code supporter
1.0.0
Ce projet vise à tirer parti des capacités de modèle de langue importante pour soutenir le codage.
Le système comprend le client et le serveur. Du côté client, il existe diverses fonctionnalités intéressantes, notamment la gestion de l'extrait, l'interface de base du chatbot, le choix des modèles, le choix de la requête ou du mode de rétroaction. Du côté du serveur, la logique de la requête / commentaires est implémentée, Futhermore, FastAPI est utilisée pour interagir avec les API ChatGpt.
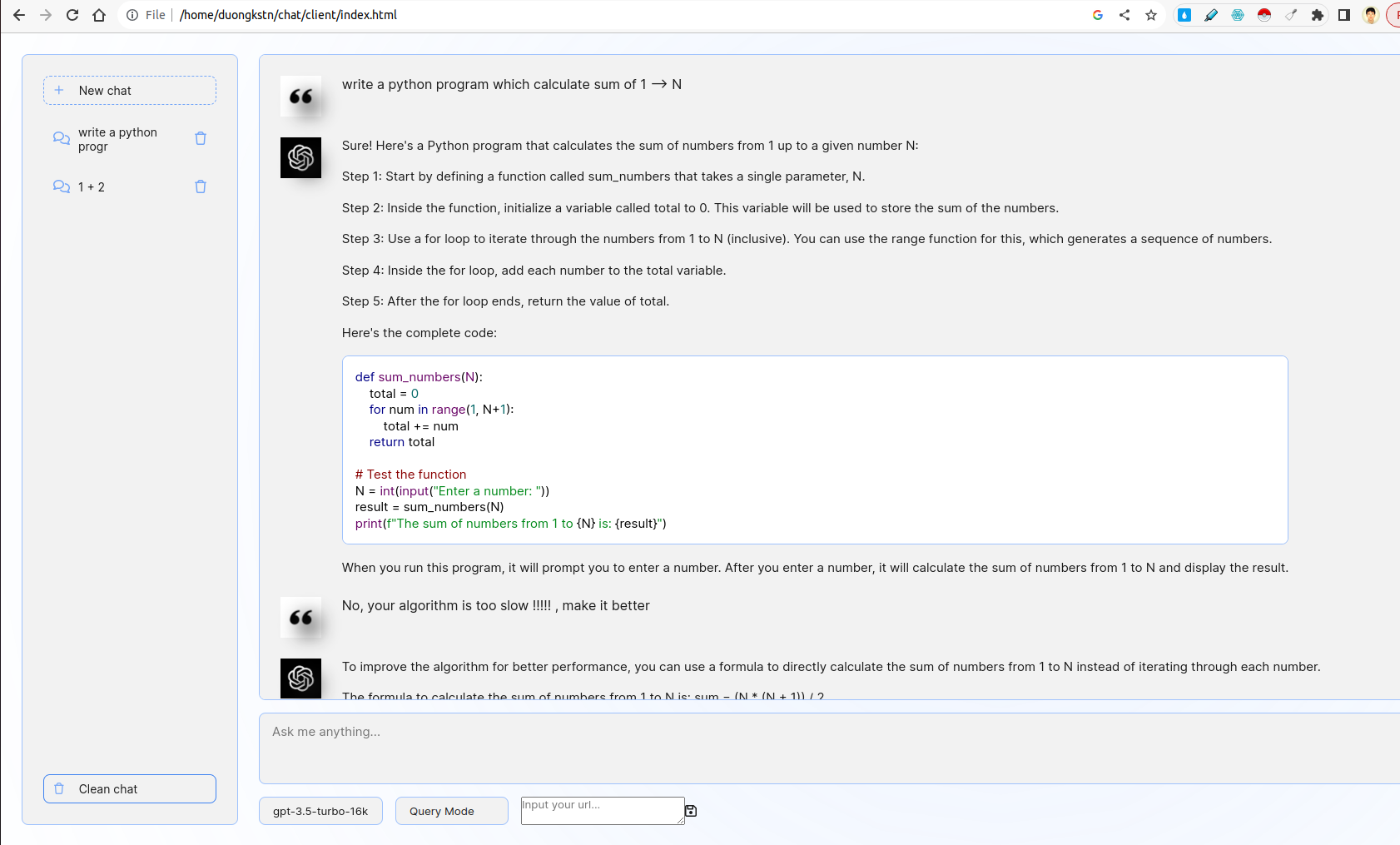
- Développez une interface Web conviviale à l'aide de FastAPI ou FLASK qui incite les utilisateurs à saisir une description de leur problème de codage.
- L'interface doit interagir avec un LLM pour générer un extrait de code correspondant en fonction de l'entrée de l'utilisateur.
Le front-end est insint à partir de l'interface utilisateur de Chatgpt. Il interagit avec le back-end en utilisant WebSocket. Dans plus de détails, le frontal prend une requête utilisateur et la transmet à Server par WebSocket. Le serveur obtiendra le résultat de ChatGPT par le mode de streaming Fastapi, puis transmetra au client.
- Incorporez une feat qui permet aux utilisateurs de fournir des commentaires sur les extraits de code générés.
- Utilisez ces commentaires pour affiner les générations futures.
Ici, il existe deux options en mode de requête et en mode de rétroaction. En mode requête, l'invite de codage est utilisée par la technique d'incitation à la chaîne. En mode rétroaction, l'invite de rétroaction est utilisée pour affiner les commentaires négatifs de l'utilisateur par une technique d'incitation à quelques coups (voir File server/prompts.py ).
Pour basculer entre deux modes, vous pouvez choisir des options comme ci-dessous: 
- Développez des scripts pour l'exécution et l'utilisation d'un LLM personnalisé localement ou sur un serveur GPU.
Dans le dossier custom_llm , il y a un script pour exécuter Custom LLM par vllm . Vous pouvez saisir votre URL vers l'interface utilisateur et cliquer sur Enregistrer: 
De plus, vous pouvez choisir le modèle que vous souhaitez à partir des options sous la zone de texte d'entrée. 
- Fournir un docker avec des instructions pour la construction et l'exécution de l'application en tant que conteneur
Le projet prend en charge les services de construction par Dockerfile (s). Pour exécuter Client WebPage Docker Container, exécutez:
cd client/
sudo docker build -t code-supporter-client:latest .
sudo docker run -d -p 8000:80 code-supporter-client:latest
D'un autre côté, exécutez le conteneur Docker Server comme suit:
cd server/
sudo docker build -t code-supporter-server:latest .
sudo docker run -p 7999:80 -e OPENAI_API_KEY=sk-... code-supporter-server:latest
Pour simplifier, vous pouvez exécuter le client et le serveur par une seule commande (veuillez modifier l' OPENAI_API_KEY dans docker-compose.yml ):
sudo docker compose up
Après tout, accédez à URL http://localhost:8000/ sur le navigateur pour commencer à discuter!
- Implémentez les fonctionnalités dans la même interface pour afficher une liste des extraits de code précédemment générés.
- Les utilisateurs doivent être en mesure de visualiser, examiner et supprimer ces extraits
Le côté client met en œuvre la gestion de l'extrait de l'extrait où localStorage de client est utilisé. Dans plus de détails, localStorage est un dictionnaire où la clé est conversation_id , la valeur est converstions en plusieurs tours. Exemple une conversation:
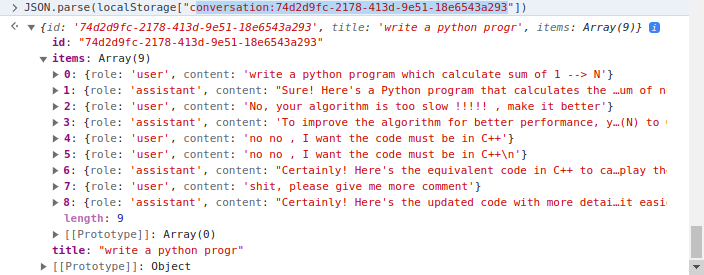
Il existe deux dossiers principaux, client et server . Alors que le premier inclut le code HTML / CSS / JavaScript pour rendre la page Web du support de code, le plus tard contient du code de serveur écrit en python.
Dans le dossier client , le code le plus important est le fichier js/chat.js , où il gère la logique de Server / Client Iteraction dans le dossier server , l'utilisation des fichiers comme suit:
apps.py : servir fastapirouters : gérer les demandes de Fastapi WebSocket et iteract avec côté clientprompts.py : déclarer les invitesutils.py : quelques fonctions de soutien

