pytorch metric learning
v2.8.1

11 décembre : v2.8.0
2 novembre : v2.7.0
Voir le dossier Exemples pour les ordinateurs portables que vous pouvez télécharger ou exécuter sur Google Colab.
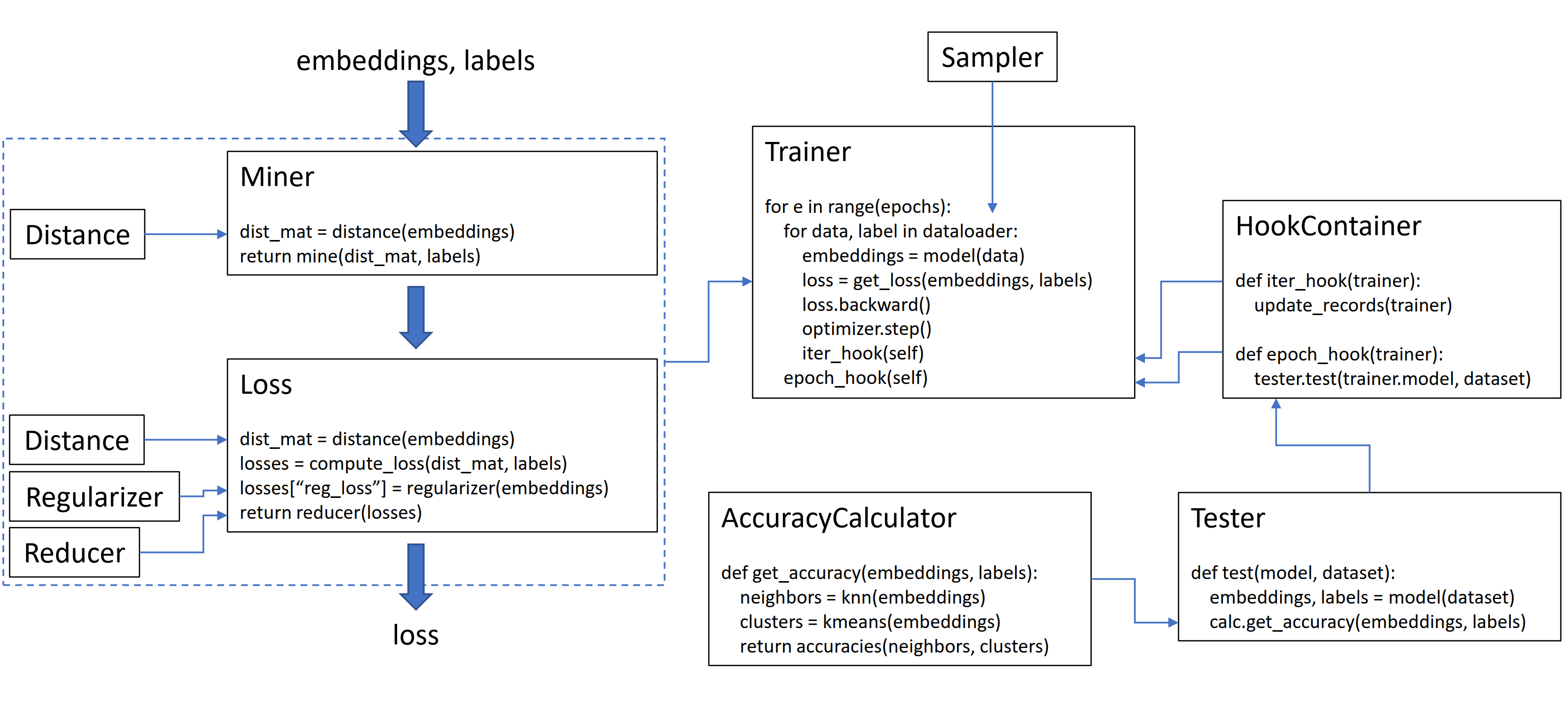
Cette bibliothèque contient 9 modules, dont chacun peut être utilisé indépendamment dans votre base de code existante, ou combinée ensemble pour un flux de travail de train / test complet.
Initialisons un simple tripletmarginloss:
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ()Pour calculer la perte dans votre boucle d'entraînement, passez dans les intérêts calculés par votre modèle et les étiquettes correspondantes. Les incorporations doivent avoir de la taille (n, embedding_size), et les étiquettes doivent avoir la taille (n), où n est la taille du lot.
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
loss = loss_func ( embeddings , labels )
loss . backward ()
optimizer . step ()Le tripletmarginloss calcule tous les triplets possibles dans le lot, en fonction des étiquettes que vous y transmettez. Les paires d'ancrage positives sont formées par des intégres qui partagent la même étiquette, et les paires d'ancrage négatives sont formées par des intérêts qui ont des étiquettes différentes.
Parfois, cela peut aider à ajouter une fonction minière:
from pytorch_metric_learning import miners , losses
miner = miners . MultiSimilarityMiner ()
loss_func = losses . TripletMarginLoss ()
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
hard_pairs = miner ( embeddings , labels )
loss = loss_func ( embeddings , labels , hard_pairs )
loss . backward ()
optimizer . step ()Dans le code ci-dessus, le mineur trouve des paires positives et négatives qui, selon eux, sont particulièrement difficiles. Notez que même si le tripletmarginloss fonctionne sur des triplés, il est toujours possible de passer par paires. En effet, la bibliothèque convertit automatiquement les paires en triplets et triplets en paires, si nécessaire.
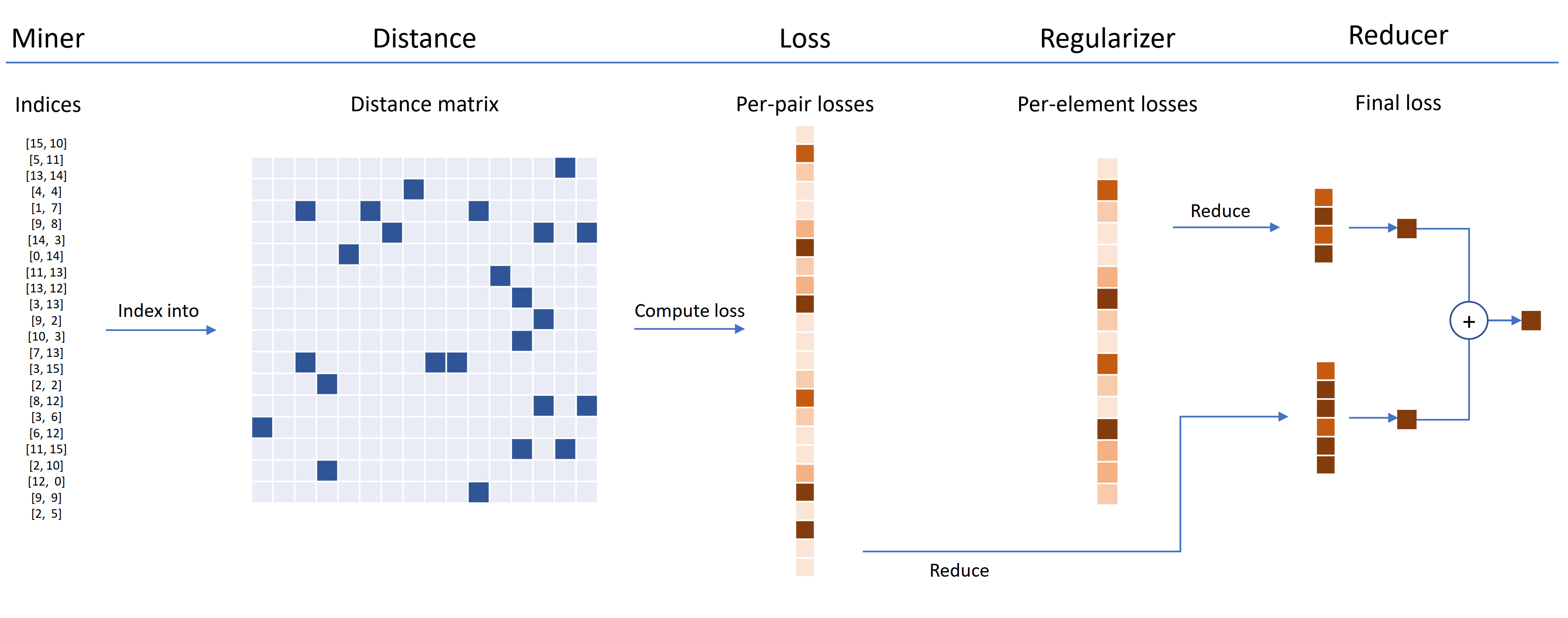
Les fonctions de perte peuvent être personnalisées à l'aide de distances, de réducteurs et de régulateurs. Dans le diagramme ci-dessous, un mineur trouve les indices de paires dures dans un lot. Ceux-ci sont utilisés pour indexer dans la matrice de distance, calculés par l'objet de distance. Pour ce diagramme, la fonction de perte est basée sur la paire, il calcule donc une perte par paire. De plus, un régulariseur a été fourni, donc une perte de régularisation est calculée pour chaque intégration dans le lot. Les pertes par paire et par éléments sont transmises au réducteur, qui (dans ce diagramme) ne conserve que des pertes avec une valeur élevée. Les moyennes sont calculées pour les pertes de paires et d'éléments à valeur élevée, puis sont additionnées pour obtenir la perte finale.
Voici maintenant un exemple de tripletmarginloss personnalisé:
from pytorch_metric_learning . distances import CosineSimilarity
from pytorch_metric_learning . reducers import ThresholdReducer
from pytorch_metric_learning . regularizers import LpRegularizer
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ( distance = CosineSimilarity (),
reducer = ThresholdReducer ( high = 0.3 ),
embedding_regularizer = LpRegularizer ())Cette perte de triplet personnalisée a les propriétés suivantes:
Un emballage SelfSupervisedLoss est fourni pour l'apprentissage auto-supervisé:
from pytorch_metric_learning . losses import SelfSupervisedLoss
loss_func = SelfSupervisedLoss ( TripletMarginLoss ())
# your training for-loop
for i , data in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = your_model ( data )
augmented = your_model ( your_augmentation ( data ))
loss = loss_func ( embeddings , augmented )
loss . backward ()
optimizer . step ()Si vous êtes intéressé par l'auto-supervision de style MOCO, jetez un œil au cahier MOCO sur CIFAR10. Il utilise CrossBatchMemory pour implémenter la file d'attente de l'encodeur de momentum, ce qui signifie que vous pouvez utiliser n'importe quelle perte de tuple et n'importe quel mineur de tuple pour extraire des échantillons durs de la file d'attente.
Si vous êtes à court de temps et que vous souhaitez un workflow de train / test complet, consultez l'exemple de cahiers Google Colab.
Pour en savoir plus sur tout ce qui précède, voir la documentation.
pytorch-metric-learning >= v0.9.90 nécessite torch >= 1.6pytorch-metric-learning < v0.9.90 n'a pas d'exigence de version, mais a été testé avec torch >= 1.2 Autres dépendances: numpy, scikit-learn, tqdm, torchvision
pip install pytorch-metric-learning
Pour obtenir la dernière version Dev :
pip install pytorch-metric-learning --pre
Pour installer sur Windows :
pip install torch===1.6.0 torchvision===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-metric-learning
Pour installer avec des capacités d'évaluation et de journalisation
(Cela installera la version non officielle de PYPI de FAISS-GPU, plus le gardien de dossier et le tensorboard):
pip install pytorch-metric-learning[with-hooks]
Pour installer avec des capacités d'évaluation et de journalisation (CPU)
(Cela installera la version non officielle de PYPI de FAISS-CPU, plus le gardien de disques et Tensorboard):
pip install pytorch-metric-learning[with-hooks-cpu]
conda install -c conda-forge pytorch-metric-learning
Pour utiliser le module de test, vous aurez besoin de Faish, qui peut également être installé via Conda. Voir les instructions d'installation pour FAISS.
Voir le marché de bench-bench pour afficher les résultats de référence et pour utiliser l'outil d'analyse comparative.
Le développement se fait sur la branche dev :
git checkout dev
Les tests unitaires peuvent être exécutés avec la bibliothèque unittest par défaut:
python -m unittest discoverVous pouvez spécifier les données de test et le périphérique de test sous forme de variables d'environnement. Par exemple, pour tester en utilisant Float32 et Float64 sur le CPU:
TEST_DTYPES=float32,float64 TEST_DEVICE=cpu python -m unittest discoverPour exécuter un seul fichier de test au lieu de toute la suite de test, spécifiez le nom du fichier:
python -m unittest tests/losses/test_angular_loss.py Le code est formaté à l'aide black et isort :
pip install black isort
./format_code.shMerci aux contributeurs qui ont fait des demandes de traction!
| Donateur | Points forts |
|---|---|
| domenicomuscill0 | - manifoldloss - P2Sgradloss - Histogrogloss - dynamicsoftmarginloss - ClassedListloss |
| mlopezantesera | - Faire travailler les testeurs sur n'importe quelle combinaison de requêtes et d'ensembles de référence - La précision de la précision fonctionne avec des comparaisons arbitraires |
| cwkeam | - auto-upéralisé - vicregloss - Ajout de la précision moyenne du classement réciproque à la précision - Baselosswrapper |
| IR2718 | - ThresholdConsistentMarginloss - Le module de jeu de données |
| marijnl | - Batcheasyhardmin - Twostreammetricloss - GlobalTwostreamembeddingsPaceTester - Exemple à l'aide de formateurs.twostreammetricloss |
| chingisoinar | Subcenterarcfaceloss |
| Elias-Ramzi | Échantillonneur hiérarchique |
| FJSJ | Supconloss |
| Alenubuntu | Circleloss |
| intéressantzhuo | Ploss |
| wconnell | Apprendre une intégration métrique Scrnaseq |
| mkmenta | Amélioré get_all_triplets_indices (Correction de l'erreur INT_MAX ) |
| Alexschuy | optimisé utils.loss_and_miner_utils.get_random_triplet_indices |
| Johngiorgi | all_gather in utils.Distributed |
| Hummer12007 | utils.key_checker |
| vltanh | Fait InferenceModel.train_indexer accepter les ensembles de données |
| btseytlin | get_nearest_neighbors dans inférencemodel |
| MLW214 | Ajout return_per_class à la précision |
| Layumi | Instanceloss |
| Notation | A aidé à ajouter ref_emb et ref_labels aux wrappers distribués. |
| Elisonsherton | Correction d'un boîtier de bord dans Arcfaceloss. |
| stompsjo | Documentation améliorée pour ntxentloss. |
| Galerie | Correction de bugs pour PNPLOSS. |
| Elisim | Améliorations des développeurs à DistributedLosswrapper. |
| Gaetanlepage | |
| z1w | |
| Thinline72 | |
| tpanum | |
| fractive | |
| Joaqo | |
| Jokuma | |
| gkouros | |
| yutanakamura-tky | |
| Kinglittleq | |
| Martin0258 | |
| Michaeldeyzel | |
| Hsinger04 | |
| rhume | |
| bot66 |
Merci à Ser-Nam Lim à Facebook AI et à mon conseiller de recherche, le professeur Serge Pleancie. Ce projet a commencé lors de mon stage à Facebook IA où j'ai reçu des commentaires précieux de Ser-Nam, et de son équipe d'ingénieurs de vision et d'apprentissage automatique et de chercheurs. En particulier, grâce à Ashish Shah et Austin Reiter pour avoir examiné mon code au cours de ses premiers stades de développement.
Cette bibliothèque contient du code qui a été adapté et modifié à partir des grandes références open source suivantes:
Merci à Jeff Musgrave pour la conception du logo.
Si vous souhaitez citer le pytorch-métrique-apprentissage dans votre papier, vous pouvez utiliser ce bibtex:
@article{Musgrave2020PyTorchML,
title={PyTorch Metric Learning},
author={Kevin Musgrave and Serge J. Belongie and Ser-Nam Lim},
journal={ArXiv},
year={2020},
volume={abs/2008.09164}
}

