pytorch metric learning
v2.8.1

11 de diciembre : v2.8.0
2 de noviembre : v2.7.0
Vea la carpeta de ejemplos para los cuadernos que puede descargar o ejecutar en Google Colab.
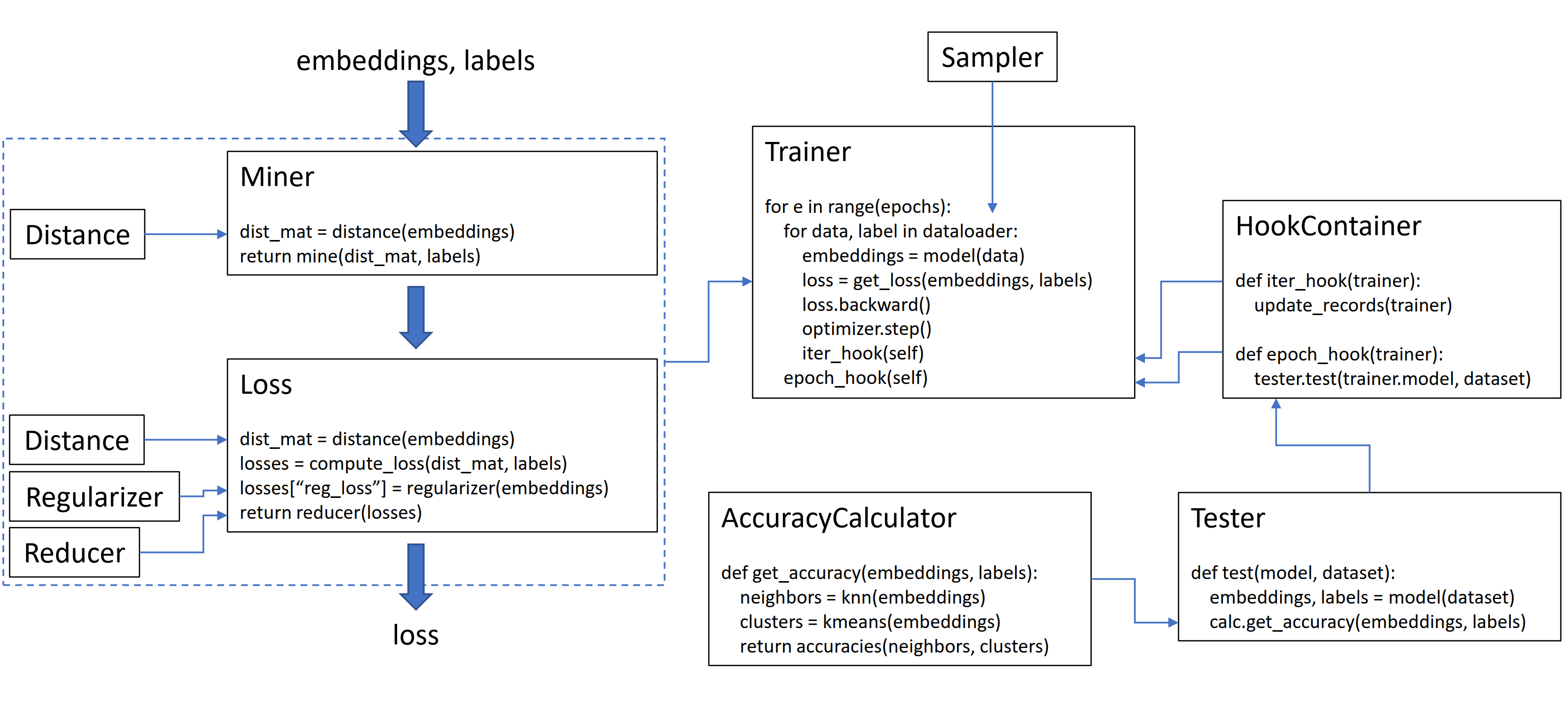
Esta biblioteca contiene 9 módulos, cada uno de los cuales se puede usar de forma independiente dentro de su base de código existente, o combinada para un flujo de trabajo completo de tren/prueba.
Inicialicemos un tripletmarginloss simple:
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ()Para calcular la pérdida en su bucle de entrenamiento, pase en los incrustaciones calculadas por su modelo y las etiquetas correspondientes. Los incrustaciones deben tener tamaño (n, incrustar_size), y las etiquetas deben tener tamaño (n), donde n es el tamaño del lote.
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
loss = loss_func ( embeddings , labels )
loss . backward ()
optimizer . step ()El tripletmarginloss calcula todos los tripletes posibles dentro del lote, según las etiquetas que le pasa. Los pares de anclaje positivos se forman mediante incrustaciones que comparten la misma etiqueta, y los pares de anclaje negativos se forman mediante incrustaciones que tienen etiquetas diferentes.
A veces puede ayudar a agregar una función minera:
from pytorch_metric_learning import miners , losses
miner = miners . MultiSimilarityMiner ()
loss_func = losses . TripletMarginLoss ()
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
hard_pairs = miner ( embeddings , labels )
loss = loss_func ( embeddings , labels , hard_pairs )
loss . backward ()
optimizer . step ()En el código anterior, el minero encuentra pares positivos y negativos que cree que son particularmente difíciles. Tenga en cuenta que a pesar de que el tripletmarginloss funciona en trillizos, todavía es posible pasar en parejas. Esto se debe a que la biblioteca convierte automáticamente pares en trillizos y trillizos a parejas, cuando sea necesario.
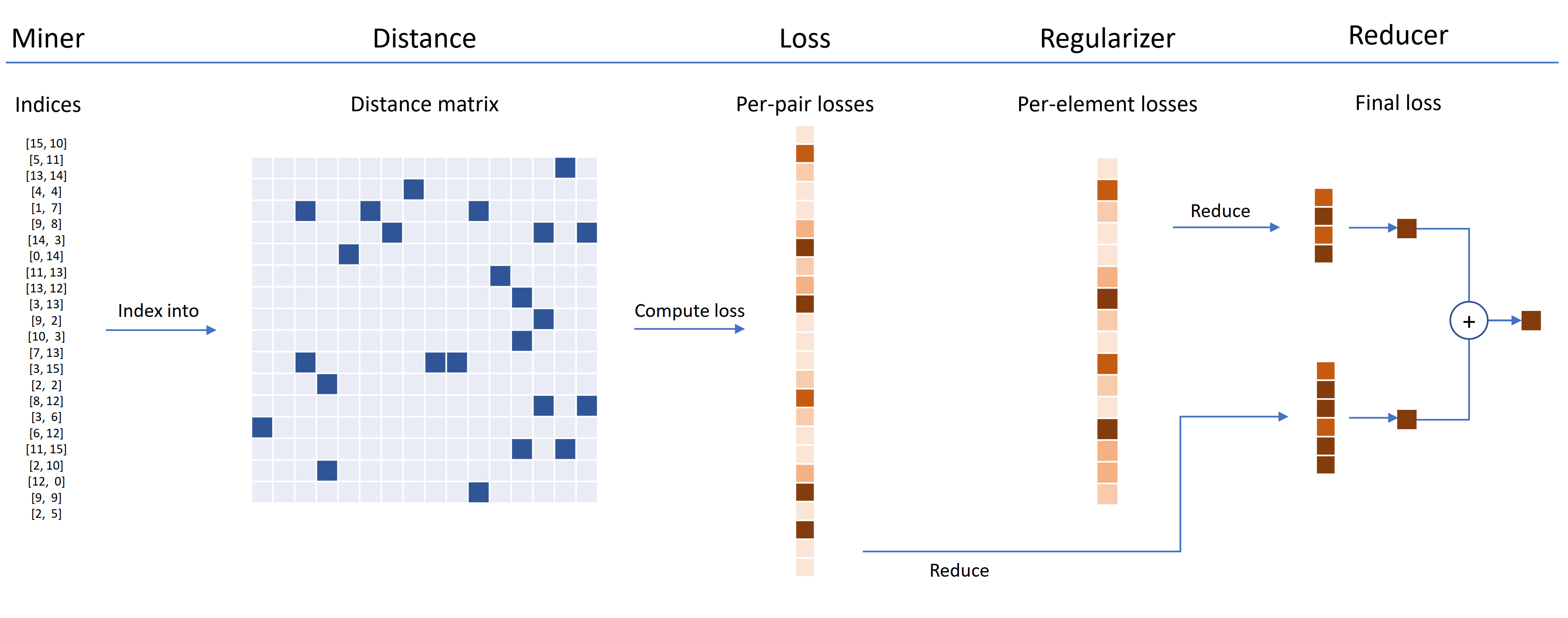
Las funciones de pérdida se pueden personalizar utilizando distancias, reductores y regularidades. En el diagrama a continuación, un minero encuentra los índices de pares duros dentro de un lote. Estos se utilizan para indexar en la matriz de distancia, calculada por el objeto de distancia. Para este diagrama, la función de pérdida está basada en pares, por lo que calcula una pérdida por par. Además, se ha suministrado un regularizador, por lo que se calcula una pérdida de regularización para cada incrustación en el lote. Las pérdidas por par y por elemento se pasan al reductor, que (en este diagrama) solo mantiene las pérdidas con un valor alto. Los promedios se calculan para las pérdidas de pares y elementos de alto valor, y luego se suman para obtener la pérdida final.
Ahora aquí hay un ejemplo de un tripletmarginloss personalizado:
from pytorch_metric_learning . distances import CosineSimilarity
from pytorch_metric_learning . reducers import ThresholdReducer
from pytorch_metric_learning . regularizers import LpRegularizer
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ( distance = CosineSimilarity (),
reducer = ThresholdReducer ( high = 0.3 ),
embedding_regularizer = LpRegularizer ())Esta pérdida de triplete personalizada tiene las siguientes propiedades:
Se proporciona un envoltorio SelfSupervisedLoss para el aprendizaje auto-supervisado:
from pytorch_metric_learning . losses import SelfSupervisedLoss
loss_func = SelfSupervisedLoss ( TripletMarginLoss ())
# your training for-loop
for i , data in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = your_model ( data )
augmented = your_model ( your_augmentation ( data ))
loss = loss_func ( embeddings , augmented )
loss . backward ()
optimizer . step ()Si está interesado en la auto-supervisión al estilo MOCO, eche un vistazo al Moco en el cuaderno CIFAR10. Utiliza CrossBatchMemory para implementar la cola del codificador de impulso, lo que significa que puede usar cualquier pérdida de tupla y cualquier minero de tuple para extraer muestras duras de la cola.
Si tiene poco tiempo y desea un flujo de trabajo completo de tren/prueba, consulte el ejemplo de los cuadernos de Google Colab.
Para obtener más información sobre todo lo anterior, consulte la documentación.
pytorch-metric-learning >= v0.9.90 requiere torch >= 1.6pytorch-metric-learning < v0.9.90 no tiene un requisito de versión, pero se probó con torch >= 1.2 Otras dependencias: numpy, scikit-learn, tqdm, torchvision
pip install pytorch-metric-learning
Para obtener la última versión de desarrollo :
pip install pytorch-metric-learning --pre
Para instalar en Windows :
pip install torch===1.6.0 torchvision===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-metric-learning
Instalar con capacidades de evaluación y registro
(Esto instalará la versión PYPI no oficial de Faiss-GPU, además de Registor-Keeper y TensorBoard):
pip install pytorch-metric-learning[with-hooks]
Instalar con capacidades de evaluación y registro (CPU)
(Esto instalará la versión PYPI no oficial de Faiss-CPU, además de Registor -keeper y Tensorboard):
pip install pytorch-metric-learning[with-hooks-cpu]
conda install -c conda-forge pytorch-metric-learning
Para usar el módulo de prueba, necesitará FAISS, que también se puede instalar a través de Conda. Consulte las instrucciones de instalación para FAISS.
Consulte Potency Benchmarker para ver los resultados de referencia y usar la herramienta de evaluación comparativa.
El desarrollo se realiza en la rama dev :
git checkout dev
Las pruebas unitarias se pueden ejecutar con la biblioteca unittest predeterminada:
python -m unittest discoverPuede especificar los tipos de datos de prueba y el dispositivo de prueba como variables de entorno. Por ejemplo, probar usando Float32 y Float64 en la CPU:
TEST_DTYPES=float32,float64 TEST_DEVICE=cpu python -m unittest discoverPara ejecutar un solo archivo de prueba en lugar de todo el conjunto de pruebas, especifique el nombre del archivo:
python -m unittest tests/losses/test_angular_loss.py El código está formateado usando black e isort :
pip install black isort
./format_code.sh¡Gracias a los contribuyentes que hicieron solicitudes de extracción!
| Contribuyente | Reflejos |
|---|---|
| domenicomususcill0 | - Manifoldloss - P2Sgradloss - HISTOGRAMLOSS - DynamicSoftMarginloss - rankedlistloss |
| mlopezantuquera | - Hizo que los probadores funcionen en cualquier combinación de consultas y conjuntos de referencia - Hizo que el precalculador se haya realizado con comparaciones de etiquetas arbitrarias |
| cwkeam | - SelfsupervisedLoss - Vicregloss - Se agregó precisión media de rango recíproco a la precisión de la precisión - BaselsossSwrapper |
| IR2718 | - umbralconsistentMarginloss - El módulo de conjuntos de datos |
| marijnl | - BatcheasyHardMiner - Twostreammetricloss - GlobalTwostreamEmbedDingsPacetester - Ejemplo usando entrenadores.TwostreamMetricLoss |
| chingisooinar | Subcentrarcfaceloss |
| Elias-Ramzi | Paramadera jerárquica |
| FJSJ | Suponloss |
| Alenubuntu | Círculo |
| interesantezhuo | Pnploss |
| wconnell | Aprender una incrustación métrica scrnaseq |
| mkmenta | get_all_triplets_indices mejorado (se corrigió el error INT_MAX ) |
| Alexschuy | utils.loss_and_miner_utils.get_random_triplet_indices |
| Johngiorgi | all_gather en utils.distributed |
| Hummer12007 | utils.key_checker |
| vltanh | Hecho InferenceModel.train_indexer aceptar conjuntos de datos |
| btseytlin | get_nearest_neighbors en inferencemodel |
| MLW214 | Se agregó return_per_class a accuracycalculator |
| Layumi | Instanceloss |
| Nota | Ayudó a agregar ref_emb y ref_labels a los envoltorios distribuidos. |
| Elisonsherton | Se corrigió una caja de borde en ArcFaceloss. |
| stompsjo | Documentación mejorada para NTXENTLOSS. |
| Puzer | Corrección de errores para pnploss. |
| Elisim | Mejoras del desarrollador a DistributedLossWrapper. |
| Gaetanlepage | |
| Z1W | |
| Tinline72 | |
| tpano | |
| fralik | |
| Joaqo | |
| Jookuma | |
| gkouros | |
| yutanakamura-tky | |
| KingLittleq | |
| Martin0258 | |
| Michaeldeyzel | |
| Hsinger04 | |
| reuma | |
| Bot66 |
Gracias a Ser-Nam Lim en Facebook AI, y mi asesor de investigación, Profesor Serge Pertenerie. Este proyecto comenzó durante mi pasantía en Facebook AI, donde recibí valiosos comentarios de SER-NAM, y su equipo de ingenieros de visión por computadora y aprendizaje automático y científicos de investigación. En particular, gracias a Ashish Shah y Austin Reiter por revisar mi código durante sus primeras etapas de desarrollo.
Esta biblioteca contiene un código que ha sido adaptado y modificado de los siguientes reposos de código abierto:
Gracias a Jeff Musgrave por diseñar el logotipo.
Si desea citar pytorch-metric-learning en su artículo, puede usar este bibtex:
@article{Musgrave2020PyTorchML,
title={PyTorch Metric Learning},
author={Kevin Musgrave and Serge J. Belongie and Ser-Nam Lim},
journal={ArXiv},
year={2020},
volume={abs/2008.09164}
}

