datadog static analyzer
0.5.2
Dica
O Datadog suporta projetos de código aberto. Saiba mais sobre Datadog para projetos de código aberto.
Datadog-Static-analyzer é o mecanismo estático do analisador para análise estática do Datadog.
datadog-static-analyzer --directory /path/to/directory --output report.csv --format csvdocker run -it --rm -v /path/to/directory:/data ghcr.io/datadog/datadog-static-analyzer:latest --directory /data --output /data/report.csv --format csvPara obter mais informações sobre o contêiner do Docker, consulte a documentação aqui.
Se você encontrar um problema, leia as perguntas frequentes primeiro, ele poderá conter a solução para o seu problema.
Você pode escolher as regras a serem usadas para digitalizar seu repositório criando um arquivo static-analysis.datadog.yml .
Primeiro, siga a documentação e crie um arquivo static-analysis.datadog.yml na raiz do seu projeto com os conjuntos de regras que você deseja usar.
Todas as regras podem ser encontradas na documentação do Datadog. Sua static-analysis.datadog.yml pode conter apenas os conjuntos de regras disponíveis na documentação do Datadog
Exemplo de arquivo YAML
schema-version : v1
rulesets :
- python-code-style
- python-best-practices
- python-inclusive
ignore :
- testsVocê pode usá -lo no seu pipeline CI/CD usando nossa integração:
Se você o usar no seu próprio pipeline CI/CD, poderá integrar a ferramenta diretamente: consulte a documentação do Datadog para obter mais informações.
A extensão Datadog Intellij permite que você use o analisador estático diretamente de todos os produtos JetBrains. Crie um arquivo static-analysis.datadog.yml , faça o download da extensão e você pode começar a usá-lo. Você pode ver abaixo um exemplo de uma sugestão para adicionar um tempo limite ao buscar dados com Python com o módulo Solicitações.
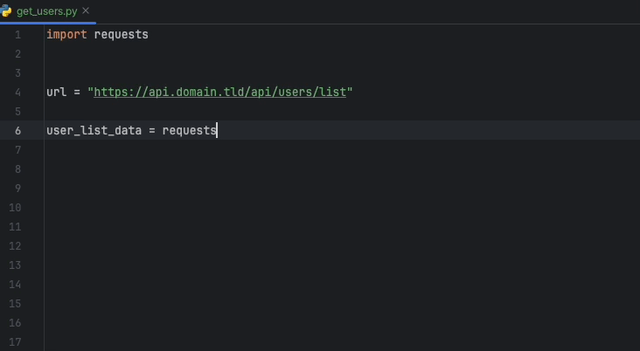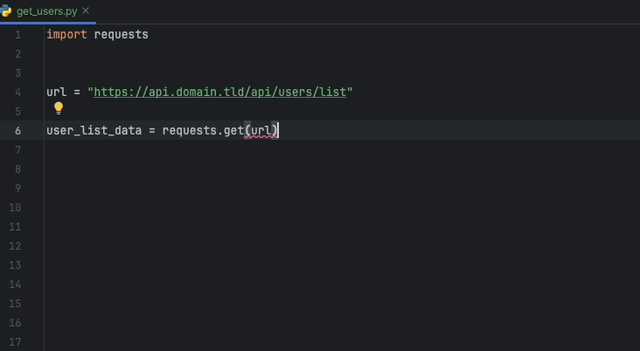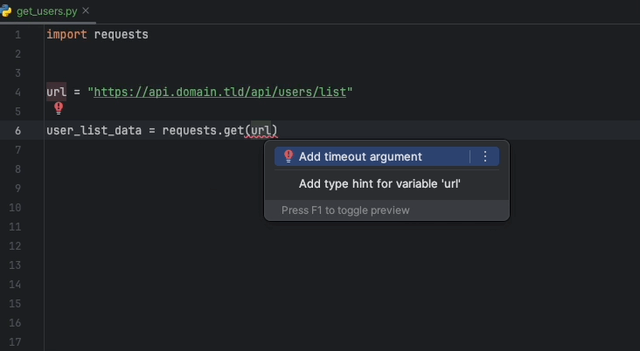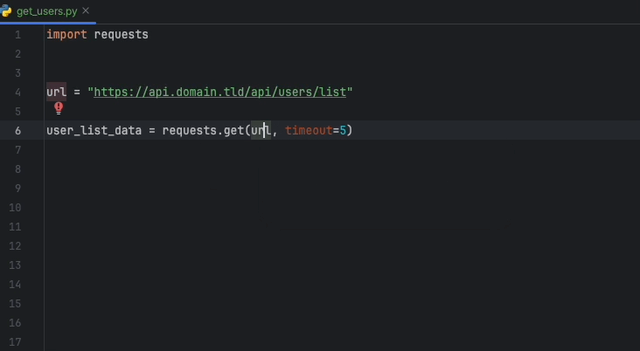
A extensão Datadog vs Code permite usar o analisador estático diretamente do código VS. Crie um arquivo static-analysis.datadog.yml , faça o download da extensão e você pode começar a usá-lo.
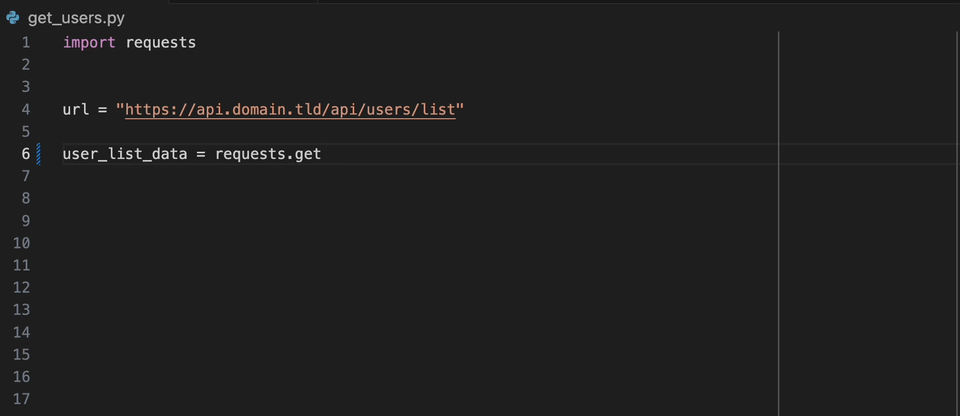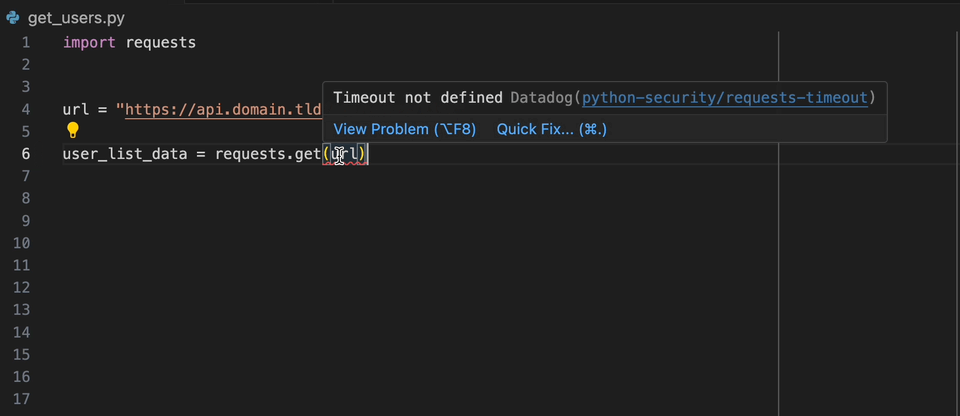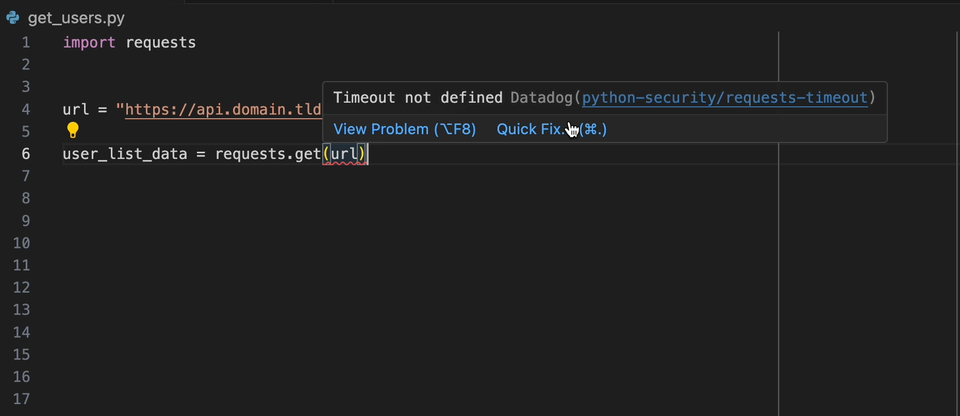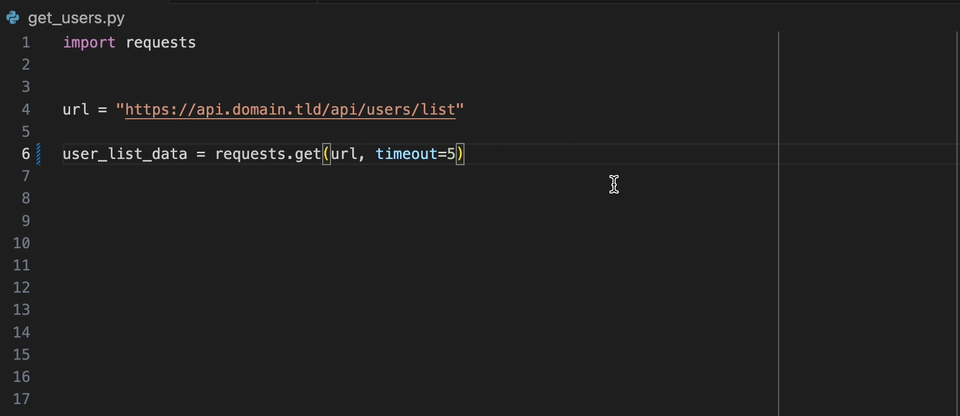
Quando você a bordo do produto Datadog, você pode selecionar o conjunto de regras que deseja/precisa. Se você não estiver usando diretamente o DATADOG, existe a lista de conjuntos de regras usados comuns disponíveis no produto de análise estática do Datadog por idioma.
A lista completa está disponível em nossa documentação.
A lista de conjuntos de regras está disponível no REGRETS.MD.
Faça o download do lançamento mais recente do seu sistema e arquitetura na página de lançamento.
Para obter o analisador estático via Shell:
curl -L -O https://www.github.com/DataDog/datadog-static-analyzer/releases/latest/download/datadog-static-analyzer- < target > .zipExemplo para obter o x86_64 binário para Linux:
curl -L -O https://www.github.com/DataDog/datadog-static-analyzer/releases/latest/download/datadog-static-analyzer-x86_64-unknown-linux-gnu.zipdatadog-static-analyzer -i < directory > -o < output-file > Para que a ferramenta funcione, você deve ter um arquivo <directory>/static-analysis.datadog.yml que define a configuração do analisador. Este arquivo indicará as regras que você usará para o seu projeto.
Você pode obter mais informações sobre a configuração na documentação do Datadog.
O binário não pode ser executado como está. Você precisa sinalizar o binário como seguro para executar usando o seguinte comando.
xattr -dr com.apple.quarantine datadog-static-analyzer-f ou --format : formato do arquivo de saída. -f sarif produz um arquivo compatível com SARIF-r ou --rules : fornece um arquivo que contém todas as regras (as regras podem ser colocadas em um arquivo usando datadog-export-rulesets )-c ou --cpus : Número de núcleos usados para analisar (contagem de cerca de 1 GB de uso de RAM por núcleo)-o ou --output : arquivo de saída-p ou --ignore-path : path (padrão/glob) para ignorar; aceita múltiplo-x ou --performance-statistics : mostre estatísticas de desempenho para o analisador-g ou --add-git-info : adicione informações relacionadas ao Git (SHA, etc) no relatório SARIF ao usar -f Sarif--fail-on-any-violation : faça do programa sair de um código de saída diferente de zero se houver pelo menos uma violação de uma determinada gravidade.-w ou --diff-aware : Ativar digitalização com reconhecimento de difíceis (veja as notas dedicadas abaixo) Defina as seguintes variáveis para configurar uma análise:
DD_SITE : o parâmetro do site datadog usado para buscar regras (visualizar lista) (padrão: datadoghq.com ) O analisador estático pode ser configurado usando um arquivo static-analysis.datadog.yml no diretório raiz do repositório. Este é um arquivo YAML com as seguintes entradas:
rulesets : (exigido) Uma lista com todos os conjuntos de regras a serem usados para este repositório (consulte a documentação do Datadog para obter uma lista completa). Os elementos desta lista devem ser strings ou mapas contendo uma configuração para um conjunto de regras (descrito abaixo).ignore : (Opcional) Uma lista de prefixos de caminho e padrões globais a serem ignorados. Um arquivo que corresponde a qualquer uma de suas entradas não será analisado.only : (Opcional) Uma lista de prefixos de caminho e padrões globais a serem analisados. Se for especificado only , apenas os arquivos que correspondem a uma de suas entradas serão analisados.ignore-gitignore : (Opcional) Por padrão, quaisquer entradas encontradas no arquivo .gitignore são adicionadas à lista ignore . Se a opção ignore-gitignore for verdadeira, o arquivo .gitignore não será lido.max-file-size-kb : (opcional) Arquivos maiores que esse tamanho, em Kilobytes, serão ignorados. O valor padrão é de 200 kb.schema-version : (Opcional) A versão do esquema que este arquivo de configuração segue. Se especificado, deve ser v1 . As entradas da lista de rulesets devem ser seqüências que contêm o nome de um conjunto de regras para ativar ou um mapa que contém a configuração para um conjunto de regras. Este mapa contém os seguintes campos:
ignore : (Opcional) Uma lista de prefixos de caminho e padrões globais a serem ignorados para este conjunto de regras . As regras neste conjunto de regras não serão avaliadas para nenhum arquivo que corresponda a qualquer uma das entradas na lista ignore .only : (Opcional) Uma lista de prefixos de caminho e padrões globais a serem analisados para este conjunto de regras . Se only for especificado, as regras neste conjunto de regras serão avaliadas apenas para arquivos que correspondem a uma das entradas.rules : (Opcional) Um mapa das configurações de regra. As regras não especificadas neste mapa ainda serão avaliadas, mas com a configuração padrão. O mapa no campo rules usa o nome da regra como sua chave, e os valores são mapas com os seguintes campos:
ignore (Opcional) Uma lista de prefixos de caminho e padrões globais a serem ignorados para esta regra . Esta regra não será avaliada para nenhum arquivo que corresponda a qualquer uma das entradas na lista ignore .only : (Opcional) Uma lista de prefixos de caminho e padrões globais a serem analisados para esta regra . Se for especificado only , esta regra será avaliada apenas para arquivos que correspondem a uma das entradas.severity : (opcional) Se fornecido, substitua a gravidade das violações produzidas por esta regra. As severidades válidas são ERROR , WARNING , NOTICE e NONE .category : (Opcional) Se fornecido, substitua a categoria desta regra. As categorias válidas são BEST_PRACTICES , CODE_STYLE , ERROR_PRONE , PERFORMANCE e SECURITY .arguments : (opcional) Um mapa de valores para os argumentos da regra. O mapa no campo arguments usa o nome de um argumento como sua chave, e os valores são strings ou mapas:
Um exemplo anotado de um arquivo de configuração:
# This is a "v1" configuration file.
schema-version : v1
# The list of rulesets to enable for this repository.
rulesets :
# Enable the `python-inclusive` ruleset with the default configuration.
- python-inclusive
# Enable the `python-best-practices` ruleset with a custom configuration.
- python-best-practices :
# Do not apply any of the rules in this ruleset to files that match `src/**/*.generated.py`.
ignore :
- src/**/*.generated.py
rules :
# Special configuration for the `python-best-practices/no-generic-exception` rule.
no-generic-exception :
# Treat violations of this rule as errors (normally "notice").
severity : ERROR
# Classify violations of this rule under the "code style" category.
category : CODE_STYLE
# Only apply this rule to files under the `src/new-code` subtree.
only :
- src/new-code
# Enable the `python-code-style ruleset` with a custom configuration.
- python-code-style :
rules :
max-function-lines :
# Set arguments for the `python-code-style/max-function-lines` rule.
arguments :
# Set the `max-lines` argument to 150 in the whole repository.
max-lines : 150
max-class-lines :
# Set arguments for the `python-code-style/max-class-lines` rule.
arguments :
# Set different values for the `max-lines` argument in different subtrees.
max-lines :
# Set the `max-lines` argument to 100 by default
/ : 100
# Set the `max-lines` argument to 75 under the `src/new-code` subtree.
src/new-code : 75
# Analyze only files in the `src` and `imported` subtrees.
only :
- src
- imported
# Do not analyze any files in the `src/tests` subtree.
ignore :
- src/tests
# Do not add the content of the `.gitignore` file to the `ignore` list.
ignore-gitignore : true
# Do not analyze files larger than 100 kB.
max-file-size-kb : 100Outro exemplo que mostra todas as opções sendo usadas:
schema-version : v1
rulesets :
- python-best-practices
- python-code-style :
ignore :
- src/generated
- src/**/*_test.py
only :
- src
- imported/**/new/**
rules :
max-function-lines :
severity : WARNING
category : PERFORMANCE
ignore :
- src/new-code
- src/new/*.gen.py
only :
- src/new
- src/**/new-code/**
arguments :
max-lines : 150
min-lines :
/ : 10
src/new-code : 0
ignore :
- dist
- lib/**/*.py
only :
- src
- imported/**/*.py
ignore-gitignore : true
max-file-size-kb : 256 Existe uma definição de esquema JSON para a static-analysis.datadog.yml no subdiretório schema .
Você pode usá -lo para verificar a sintaxe do seu arquivo de configuração:
npm install -g pajv )pajv validate -s schema/schema.json -d path/to/your/static-analysis.datadog.yml Existem alguns exemplos de arquivos de configuração válidos e inválidos nos schema/examples/valid e subdiretos schema/examples/invalid , respectivamente. Se você fizer alterações no esquema JSON, poderá testá -las em relação aos nossos exemplos:
npm install -g pajv )make -C schema A varredura com reconhecimento de difíceis é uma característica do analisador estático para digitalizar apenas os arquivos que foram alterados recentemente. As varreduras com reconhecimento de difíceis usam resultados anteriores e adicionam apenas as violações dos arquivos alterados.
Para usar a digitalização com reconhecimento de difíceis, você deve ser um cliente Datadog.
Para usar a digitalização com reconhecimento de difíceis:
DD_SITE de acordo com o datadog datacenter que você está usando (https://docs.datadoghq.com/getting_started/site/)DD_APP_KEY e DD_API_KEY com seu aplicativo Datadog e chaves de API--diff-awareAo usar consciência do Diff, o analisador estático se conectará ao Datadog e tentará uma análise anterior para usar. Se ocorrer algum problema e não puderem ser utilizados, o analisador produzirá um erro como o abaixo e continuará com uma varredura completa.
Você pode usar a opção --debug true para solucionar mais problemas, se necessário.
$ datadog-static-analyzer --directory /path/to/code --output output.sarif --format sarif --diff-aware
...
diff aware not enabled (error when receiving diff-aware data from Datadog with config hash 16163d87d4a1922ab89ec891159446d1ce0fb47f9c1469448bb331b72d19f55c, sha 5509900dc490cedbe2bb64afaf43478e24ad144b), proceeding with full scan.
...Regras de exportação da API para um arquivo
cargo run --bin datadog-export-rulesets -- -r < ruleset > -o < file-to-export > Consulte o arquivo contribuiing.md para obter mais informações, bem como desenvolvimento.md para obter todos os detalhes sobre as diretrizes de teste e codificação.


