code supporter
1.0.0
Este projeto tem como objetivo aproveitar grandes recursos de modelo de linguagem para apoiar a codificação.
O sistema inclui cliente e servidor. No lado do cliente, existem vários recursos interessantes, incluindo gerenciamento de snippet, interface básica de chatbot, escolha de modelos, escolha de consulta ou feedback. No lado do servidor, a lógica da consulta / feedback é implementada, o FutHermore, o FASTAPI é usado para interagir com as APIs do ChatGPT.
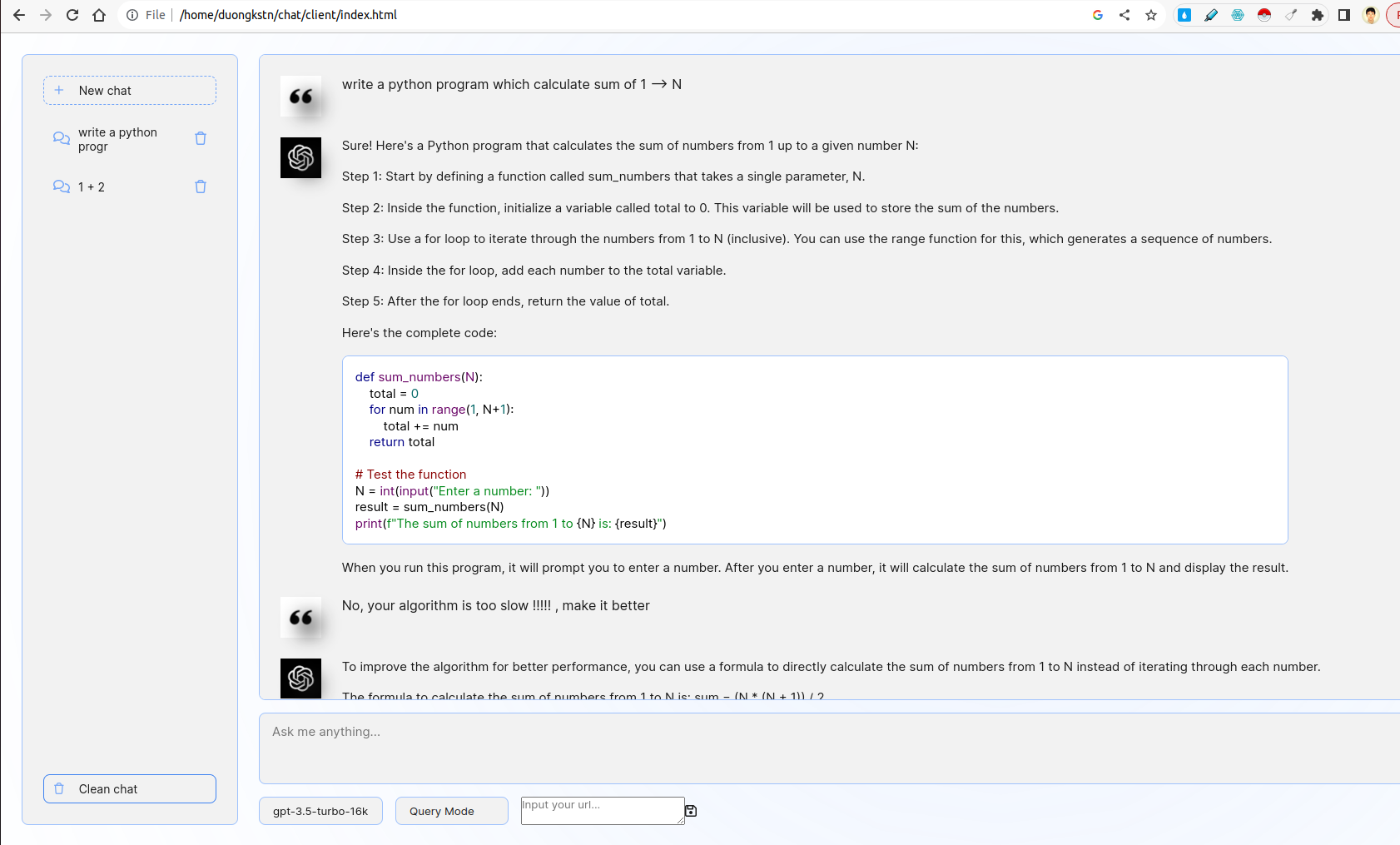
- Desenvolva uma interface da Web fácil de usar usando o FASTAPI ou o frasco que leva os usuários a inserir uma descrição de seu problema de codificação.
- A interface deve interagir com um LLM para gerar um snippet de código correspondente com base na entrada do usuário.
O front-end é inspirado na interface do usuário chatgpt. Ele interage com o back-end usando o WebSocket. Em mais detalhes, o front-end pega uma consulta de usuário e a transmite ao servidor por websocket. O servidor obterá o resultado do ChatGPT by FASTAPI Streaming Mode e depois a seguirá para o cliente.
- Incorpore um feito que permita aos usuários fornecer feedback sobre os trechos de código gerados.
- Utilize esse feedback para refinar as gerações futuras.
Aqui, existem duas opções no modo de consulta e no modo de feedback. No modo de consulta, o prompt de codificação é usado por técnica de solicitação de cadeia de pensamento. No modo de feedback, o prompt de feedback é usado para refinar os feedbacks negativos do usuário pela técnica de solicitação de poucas fotos (consulte server/prompts.py ).
Para alternar entre dois modos, você pode escolher opções como abaixo: 
- Desenvolva scripts para executar e utilizar um LLM personalizado localmente ou em um servidor GPU.
Na pasta custom_llm , há um script para executar o LLM personalizado por vllm . Você pode inserir seu URL na interface do usuário e clicar em Salvar: 
Além disso, você pode escolher o modelo que deseja das opções abaixo da caixa de texto de entrada. 
- Forneça um DockerFile, juntamente com as instruções para construir e executar o aplicativo como um contêiner
O projeto suporta serviços de construção da Dockerfile (s). Para executar o contêiner do docker da página da web do cliente, execute:
cd client/
sudo docker build -t code-supporter-client:latest .
sudo docker run -d -p 8000:80 code-supporter-client:latest
Por outro lado, execute o contêiner do Docker do servidor da seguinte forma:
cd server/
sudo docker build -t code-supporter-server:latest .
sudo docker run -p 7999:80 -e OPENAI_API_KEY=sk-... code-supporter-server:latest
Para simplificar, você pode executar o cliente e o servidor por apenas um comando (altere o OPENAI_API_KEY em docker-compose.yml ):
sudo docker compose up
Afinal, vá para URL http://localhost:8000/ no navegador para começar a conversar!
- Implemente a funcionalidade na mesma interface para exibir uma lista de trechos de código gerados anteriormente.
- Os usuários devem poder visualizar, revisar e excluir esses trechos
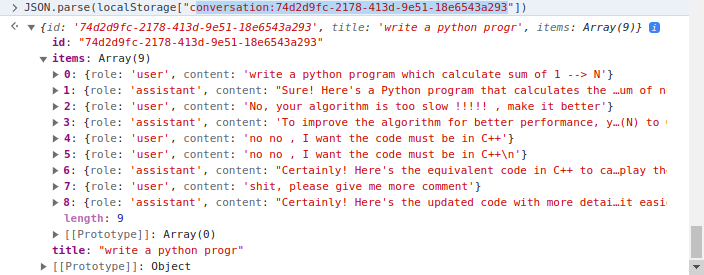
O lado do cliente implementa o gerenciamento de snippets onde localStorage of Client é usado. Em mais detalhes, localStorage é um dicionário em que a chave é conversation_id , o valor é conversões em várias voltas. Exemplo uma conversa:
Existem duas pastas principais, client e server . Enquanto o primeiro inclui o código HTML/CSS/JavaScript para renderizar a página da web apoiador do código, o código posterior contém servidor escrito no Python.
Na pasta client , o código mais importante é o arquivo js/chat.js , onde lida com a lógica da iteracração de servidor/cliente na pasta server , o uso de arquivos da seguinte forma:
apps.py : Servindo FASTAPIrouters : lidarprompts.py : declarar promptsutils.py : algumas funções de apoio

