pytorch metric learning
v2.8.1

11. Dezember : v2.8.0
2. November : v2.7.0
Weitere Informationen finden Sie im Beispiel -Ordner für Notebooks, die Sie auf Google Colab herunterladen oder ausführen können.
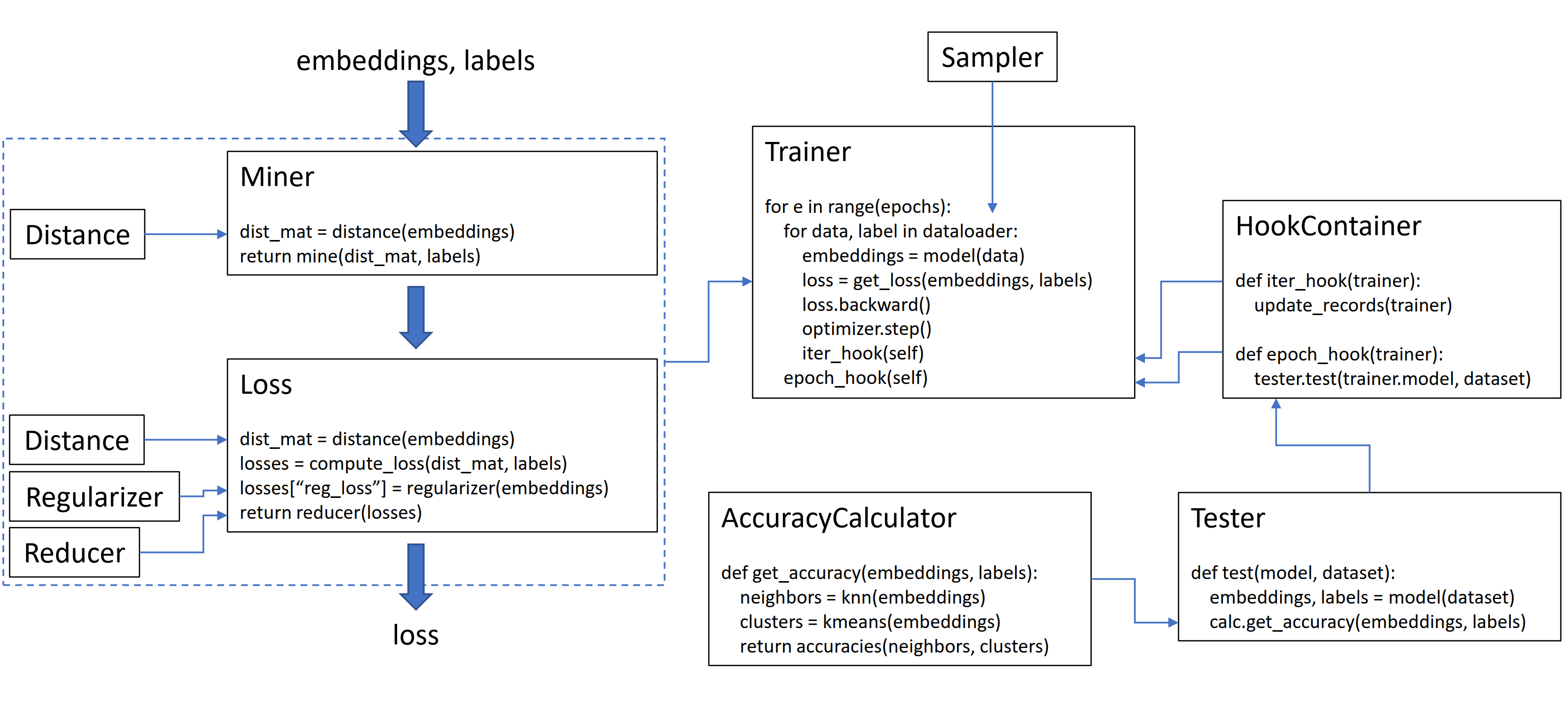
Diese Bibliothek enthält 9 Module, von denen jedes unabhängig in Ihrer vorhandenen Codebasis verwendet oder zusammen für einen vollständigen Zug-/Test -Workflow kombiniert werden kann.
Lassen Sie uns einen einfachen Tripletmarginloss initialisieren:
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ()Um den Verlust in Ihrer Trainingsschleife zu berechnen, geben Sie die von Ihrem Modell berechneten Einbettungen und die entsprechenden Beschriftungen ein. Die Einbettungen sollten eine Größe (n, einbettend_size) haben, und die Beschriftungen sollten Größe (n) haben, wobei n die Chargengröße ist.
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
loss = loss_func ( embeddings , labels )
loss . backward ()
optimizer . step ()Das TripletMarginLoss berechnet alle möglichen Tripletts innerhalb der Charge, basierend auf den Etiketten, die Sie in sie übergeben. Anker-positive Paare werden durch Einbettungen gebildet, die das gleiche Etikett teilen, und Anker-negative Paare werden durch Einbettungen mit unterschiedlichen Etiketten gebildet.
Manchmal kann es helfen, eine Bergbaufunktion hinzuzufügen:
from pytorch_metric_learning import miners , losses
miner = miners . MultiSimilarityMiner ()
loss_func = losses . TripletMarginLoss ()
# your training loop
for i , ( data , labels ) in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = model ( data )
hard_pairs = miner ( embeddings , labels )
loss = loss_func ( embeddings , labels , hard_pairs )
loss . backward ()
optimizer . step ()Im obigen Code findet der Bergmann positive und negative Paare, die er für besonders schwierig hält. Beachten Sie, dass der TripletmarginLoss, obwohl es auf Drillingen arbeitet, dennoch paarweise möglich ist, paarweise zu bestehen. Dies liegt daran, dass die Bibliothek bei Bedarf Paare automatisch in Tripletts und Drillinge in Paare umwandelt.
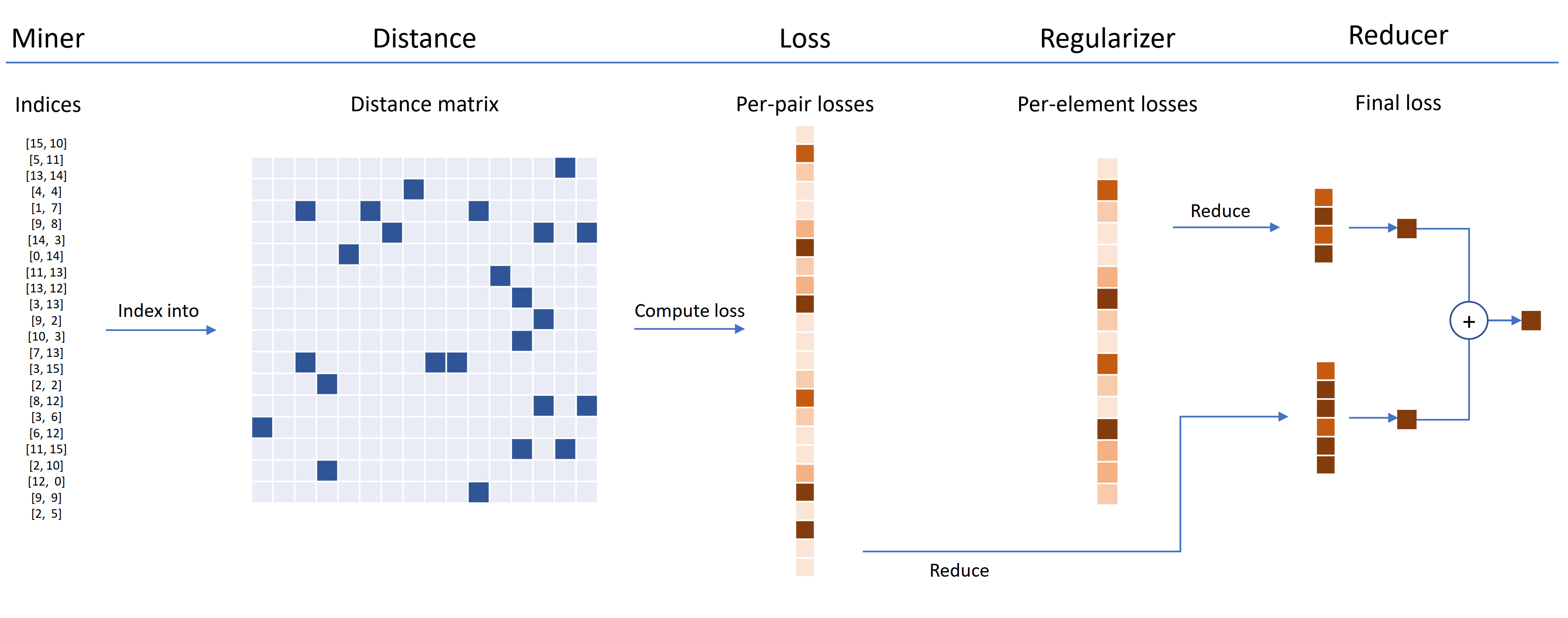
Verlustfunktionen können mit Entfernungen, Reduzierern und Regularisierern angepasst werden. Im folgenden Diagramm findet ein Bergmann die Indizes von harten Paaren in einer Charge. Diese werden verwendet, um in die Distanzmatrix zu indexieren, die vom Distanzobjekt berechnet wird. Für dieses Diagramm ist die Verlustfunktion Paarbasiert und berechnet einen Verlust pro Paar. Darüber hinaus wurde ein Ileparierer geliefert, sodass für jede Einbettung in die Charge ein Regularisierungsverlust berechnet wird. Die Verluste pro Pair- und Perelement werden an den Reduzierer weitergegeben, der (in diesem Diagramm) nur Verluste mit hohem Wert hält. Die Durchschnittswerte werden für die hochwertigen Paar- und Elementverluste berechnet und dann zusammengefügt, um den endgültigen Verlust zu erhalten.
Hier ist ein Beispiel für ein maßgeschneidertes Tripletmarginloss:
from pytorch_metric_learning . distances import CosineSimilarity
from pytorch_metric_learning . reducers import ThresholdReducer
from pytorch_metric_learning . regularizers import LpRegularizer
from pytorch_metric_learning import losses
loss_func = losses . TripletMarginLoss ( distance = CosineSimilarity (),
reducer = ThresholdReducer ( high = 0.3 ),
embedding_regularizer = LpRegularizer ())Dieser angepasste Triplett -Verlust hat die folgenden Eigenschaften:
Für das selbstbewertete Lernen wird eine SelfSupervisedLoss Wrapper vorgesehen:
from pytorch_metric_learning . losses import SelfSupervisedLoss
loss_func = SelfSupervisedLoss ( TripletMarginLoss ())
# your training for-loop
for i , data in enumerate ( dataloader ):
optimizer . zero_grad ()
embeddings = your_model ( data )
augmented = your_model ( your_augmentation ( data ))
loss = loss_func ( embeddings , augmented )
loss . backward ()
optimizer . step ()Wenn Sie sich für Selbst-Supervision von Moco-Art interessieren, schauen Sie sich das MOCO auf CIFAR10-Notizbuch an. Es verwendet CrossbatchMemory, um die Impulscodiererwarteschlange zu implementieren. Dies bedeutet, dass Sie jeden Tupelverlust und jeden Tupel -Bergmann verwenden können, um harte Proben aus der Warteschlange zu extrahieren.
Wenn Sie keine Zeit haben und einen vollständigen Zug-/Test -Workflow wünschen, lesen Sie die Google Colab -Notizbücher.
Weitere Informationen zu allen oben genannten Informationen finden Sie in der Dokumentation.
pytorch-metric-learning >= v0.9.90 erfordert torch >= 1.6pytorch-metric-learning < v0.9.90 hat keine Versionsanforderung, wurde jedoch mit torch >= 1.2 getestet Andere Abhängigkeiten: numpy, scikit-learn, tqdm, torchvision
pip install pytorch-metric-learning
Um die neueste Entwicklerversion zu erhalten :
pip install pytorch-metric-learning --pre
So installieren Sie unter Windows :
pip install torch===1.6.0 torchvision===0.7.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install pytorch-metric-learning
Mit Bewertungs- und Protokollierungsfunktionen zu installieren
(Dadurch wird die inoffizielle PYPI-Version von Faiss-GPU sowie Rekordkeeper und Tensorboard installiert):
pip install pytorch-metric-learning[with-hooks]
Mit Bewertungs- und Protokollierungsfunktionen (CPU) zu installieren
(Dadurch wird die inoffizielle PYPI-Version von FAISS-CPU sowie Rekordkeeper und Tensorboard installiert):
pip install pytorch-metric-learning[with-hooks-cpu]
conda install -c conda-forge pytorch-metric-learning
Um das Testmodul zu verwenden, benötigen Sie FAISS, das auch über Conda installiert werden kann. Siehe die Installationsanweisungen für FAISS.
Sehen Sie sich leistungsstarke Benchmarker an, um Benchmark-Ergebnisse anzuzeigen und das Benchmarking-Tool zu verwenden.
Die Entwicklung erfolgt am dev :
git checkout dev
Unit -Tests können mit der Standard unittest -Bibliothek durchgeführt werden:
python -m unittest discoverSie können die Testdatenatypen und das Testgerät als Umgebungsvariablen angeben. Zum Beispiel zum Testen mit Float32 und Float64 auf der CPU:
TEST_DTYPES=float32,float64 TEST_DEVICE=cpu python -m unittest discoverUm eine einzelne Testdatei anstelle der gesamten Testsuite auszuführen, geben Sie den Dateinamen an:
python -m unittest tests/losses/test_angular_loss.py Der Code wird mit black und isort formatiert:
pip install black isort
./format_code.shVielen Dank an die Mitwirkenden, die Pull -Anfragen gestellt haben!
| Mitwirkender | Highlights |
|---|---|
| Domenicomuscill0 | - Verteiler - P2sgradloss - Histogramloss - Dynamicsoftmarginloss - RankedListLoss |
| Mlopezantequera | - Die Tester haben an einer beliebigen Kombination von Abfragen und Referenzsätzen gearbeitet - Die Accuracycalculator -Arbeit mit beliebigen Etikettenvergleiche |
| cwKeam | - Selbstverträglichkeit - Vicregloss - Die mittlere wechselseitige Ranggenauigkeit zu AccuracyCalculator hinzugefügt - Baselosswrapper |
| IR2718 | - Schwellenwertkonsistentmarginloss - Das Datasets -Modul |
| Marijnl | - BatcheasyHardminer - TWSTREAMMETRICLOSS - GlobalTWostreamembedingspacetester - Beispiel unter Verwendung von Trainern.twostreamMetricloss |
| Chingisooinar | SubCenterarcfaceloss |
| Elias-Ramzi | HierarchicalSampler |
| fjsj | Supconloss |
| Alenubuntu | Circleloss |
| interessantzhuo | Pnploloss |
| Wconnell | Erlernen einer Einbettung von Scrnaseq -Metrik |
| Mkmenta | Verbessert get_all_triplets_indices (behoben den INT_MAX -Fehler) |
| Alexschuy | optimierte utils.loss_and_miner_utils.get_random_triplet_indices |
| Johngiorgi | all_gather in utils.distributed |
| Hummer12007 | utils.key_checker |
| Vltanh | MADE InferenceModel.train_indexer ANACPTE DATASETS |
| Btseytlin | get_nearest_neighbors im Inferencemodel |
| MLW214 | return_per_class zum accuracycalculator hinzugefügt |
| Layumi | InstanCeloss |
| Notodie | Half, den verteilten Wrappern ref_emb und ref_labels hinzuzufügen. |
| Elisonsherton | Ein Kantenfall in Arcfaceloss behoben. |
| stompsjo | Verbesserte Dokumentation für NTXentloss. |
| Puzer | Fehlerbehebung für PNLloss. |
| Elisim | Entwicklerverbesserungen an DistributedLosSwrapper. |
| Gaetanlepage | |
| Z1W | |
| Dünnline72 | |
| tpanum | |
| Fralik | |
| Joaqo | |
| Jookuma | |
| gkouros | |
| Yutanakamura-Tky | |
| Kinglittleq | |
| Martin0258 | |
| Michaeldeyzel | |
| Hsinger04 | |
| Rheum | |
| Bot66 |
Vielen Dank an Ser-Nam Lim bei Facebook AI und meinen Forschungsberater Professor Serge Adj. Dieses Projekt begann während meines Praktikums bei Facebook AI, wo ich wertvolles Feedback von Ser-NAM sowie sein Team von Computer Vision und maschinellem Lernen und Forschungswissenschaftlern erhielt. Insbesondere dank Ashish Shah und Austin Reiter für die Überprüfung meines Codes in den frühen Entwicklungsstadien.
Diese Bibliothek enthält Code, der aus den folgenden großartigen Open-Source-Repos angepasst und geändert wurde:
Vielen Dank an Jeff Musgrave für die Gestaltung des Logos.
Wenn Sie Pytorch-Metric-Learning in Ihrem Papier zitieren möchten, können Sie dieses Bibtex verwenden:
@article{Musgrave2020PyTorchML,
title={PyTorch Metric Learning},
author={Kevin Musgrave and Serge J. Belongie and Ser-Nam Lim},
journal={ArXiv},
year={2020},
volume={abs/2008.09164}
}

