificar os tipos de dados de teste e o dispositivo de teste como variáveis de ambiente. Por exemplo, para testar usando o float32 e o float64 na CPU:
TEST_DTYPES=float32,float64 TEST_DEVICE=cpu python -m unittest discoverPara executar um único arquivo de teste em vez de todo o conjunto de testes, especifique o nome do arquivo:
python -m unittest tests/losses/test_angular_loss.py O código é formatado usando black e isort :
pip install black isort
./format_code.shObrigado aos colaboradores que fizeram pedidos de puxar!
| Contribuinte | Destaques |
|---|---|
| Domenicomuscill0 | - Moltíssimo - P2SGradLoss - Histogramloss - DynamicSoftMarginloss - Lista de classificação |
| mlopezantequa | - fez os testadores funcionarem em qualquer combinação de consultas e conjuntos de referência - Fez a precisão de que a precisão trabalhasse com comparações de etiquetas arbitrárias |
| cwkeam | - Selfsupervisedloss - Vicregloss - Adicionada precisão de classificação recíproca média ao precisão - Baselosswrapper |
| IR2718 | - limholdConsistentMarginloss - O módulo de dados |
| Marijnl | - Batcheasyhardminer - twostreammetricloss - GlobalTwostreamEmbeddingspacetester - Exemplo usando os treinadores.TWOSTREAMMETRICLOSS |
| Chingisooinar | Subcentercfaceloss |
| Elias-Ramzi | Hierárquico -amostrador |
| fjsj | SupConloss |
| Alenubuntu | Circleloss |
| Interessantezhuo | PnPloss |
| WConnell | Aprendendo uma incorporação métrica scrnaseq |
| Mkmenta | get_all_triplets_indices aprimorados (corrigiu o erro INT_MAX ) |
| Alexschuy | utils.loss_and_miner_utils.get_random_triplet_indices |
| JohnGiorgi | all_gather em utils.distribued |
| Hummer12007 | utils.key_checker |
| Vltanh | Made InferenceModel.train_indexer Aceite conjuntos de dados |
| Btseytlin | get_nearest_neighbors em inferncerodel |
| MLW214 | Adicionado return_per_class ao precuraccalculator |
| Layumi | Instanceloss |
| Notody | Ajudou a adicionar ref_emb e ref_labels aos invólucros distribuídos. |
| Elisonsherton | Corrigido uma caixa de borda em Arcfaceloss. |
| Stompsjo | Documentação aprimorada para ntxentloss. |
| Puzer | Correção de bugs para pnPloss. |
| Elisim | Melhorias do desenvolvedor no DistributedLossWrapper. |
| GaetanLepage | |
| Z1W | |
| ThinLine72 | |
| tpanum | |
| Fralik | |
| Joaqo | |
| Jookuma | |
| Gkouros | |
| Yutanakamura-Tky | |
| KingLittleq | |
| Martin0258 | |
| Michaeldeyzel | |
| Hsinger04 | |
| Rheum | |
| Bot66 |
Obrigado a Ser-Nam Lim na AI do Facebook e meu consultor de pesquisa, o professor Serge pertence. Esse projeto começou durante o meu estágio na IA do Facebook, onde recebi feedback valioso de Ser-nam e sua equipe de engenheiros de visão computacional e engenheiros de aprendizado de máquina e cientistas de pesquisa. Em particular, graças a Ashish Shah e Austin Reiter por revisar meu código durante seus estágios iniciais de desenvolvimento.
Esta biblioteca contém código que foi adaptado e modificado dos seguintes grandes repositórios de código aberto:
Agradeço a Jeff Musgrave por projetar o logotipo.
Se você quiser citar o pytorch-Metric-Learning em seu trabalho, você pode usar este Bibtex:
@article{Musgrave2020PyTorchML,
title={PyTorch Metric Learning},
author={Kevin Musgrave and Serge J. Belongie and Ser-Nam Lim},
journal={ArXiv},
year={2020},
volume={abs/2008.09164}
}

