datadog static analyzer
0.5.2
Tipp
Datadog unterstützt Open Source -Projekte. Erfahren Sie mehr über Datadog für Open -Source -Projekte.
Datadog-Static-Analyzer ist die statische Analysator-Engine für die statische Datadog-Analyse.
datadog-static-analyzer --directory /path/to/directory --output report.csv --format csvdocker run -it --rm -v /path/to/directory:/data ghcr.io/datadog/datadog-static-analyzer:latest --directory /data --output /data/report.csv --format csvWeitere Informationen zum Docker -Container finden Sie in der Dokumentation hier.
Wenn Sie auf ein Problem stoßen, lesen Sie zuerst die häufig gestellten Fragen, und kann die Lösung für Ihr Problem enthalten.
Sie können die Regeln auswählen, mit denen Sie Ihr Repository scannen sollen, indem Sie eine static-analysis.datadog.yml erstellen.Datadog.yml-Datei.
Stellen Sie zunächst sicher, dass Sie die Dokumentation befolgen und eine static-analysis.datadog.yml erstellen.
Alle Regeln finden Sie in der Datadog -Dokumentation. Ihre static-analysis.datadog.yml kann nur Regeln enthalten
Beispiel für die YAML -Datei
schema-version : v1
rulesets :
- python-code-style
- python-best-practices
- python-inclusive
ignore :
- testsMit unserer Integration können Sie es in Ihrer CI/CD -Pipeline verwenden:
Wenn Sie es in Ihrer eigenen CI/CD -Pipeline verwenden, können Sie das Tool direkt integrieren: Weitere Informationen finden Sie in der Datadog -Dokumentation.
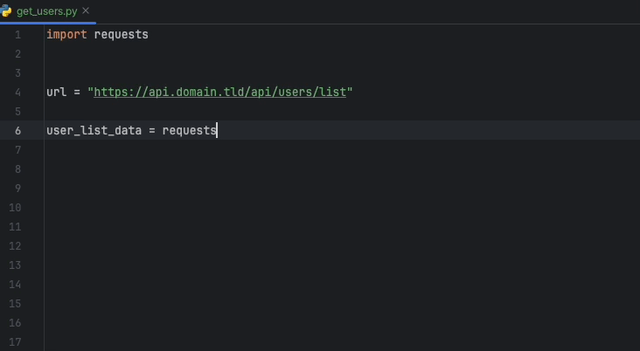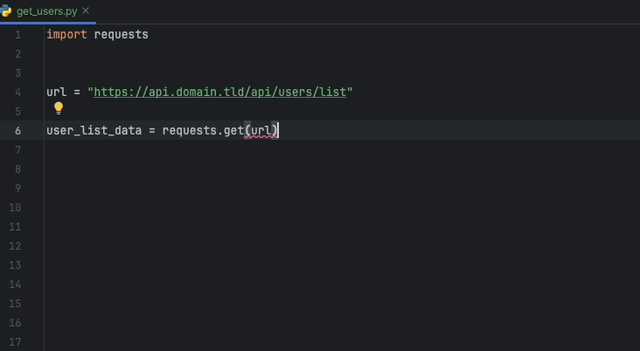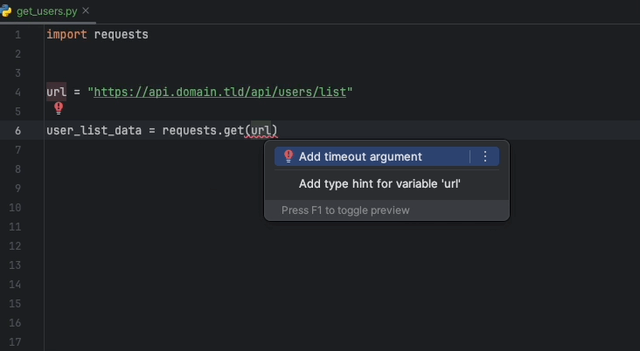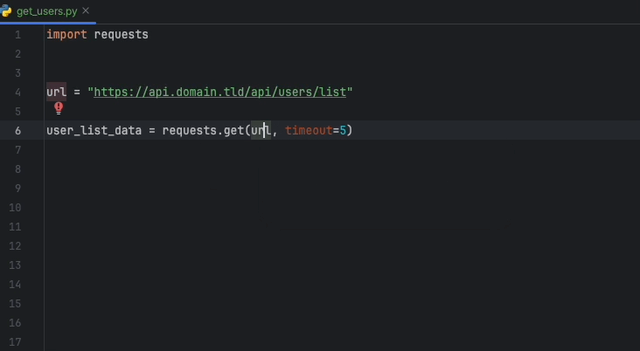
Mit der Datadog Intellij -Erweiterung können Sie den statischen Analysator direkt aus allen JetBrains -Produkten verwenden. Erstellen Sie eine static-analysis.datadog.yml -Datei, laden Sie die Erweiterung herunter und Sie können sie verwenden. Nachfolgend sehen Sie einen Beispiel für einen Vorschlag, beim Abholen von Daten mit Python mit dem Request -Modul eine Zeitüberschreitung hinzuzufügen.
Mit dem Datadog vs -Code -Erweiterung können Sie den statischen Analysator direkt aus dem VS -Code verwenden. Erstellen Sie eine static-analysis.datadog.yml -Datei, laden Sie die Erweiterung herunter und Sie können sie verwenden.
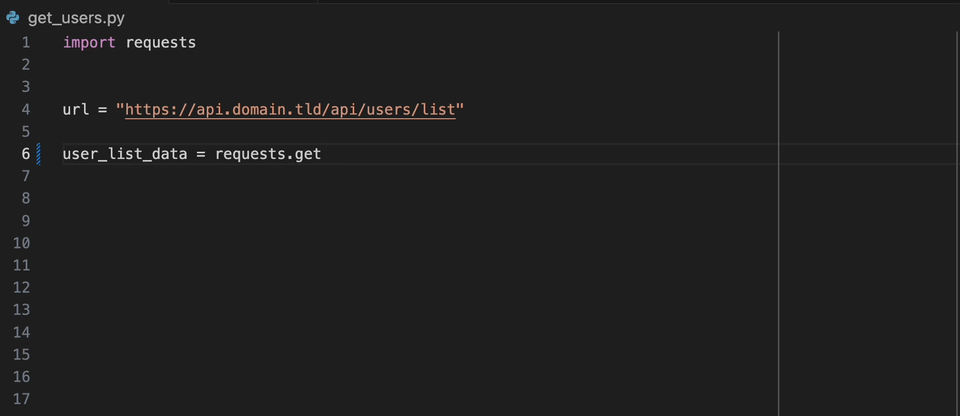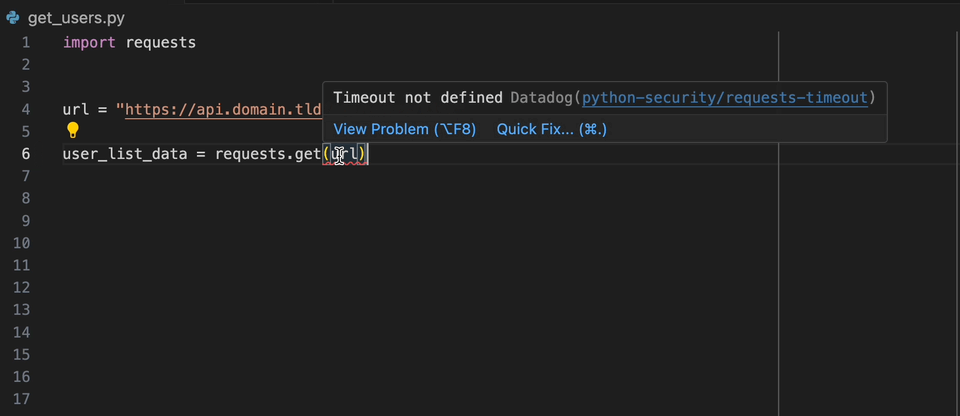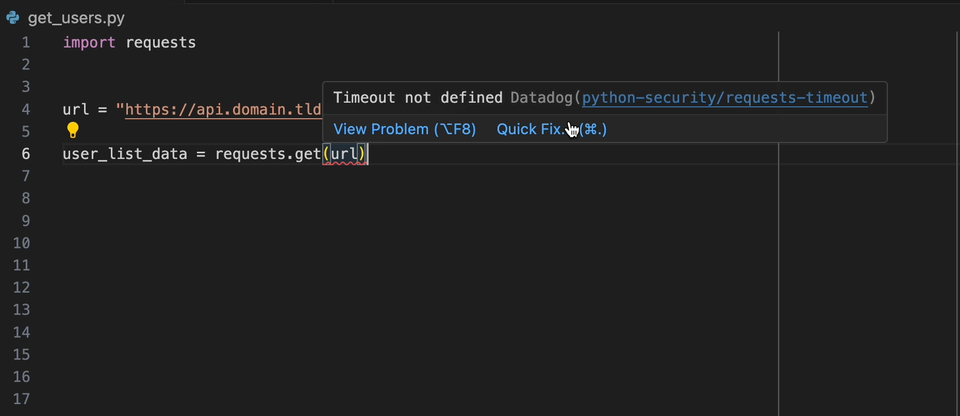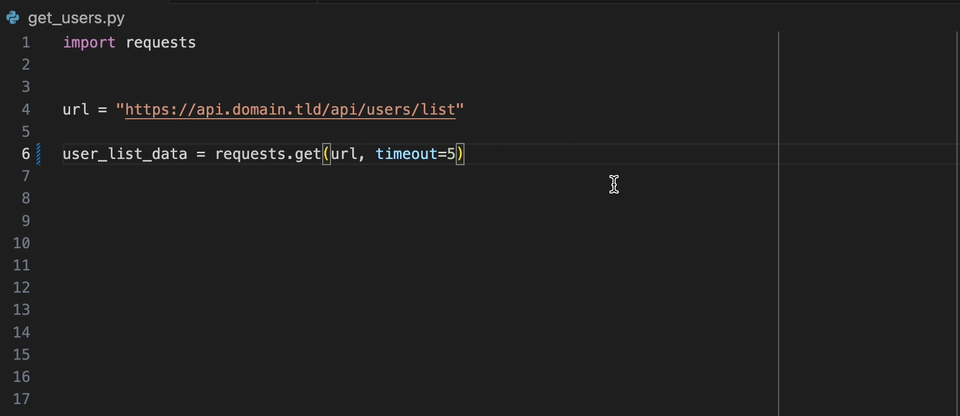
Wenn Sie an Bord des Datadog -Produkts an Bord sind, können Sie den gewünschten Regeln auswählen/benötigen. Wenn Sie Datadog nicht direkt verwenden, gibt es die Liste der gängigen verwendeten Regeln im Produkt der statischen Analyse von Datadog pro Sprache.
Die vollständige Liste ist in unserer Dokumentation verfügbar.
Die Liste der Regeln ist in Rulets.md verfügbar.
Laden Sie die neueste Version für Ihr System und Ihre Architektur von der Release -Seite herunter.
Um den statischen Analysator über Shell zu erhalten:
curl -L -O https://www.github.com/DataDog/datadog-static-analyzer/releases/latest/download/datadog-static-analyzer- < target > .zipBeispiel, um den x86_64 -Binär für Linux zu erhalten:
curl -L -O https://www.github.com/DataDog/datadog-static-analyzer/releases/latest/download/datadog-static-analyzer-x86_64-unknown-linux-gnu.zipdatadog-static-analyzer -i < directory > -o < output-file > Damit das Tool funktioniert, müssen Sie eine <directory>/static-analysis.datadog.yml haben, die die Konfiguration des Analysators definiert. Diese Datei gibt die Regeln an, die Sie für Ihr Projekt verwenden.
Weitere Informationen zur Konfiguration in der Datadog -Dokumentation erhalten Sie.
Der Binärdatum kann nicht so ausgeführt werden wie er ist. Sie müssen die Binärdatoren als sicher mit dem folgenden Befehl ausführen.
xattr -dr com.apple.quarantine datadog-static-analyzer-f oder --format : Format der Ausgabedatei. -f sarif produziert eine Sarif-konforme Datei-r oder --rules : Enthält eine Datei, die alle Regeln enthält (Regeln können in eine Datei mit datadog-export-rulesets in eine Datei eingefügt werden).-c oder --cpus : Anzahl der zur Analyse verwendeten Kerne (zählen Sie etwa 1 GB RAM -Nutzung pro Kern)-o oder --output : Ausgabedatei-p oder --ignore-path : Pfad (Muster/Glob) zu ignorieren; Akzeptiert mehrere-x oder --performance-statistics : Zeigen Sie Leistungsstatistiken für den Analysator-g oder --add-git-info : Fügen Sie GIT-bezogene Informationen (SHA usw.) in den SARIF-Bericht bei der Verwendung -f Sarif hinzu--fail-on-any-violation : Machen Sie das Programm, das einen Exit-Code ungleich Null beendet, wenn mindestens ein Verstoß gegen einen bestimmten Schweregrad vorliegt.-w oder --diff-aware : Aktivieren Sie das diff-bewusstes Scannen (siehe dedizierte Notizen unten) Legen Sie die folgenden Variablen fest, um eine Analyse zu konfigurieren:
DD_SITE : Der Datadog -Site -Parameter, der zum Abrufen von Regeln verwendet wird (Ansichtsliste) (Standardeinstellung: datadoghq.com ) Der statische Analysator kann mit einer static-analysis.datadog.yml konfiguriert werden. Dies ist eine YAML -Datei mit den folgenden Einträgen:
rulesets : (Erforderlich) Eine Liste mit allen für dieses Repository verwendeten Regeln (siehe DOTADOG -Dokumentation für eine vollständige Liste). Die Elemente dieser Liste müssen Zeichenfolgen oder Karten sein, die eine Konfiguration für einen Regeln enthalten (nachstehend beschrieben).ignore : (optional) Eine Liste von Pfadpräfixen und Glob -Mustern zu ignorieren. Eine Datei, die einer seiner Einträge entspricht, wird nicht analysiert.only : (optional) Eine Liste von Pfadpräfixen und Glob -Mustern zu analysieren. Wenn only angegeben ist, werden nur Dateien analysiert, die einem seiner Einträge übereinstimmen.ignore-gitignore : (optional) standardmäßig werden alle Einträge, die in der Datei .gitignore gefunden wurden, zur ignore hinzugefügt. Wenn die Option ignore-gitignore Option wahr ist, wird die .gitignore Datei nicht gelesen.max-file-size-kb : (optionale) Dateien größer als diese Größe in Kilobytes werden ignoriert. Der Standardwert beträgt 200 kb.schema-version : (optional) Die Version des Schemas, dem diese Konfigurationsdatei folgt. Wenn angegeben, muss es v1 sein. Die Einträge der Liste rulesets müssen Zeichenfolgen sein, die den Namen eines Rulesets zu aktivieren, oder eine Karte, die die Konfiguration für einen Regeln enthält. Diese Karte enthält die folgenden Felder:
ignore : (optional) Eine Liste von Pfadpräfixen und Glob -Mustern, die für diesen Regeln ignoriert werden können. Die Regeln in diesem Regeln werden nicht für Dateien bewertet, die den Einträgen in der Liste ignore übereinstimmen.only : (optional) Eine Liste von Pfadpräfixen und Glob -Mustern, die für diesen Regeln analysiert werden sollen. Wenn only angegeben ist, werden die Regeln in diesem Regeln nur für Dateien bewertet, die einem der Einträge entsprechen.rules : (optional) Eine Karte der Regelkonfigurationen. Die in dieser Karte nicht angegebenen Regeln werden weiterhin bewertet, sondern mit ihrer Standardkonfiguration. Die Karte im Feld rules verwendet den Namen der Regel als Schlüssel, und die Werte sind Karten mit den folgenden Feldern:
ignore (optional) eine Liste von Pfadpräfixen und Glob -Mustern, um diese Regel zu ignorieren. Diese Regel wird nicht für Dateien bewertet, die den Einträgen in der Liste ignore übereinstimmen.only : (optional) Eine Liste von Pfadpräfixen und Glob -Mustern, die für diese Regel analysiert werden sollen. Wenn only angegeben ist, wird diese Regel nur für Dateien bewertet, die einem der Einträge übereinstimmen.severity : (optional) Wenn angegeben, überschreiben Sie die Schwere der durch diese Regel erzeugten Verstöße. Die gültigen Schweregrad sind ERROR , WARNING , NOTICE und NONE .category : (optional) Wenn angegeben, überschreiben Sie die Kategorie dieser Regel. Die gültigen Kategorien sind BEST_PRACTICES , CODE_STYLE , ERROR_PRONE , PERFORMANCE und SECURITY .arguments : (optional) Eine Karte von Werten für die Argumente der Regel. Die Karte im Feld arguments verwendet den Namen eines Arguments als Schlüssel, und die Werte sind entweder Zeichenfolgen oder Karten:
Ein kommentiertes Beispiel einer Konfigurationsdatei:
# This is a "v1" configuration file.
schema-version : v1
# The list of rulesets to enable for this repository.
rulesets :
# Enable the `python-inclusive` ruleset with the default configuration.
- python-inclusive
# Enable the `python-best-practices` ruleset with a custom configuration.
- python-best-practices :
# Do not apply any of the rules in this ruleset to files that match `src/**/*.generated.py`.
ignore :
- src/**/*.generated.py
rules :
# Special configuration for the `python-best-practices/no-generic-exception` rule.
no-generic-exception :
# Treat violations of this rule as errors (normally "notice").
severity : ERROR
# Classify violations of this rule under the "code style" category.
category : CODE_STYLE
# Only apply this rule to files under the `src/new-code` subtree.
only :
- src/new-code
# Enable the `python-code-style ruleset` with a custom configuration.
- python-code-style :
rules :
max-function-lines :
# Set arguments for the `python-code-style/max-function-lines` rule.
arguments :
# Set the `max-lines` argument to 150 in the whole repository.
max-lines : 150
max-class-lines :
# Set arguments for the `python-code-style/max-class-lines` rule.
arguments :
# Set different values for the `max-lines` argument in different subtrees.
max-lines :
# Set the `max-lines` argument to 100 by default
/ : 100
# Set the `max-lines` argument to 75 under the `src/new-code` subtree.
src/new-code : 75
# Analyze only files in the `src` and `imported` subtrees.
only :
- src
- imported
# Do not analyze any files in the `src/tests` subtree.
ignore :
- src/tests
# Do not add the content of the `.gitignore` file to the `ignore` list.
ignore-gitignore : true
# Do not analyze files larger than 100 kB.
max-file-size-kb : 100Ein weiteres Beispiel, in dem jede Option verwendet wird:
schema-version : v1
rulesets :
- python-best-practices
- python-code-style :
ignore :
- src/generated
- src/**/*_test.py
only :
- src
- imported/**/new/**
rules :
max-function-lines :
severity : WARNING
category : PERFORMANCE
ignore :
- src/new-code
- src/new/*.gen.py
only :
- src/new
- src/**/new-code/**
arguments :
max-lines : 150
min-lines :
/ : 10
src/new-code : 0
ignore :
- dist
- lib/**/*.py
only :
- src
- imported/**/*.py
ignore-gitignore : true
max-file-size-kb : 256 Es gibt eine JSON-Schema schema Definition für die static-analysis.datadog.yml .
Sie können es verwenden, um die Syntax Ihrer Konfigurationsdatei zu überprüfen:
npm install -g pajv )pajv validate -s schema/schema.json -d path/to/your/static-analysis.datadog.yml Es gibt einige Beispiele für gültige und ungültige Konfigurationsdateien im schema/examples/valid und schema/examples/invalid Unterverzeichnissen. Wenn Sie Änderungen am JSON -Schema vornehmen, können Sie sie anhand unserer Beispiele testen:
npm install -g pajv )make -C schema Das Differital-Scaning ist eine Funktion des statischen Analysators, um nur die kürzlich geänderten Dateien zu scannen. Diff-gesetzliche Scans verwenden frühere Ergebnisse und fügen nur die Verstöße aus den geänderten Dateien hinzu.
Um das diff-bewusstes Scannen zu verwenden, müssen Sie ein Datadog-Kunde sein.
Um diff-bewusstes Scannen zu verwenden:
DD_SITE gemäß dem von Ihnen verwendeten DataDog -DataCenter ein (https://docs.datadoghq.com/getting_started/site/)DD_APP_KEY und DD_API_KEY mit Ihren Datadog -Anwendungs- und API -Tasten ein--diff-awareBei der Verwendung von Diff-Awesare wird der statische Analysator eine Verbindung zu Datadog herstellen und eine frühere Analyse zur Verwendung versucht. Wenn ein Problem auftritt und Diff-bewusst nicht verwendet werden kann, gibt der Analysator einen Fehler aus, wie der folgende und fährt mit einem vollständigen Scan fort.
Sie können die Option verwenden --debug true um bei Bedarf weiter zu beheben.
$ datadog-static-analyzer --directory /path/to/code --output output.sarif --format sarif --diff-aware
...
diff aware not enabled (error when receiving diff-aware data from Datadog with config hash 16163d87d4a1922ab89ec891159446d1ce0fb47f9c1469448bb331b72d19f55c, sha 5509900dc490cedbe2bb64afaf43478e24ad144b), proceeding with full scan.
...Exportieren Sie die Regeln aus der API in eine Datei
cargo run --bin datadog-export-rulesets -- -r < ruleset > -o < file-to-export > Weitere Informationen zum Testen und Codierungsrichtlinien finden Sie unter der Datei beitragen.md für weitere Informationen und Entwicklung.md.


