datadog static analyzer
0.5.2
Conseil
Datadog prend en charge les projets open source. En savoir plus sur Datadog pour les projets open source.
Datadog-Static-Analyzer est le moteur de l'analyseur statique pour l'analyse statique de Datadog.
datadog-static-analyzer --directory /path/to/directory --output report.csv --format csvdocker run -it --rm -v /path/to/directory:/data ghcr.io/datadog/datadog-static-analyzer:latest --directory /data --output /data/report.csv --format csvPour plus d'informations sur le conteneur Docker, consultez la documentation ici.
Si vous rencontrez un problème, lisez d'abord les questions fréquemment posées, elle peut contenir la solution à votre problème.
Vous pouvez choisir les règles à utiliser pour scanner votre référentiel en créant un fichier static-analysis.datadog.yml .
Tout d'abord, assurez-vous de suivre la documentation et de créer un fichier static-analysis.datadog.yml à la racine de votre projet avec les ensembles de règles que vous souhaitez utiliser.
Toutes les règles peuvent être trouvées sur la documentation de la forme de données. Votre static-analysis.datadog.yml ne peut contenir que des ensembles de règles disponibles à partir de la documentation de la forme de données
Exemple de fichier yaml
schema-version : v1
rulesets :
- python-code-style
- python-best-practices
- python-inclusive
ignore :
- testsVous pouvez l'utiliser dans votre pipeline CI / CD en utilisant notre intégration:
Si vous l'utilisez dans votre propre pipeline CI / CD, vous pouvez intégrer directement l'outil: consultez la documentation de la société de données pour plus d'informations.
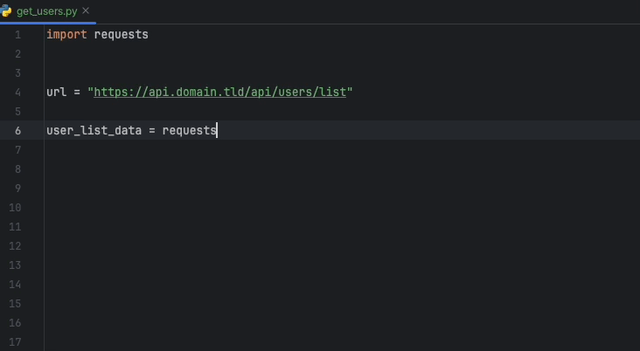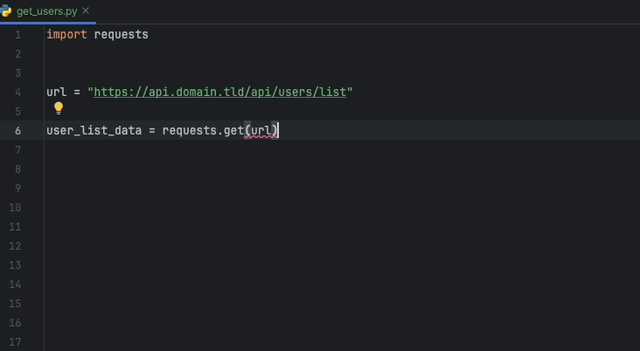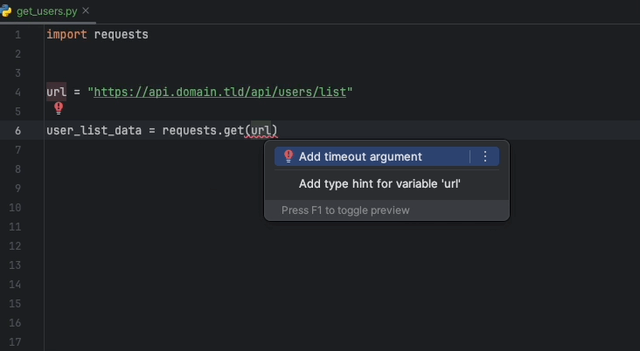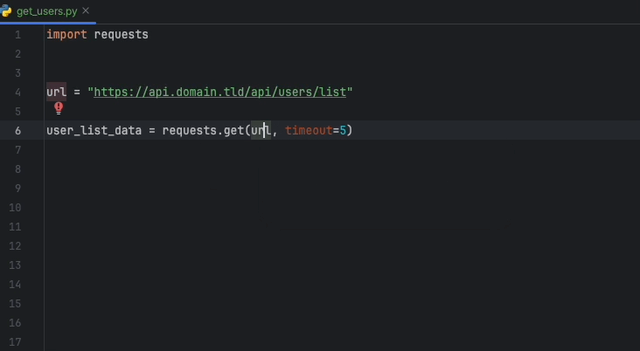
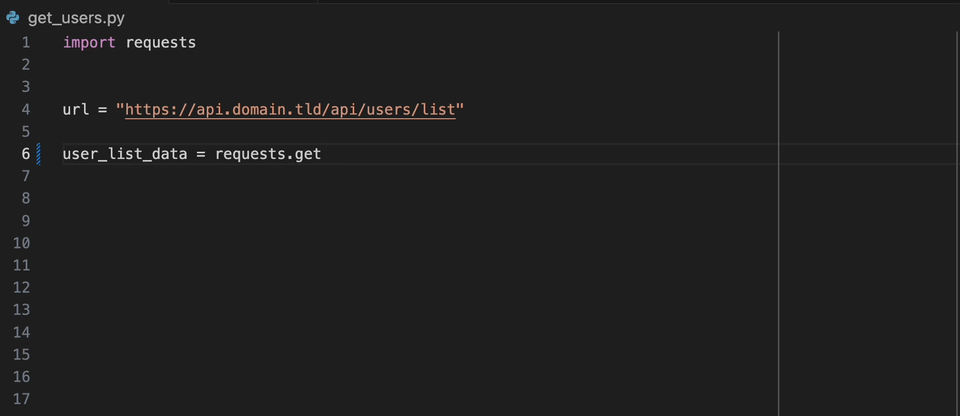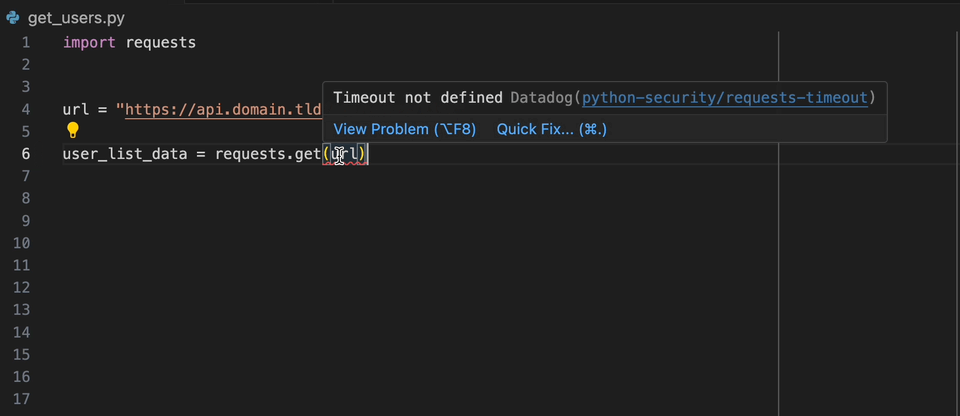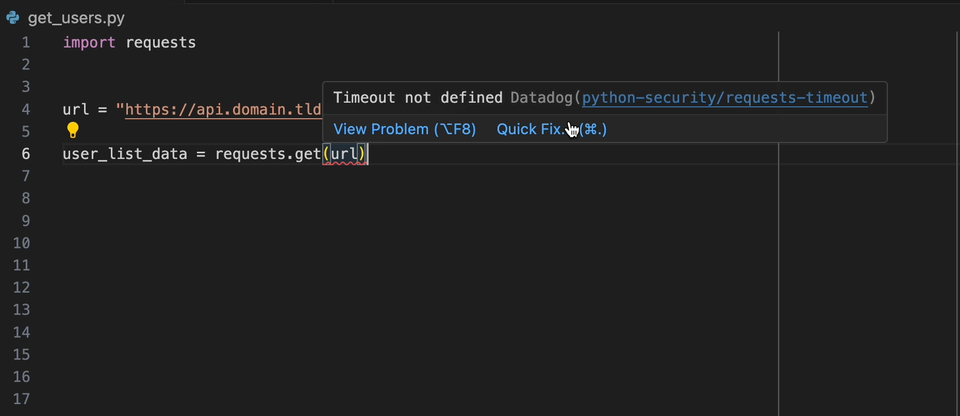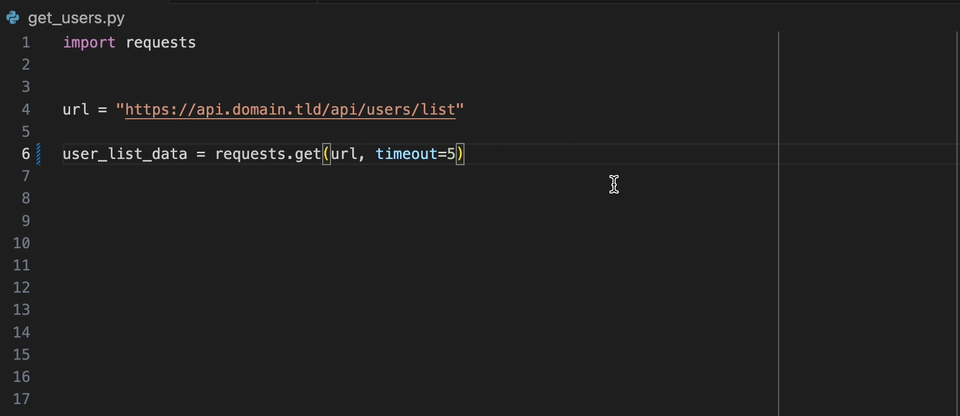
L'extension Datadog IntelliJ vous permet d'utiliser l'analyseur statique directement à partir de tous les produits JetBrains. Créez un fichier static-analysis.datadog.yml , téléchargez l'extension et vous pouvez commencer à l'utiliser. Vous pouvez voir ci-dessous un exemple de suggestion pour ajouter un délai d'expiration lors de la récupération de données avec Python avec le module Demandes.
L'extension Datadog vs Code vous permet d'utiliser l'analyseur statique directement à partir du code vs. Créez un fichier static-analysis.datadog.yml , téléchargez l'extension et vous pouvez commencer à l'utiliser.
Lorsque vous embarquez sur le produit Datadog, vous pouvez sélectionner l'ensemble de règles que vous souhaitez / avez besoin. Si vous n'utilisez pas directement Datadog, il existe la liste des ensembles de règles utilisés communs disponibles dans le produit d'analyse statique de Datadog par langue.
La liste complète est disponible dans notre documentation.
La liste des ensembles de règles est disponible dans RuleSet.md.
Téléchargez la dernière version de votre système et de votre architecture à partir de la page de version.
Pour obtenir l'analyseur statique via Shell:
curl -L -O https://www.github.com/DataDog/datadog-static-analyzer/releases/latest/download/datadog-static-analyzer- < target > .zipExemple pour obtenir le binaire x86_64 pour Linux:
curl -L -O https://www.github.com/DataDog/datadog-static-analyzer/releases/latest/download/datadog-static-analyzer-x86_64-unknown-linux-gnu.zipdatadog-static-analyzer -i < directory > -o < output-file > Pour que l'outil fonctionne, vous devez disposer d'un fichier <directory>/static-analysis.datadog.yml qui définit la configuration de l'analyseur. Ce fichier indiquera les règles que vous utiliserez pour votre projet.
Vous pouvez obtenir plus d'informations sur la configuration de la documentation de la forme de données.
Le binaire ne peut pas être exécuté tel quel. Vous devez signaler le binaire comme sûr à exécuter en utilisant la commande suivante.
xattr -dr com.apple.quarantine datadog-static-analyzer-f ou --format : format du fichier de sortie. -f sarif produit un fichier conforme à Sarif-r ou --rules : fournit un fichier qui contient toutes les règles (les règles peuvent être établies dans un fichier à l'aide de datadog-export-rulesets )-c ou --cpus : Nombre de noyaux utilisés pour analyser (compter environ 1 Go d'utilisation de la RAM par noyau)-o ou --output : fichier de sortie-p ou --ignore-path : chemin (modèle / glob) à ignorer; accepte plusieurs-x ou --performance-statistics : montrent des statistiques de performance pour l'analyseur-g ou --add-git-info : ajouter des informations liées à Git (sha, etc.) dans le rapport Sarif lors de l'utilisation de -f Sarif--fail-on-any-violation : faire sortir le programme un code de sortie non nul s'il y a au moins une violation d'une gravité donnée.-w ou --diff-aware : Activer la numérisation de difficulté (voir les notes dédiées ci-dessous) Définissez les variables suivantes pour configurer une analyse:
DD_SITE : Le paramètre du site de la forme de données utilisé pour récupérer les règles (Afficher la liste) (par défaut: datadoghq.com ) L'analyseur statique peut être configuré à l'aide d'un fichier static-analysis.datadog.yml au répertoire racine du référentiel. Il s'agit d'un fichier YAML avec les entrées suivantes:
rulesets : (Obligatoire) Une liste avec tous les ensembles de règles à utiliser pour ce référentiel (voir la documentation de la forme de données pour une liste complète). Les éléments de cette liste doivent être des chaînes ou des cartes contenant une configuration pour un ensemble de règles (décrit ci-dessous.)ignore : (facultatif) Une liste des préfixes de chemin et des modèles globaux à ignorer. Un fichier qui correspond à aucune de ses entrées ne sera pas analysé.only : (facultatif) une liste des préfixes de chemin et des modèles de glob pour analyser. S'il est only spécifié, seuls les fichiers qui correspondent à l'une de ses entrées seront analysés.ignore-gitignore : (Facultatif) Par défaut, toutes les entrées trouvées dans le fichier .gitignore sont ajoutées à la liste ignore . Si l'option ignore-gitignore est vraie, le fichier .gitignore n'est pas lu.max-file-size-kb : (facultatif) Les fichiers supérieurs à cette taille, en kilo-dérivation, seront ignorés. La valeur par défaut est de 200 Ko.schema-version : (facultatif) La version du schéma que ce fichier de configuration suit. S'il est spécifié, il doit être v1 . Les entrées de la liste rulesets doivent être des chaînes contenant le nom d'un ensemble de règles à activer, ou une carte qui contient la configuration d'un ensemble de règles. Cette carte contient les champs suivants:
ignore : (facultatif) Une liste des préfixes de chemin et des modèles globaux à ignorer pour cet ensemble de règles . Les règles de cet ensemble de règles ne seront pas évaluées pour les fichiers qui correspondent à l'une des entrées de la liste ignore .only : (facultatif) une liste des préfixes de chemin et des modèles globaux à analyser pour cet ensemble de règles . S'il est only spécifié, les règles de cet ensemble de règles ne seront évaluées que pour les fichiers qui correspondent à l'une des entrées.rules : (facultative) Une carte des configurations de règles. Les règles non spécifiées dans cette carte seront toujours évaluées, mais avec leur configuration par défaut. La carte du champ rules utilise le nom de la règle comme clé, et les valeurs sont des cartes avec les champs suivants:
ignore (facultatif) une liste des préfixes de chemin et des modèles globaux à ignorer pour cette règle . Cette règle ne sera pas évaluée pour aucun fichier qui correspond à l'une des entrées de la liste ignore .only : (facultatif) une liste des préfixes de chemin et des modèles globaux à analyser pour cette règle . Si only est spécifié, cette règle ne sera évaluée que pour les fichiers qui correspondent à l'une des entrées.severity : (facultatif) Si prévu, remplacez la gravité des violations produites par cette règle. Les graves valides sont ERROR , WARNING , NOTICE et NONE .category : (facultatif) Si prévu, remplacez la catégorie de cette règle. Les catégories valides sont BEST_PRACTICES , CODE_STYLE , ERROR_PRONE , PERFORMANCE et SECURITY .arguments : (facultatif) Une carte des valeurs pour les arguments de la règle. La carte du champ arguments utilise le nom d'un argument comme clé, et les valeurs sont soit des chaînes ou des cartes:
Un exemple annoté d'un fichier de configuration:
# This is a "v1" configuration file.
schema-version : v1
# The list of rulesets to enable for this repository.
rulesets :
# Enable the `python-inclusive` ruleset with the default configuration.
- python-inclusive
# Enable the `python-best-practices` ruleset with a custom configuration.
- python-best-practices :
# Do not apply any of the rules in this ruleset to files that match `src/**/*.generated.py`.
ignore :
- src/**/*.generated.py
rules :
# Special configuration for the `python-best-practices/no-generic-exception` rule.
no-generic-exception :
# Treat violations of this rule as errors (normally "notice").
severity : ERROR
# Classify violations of this rule under the "code style" category.
category : CODE_STYLE
# Only apply this rule to files under the `src/new-code` subtree.
only :
- src/new-code
# Enable the `python-code-style ruleset` with a custom configuration.
- python-code-style :
rules :
max-function-lines :
# Set arguments for the `python-code-style/max-function-lines` rule.
arguments :
# Set the `max-lines` argument to 150 in the whole repository.
max-lines : 150
max-class-lines :
# Set arguments for the `python-code-style/max-class-lines` rule.
arguments :
# Set different values for the `max-lines` argument in different subtrees.
max-lines :
# Set the `max-lines` argument to 100 by default
/ : 100
# Set the `max-lines` argument to 75 under the `src/new-code` subtree.
src/new-code : 75
# Analyze only files in the `src` and `imported` subtrees.
only :
- src
- imported
# Do not analyze any files in the `src/tests` subtree.
ignore :
- src/tests
# Do not add the content of the `.gitignore` file to the `ignore` list.
ignore-gitignore : true
# Do not analyze files larger than 100 kB.
max-file-size-kb : 100Un autre exemple qui montre toutes les options utilisées:
schema-version : v1
rulesets :
- python-best-practices
- python-code-style :
ignore :
- src/generated
- src/**/*_test.py
only :
- src
- imported/**/new/**
rules :
max-function-lines :
severity : WARNING
category : PERFORMANCE
ignore :
- src/new-code
- src/new/*.gen.py
only :
- src/new
- src/**/new-code/**
arguments :
max-lines : 150
min-lines :
/ : 10
src/new-code : 0
ignore :
- dist
- lib/**/*.py
only :
- src
- imported/**/*.py
ignore-gitignore : true
max-file-size-kb : 256 Il existe une définition de schéma JSON pour l' static-analysis.datadog.yml dans le sous-répertoire schema .
Vous pouvez l'utiliser pour vérifier la syntaxe de votre fichier de configuration:
npm install -g pajv )pajv validate -s schema/schema.json -d path/to/your/static-analysis.datadog.yml Il existe quelques exemples de fichiers de configuration valides et non valides dans le schema/examples/valid et schema/examples/invalid , respectivement. Si vous apportez des modifications au schéma JSON, vous pouvez les tester contre nos exemples:
npm install -g pajv )make -C schema La numérisation de Difff-Aware est une caractéristique de l'analyseur statique pour scanner uniquement les fichiers qui ont été récemment modifiés. Les analyses de Difff-Aware utilisent les résultats précédents et ajoutent uniquement les violations des fichiers modifiés.
Afin d'utiliser la numérisation conscient de Diff, vous devez être un client Datadog.
Pour utiliser la numérisation conscient de DIFF:
DD_SITE Selon le Datadog Datacenter que vous utilisez (https://docs.datadoghq.com/getting_started/site/)DD_APP_KEY et DD_API_KEY avec votre application Datadog et les touches API--diff-awareLorsque vous utilisez DIFF-AWARE, l'analyseur statique se connectera à Datadog et tentera une analyse précédente à utiliser. Si un problème se produit et que Diff-Aware ne peut pas être utilisé, l'analyseur publiera une erreur comme celle ci-dessous et continuera avec une analyse complète.
Vous pouvez utiliser l'option --debug true pour dépanner davantage si nécessaire.
$ datadog-static-analyzer --directory /path/to/code --output output.sarif --format sarif --diff-aware
...
diff aware not enabled (error when receiving diff-aware data from Datadog with config hash 16163d87d4a1922ab89ec891159446d1ce0fb47f9c1469448bb331b72d19f55c, sha 5509900dc490cedbe2bb64afaf43478e24ad144b), proceeding with full scan.
...Exporter des ensembles de règles de l'API dans un fichier
cargo run --bin datadog-export-rulesets -- -r < ruleset > -o < file-to-export > Voir le fichier contributing.md pour plus d'informations ainsi que Development.md pour tous les détails sur les tests de test et de codage.


