code supporter
1.0.0
Dieses Projekt soll große Sprachmodellfunktionen nutzen, um die Codierung zu unterstützen.
Das System umfasst Client und Server. Auf der Client -Seite gibt es verschiedene interessante Funktionen, darunter Snippet -Management, grundlegende Chatbot -Schnittstelle, Auswahl von Modellen, Auswählen des Abfragebus oder Feedback -Modus. Auf der Serverseite wird die Logik von Abfrage / Feedback implementiert, futhermore, Fastapi wird verwendet, um mit ChatGPT -APIs zu interagieren.
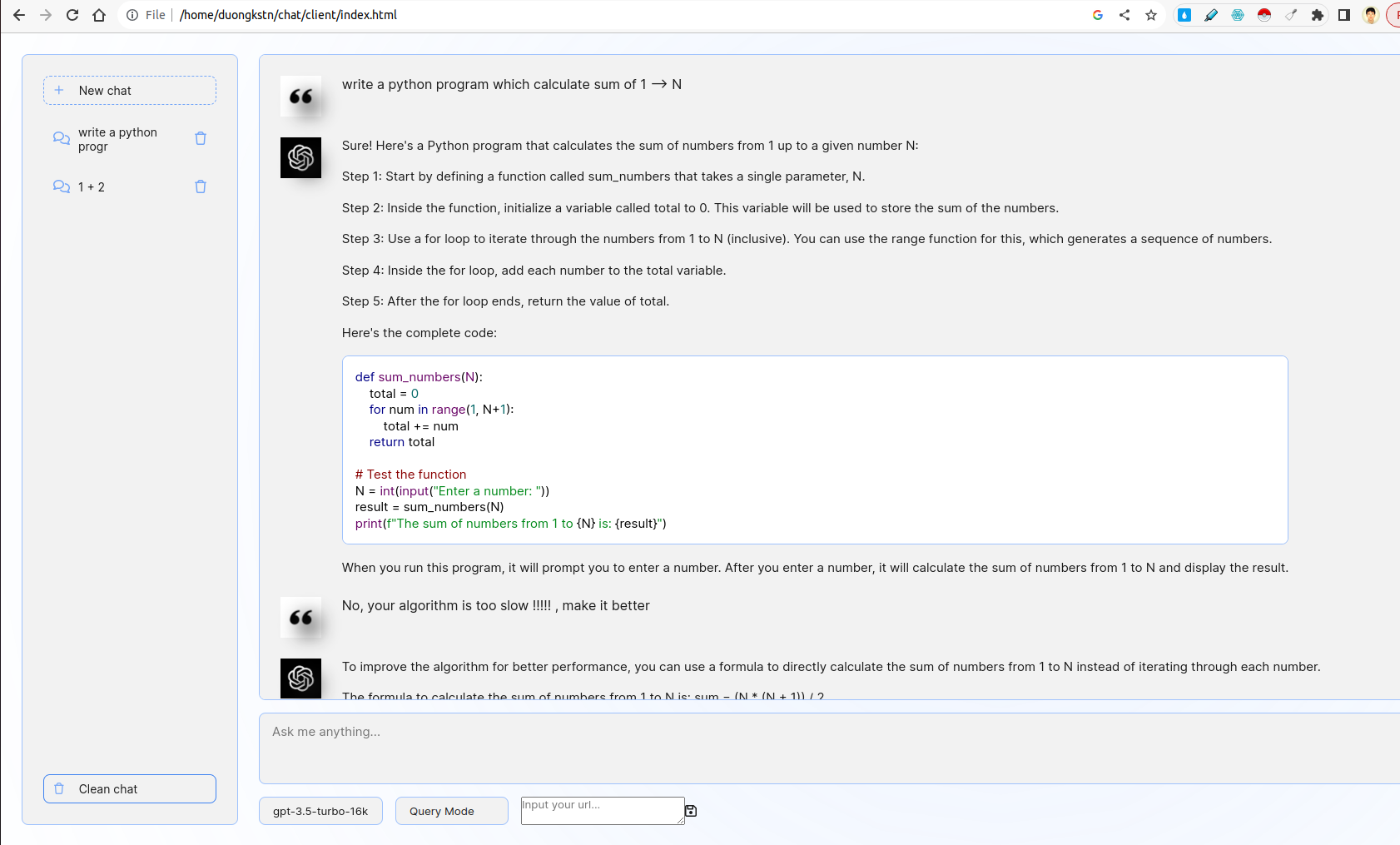
- Entwickeln Sie eine benutzerfreundliche Weboberfläche mit Fastapi oder Flask, mit der Benutzer eine Beschreibung ihres Codierungsproblems eingeben.
- Die Schnittstelle sollte mit einem LLM interagieren, um ein entsprechendes Code -Snippet basierend auf der Eingabe des Benutzers zu generieren.
Das Front-End ist von der Chatgpt-UI untergeführt. Es interagiert mit Back-End mithilfe von WebSocket. Ausführlicher ist das Front-End eine Benutzerabfrage und übermittelt sie per WebSocket an Server. Der Server wird im Fastapi -Streaming -Modus von ChatGPT Ergebnis und dann an den Client weitergeleitet.
- Integrieren Sie ein Feature, mit dem Benutzer Feedback zu den generierten Code -Snippets geben können.
- Verwenden Sie dieses Feedback, um zukünftige Generationen zu verfeinern.
Hier gibt es zwei Optionen Abfragemodus und Feedback -Modus. Im Abfragemodus wird die Codierungsaufforderung durch die Einberufungstechnik der Kette der Kette verwendet. Im Feedback-Modus wird die Feedback-Eingabeaufforderung verwendet, um die negativen Feedbacks des Benutzers durch wenige Schussförderungstechniken zu verfeinern (siehe server/prompts.py ).
Um zwischen zwei Modi zu wechseln, können Sie Optionen wie unten auswählen: 
- Entwickeln Sie Skripte zum Ausführen und Verwenden eines benutzerdefinierten LLM entweder lokal oder auf einem GPU -Server.
Im Ordner custom_llm gibt es ein Skript zum Ausführen von benutzerdefinierten LLM von vllm . Sie können Ihre URL in die Benutzeroberfläche eingeben und auf Speichern klicken: 
Zusätzlich können Sie aus Optionen unter dem Textfeld Eingabetaste ein Modell auswählen, das Sie möchten. 
- Geben Sie eine Dockerfile zusammen mit Anweisungen zum Erstellen und Ausführen der Anwendung als Container an
Das Projekt unterstützt Baudienste von DockerFile (en). Um den Client -Webseite Docker -Container auszuführen, rennen Sie:
cd client/
sudo docker build -t code-supporter-client:latest .
sudo docker run -d -p 8000:80 code-supporter-client:latest
Führen Sie auf der anderen Seite den Server -Docker -Container wie folgt aus:
cd server/
sudo docker build -t code-supporter-server:latest .
sudo docker run -p 7999:80 -e OPENAI_API_KEY=sk-... code-supporter-server:latest
Um zu vereinfachen, können Sie Client und Server nur einen Befehl ausführen (bitte ändern Sie den OPENAI_API_KEY in docker-compose.yml ):
sudo docker compose up
Gehen Sie schließlich zu URL http://localhost:8000/ auf dem Browser, um mit dem Chatten zu beginnen!
- Implementieren Sie die Funktionalität in derselben Schnittstelle, um eine Liste zuvor generierter Code -Snippets anzuzeigen.
- Benutzer sollten diese Snippets anzeigen, überprüfen und löschen können
Die Client -Seite implementiert das Snippet -Management, bei dem localStorage of Client verwendet wird. Ausführlicher, localStorage ist ein Wörterbuch, in dem der Schlüssel conversation_id ist. Der Wert ist in mehreren Kurven. Beispiel ein Gespräch:
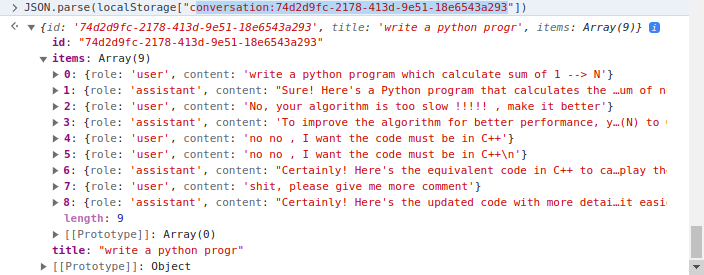
Es gibt zwei Hauptordner, client und server . Während der erste HTML/CSS/JavaScript -Code enthält, um die Webseite des Code -Unterstützers zu rendern, enthält der später in Python geschriebene Servercode.
Im client -Ordner ist der wichtigste Code js/chat.js -Datei, in dem die Logik der Server-/Client -Iteraktion im server verarbeitet wird, die Verwendung von Dateien wie folgt:
apps.py : Fastapi servierenrouters : Behandeln Sie Fastapi WebSocket -Anfragen und iteract mit Client -Seiteprompts.py : Eingabeaufforderungen deklarierenutils.py : Einige unterstützende Funktionen

