code supporter
1.0.0
Este proyecto tiene como objetivo aprovechar las capacidades de modelos de idiomas grandes para admitir la codificación.
El sistema incluye cliente y servidor. En el lado del cliente, hay varias características interesantes que incluyen administración de fragmentos, interfaz de chatbot básica, eligiendo modelos, eligiendo consultas o modo de retroalimentación. En el lado del servidor, se implementa la lógica de consulta / retroalimentación, Futhermore, Fastapi se usa para interactuar con las API de CHATGPT.
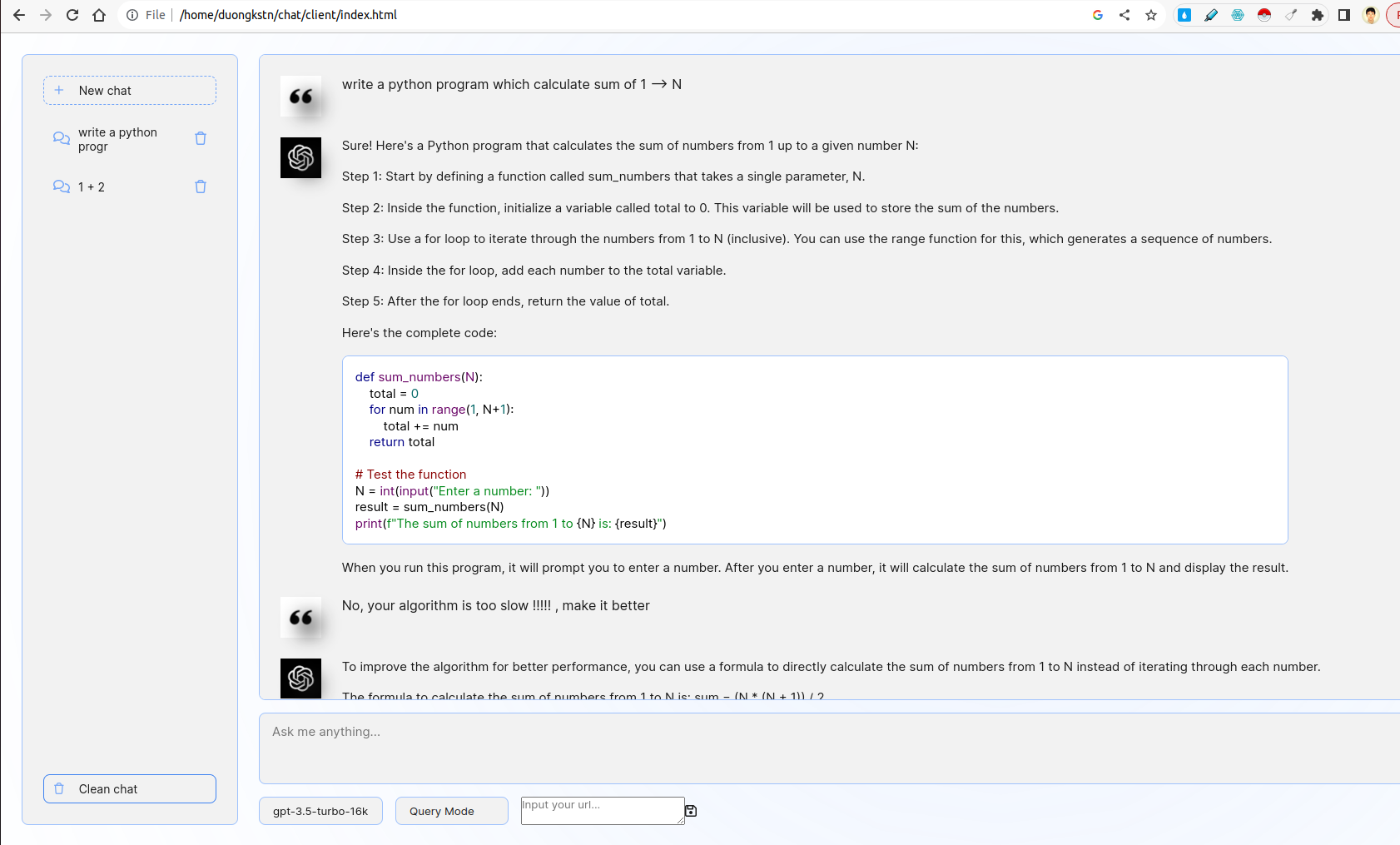
- Desarrolle una interfaz web fácil de usar usando FastAPI o Flask que solicite a los usuarios que ingresen una descripción de su problema de codificación.
- La interfaz debe interactuar con un LLM para generar un fragmento de código correspondiente en función de la entrada del usuario.
El front-end está inspirado de la interfaz de usuario de Chatgpt. Interactúa con el back-end utilizando WebSocket. En más detalles, el front-end toma una consulta de usuario y la transmite al servidor por WebSocket. El servidor obtendrá el resultado de CHATGPT por el modo de transmisión de FastAPI y luego reenvía al cliente.
- Incorpore una característica que permita a los usuarios proporcionar comentarios sobre los fragmentos de código generados.
- Utilice esta retroalimentación para refinar las generaciones futuras.
Aquí, hay dos opciones Modo de consulta y modo de retroalimentación. En el modo de consulta, la solicitud de codificación se utiliza mediante la técnica de solicitación de la cadena de pensamiento. En el modo de retroalimentación, la solicitud de retroalimentación se utiliza para refinar los comentarios negativos del usuario mediante la técnica de solicitación de pocos disparos (consulte server/prompts.py ).
Para cambiar entre dos modos, puede elegir opciones como a continuación: 
- Desarrolle scripts para ejecutar y utilizar un LLM personalizado localmente o en un servidor GPU.
En la carpeta custom_llm , hay un script para ejecutar LLM personalizado por vllm . Puede ingresar su URL a UI y hacer clic en Guardar: 
Además, puede elegir el modelo que desee de las opciones debajo del cuadro de texto de entrada. 
- Proporcione un DockerFile junto con instrucciones para construir y ejecutar la aplicación como contenedor
El proyecto admite los servicios de construcción de Dockerfile (S). Para ejecutar el contenedor de Docker de la página web del cliente, ejecute:
cd client/
sudo docker build -t code-supporter-client:latest .
sudo docker run -d -p 8000:80 code-supporter-client:latest
Por otro lado, ejecute el contenedor de Docker del servidor de la siguiente manera:
cd server/
sudo docker build -t code-supporter-server:latest .
sudo docker run -p 7999:80 -e OPENAI_API_KEY=sk-... code-supporter-server:latest
Para simplificar, puede ejecutar el cliente y el servidor por un solo comando (cambie el OPENAI_API_KEY en docker-compose.yml ):
sudo docker compose up
Después de todo, vaya a URL http://localhost:8000/ en el navegador para comenzar a chatear!
- Implemente la funcionalidad dentro de la misma interfaz para mostrar una lista de fragmentos de código previamente generados.
- Los usuarios deben poder ver, revisar y eliminar estos fragmentos
El lado del cliente implementa la gestión de fragmentos donde se utiliza localStorage del cliente. En más detalles, localStorage es un diccionario donde la clave es conversation_id , el valor es converstions en múltiples turnos. Ejemplo una conversación:
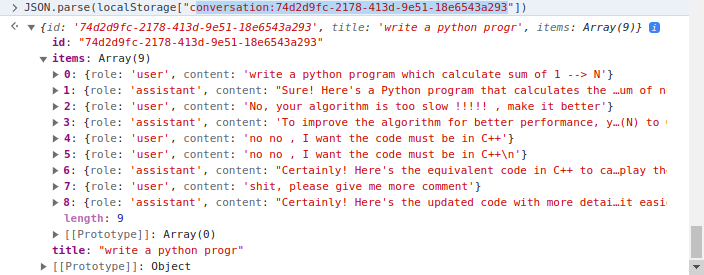
Hay dos carpetas principales, client y server . Mientras que el primero incluye el código HTML/CSS/JavaScript para representar la página web del seguidor del código, el más tarde contiene código del servidor escrito en Python.
En la carpeta client , el código más importante es el archivo js/chat.js , donde maneja la lógica de la iteración del servidor/cliente en la carpeta server , el uso de archivos de la siguiente manera:
apps.py : servir Fastapirouters : maneje las solicitudes de Fastapi WebSocket e Iteract con el lado del clienteprompts.py : declare indicacionesutils.py : algunas funciones de apoyo

