HeaderGen
1.0.0

Headergen é uma abordagem baseada em ferramentas para aprimorar a compreensão e navegação de notebooks Jupyter baseados em Python sem documentos, criando automaticamente uma estrutura narrativa no notebook.
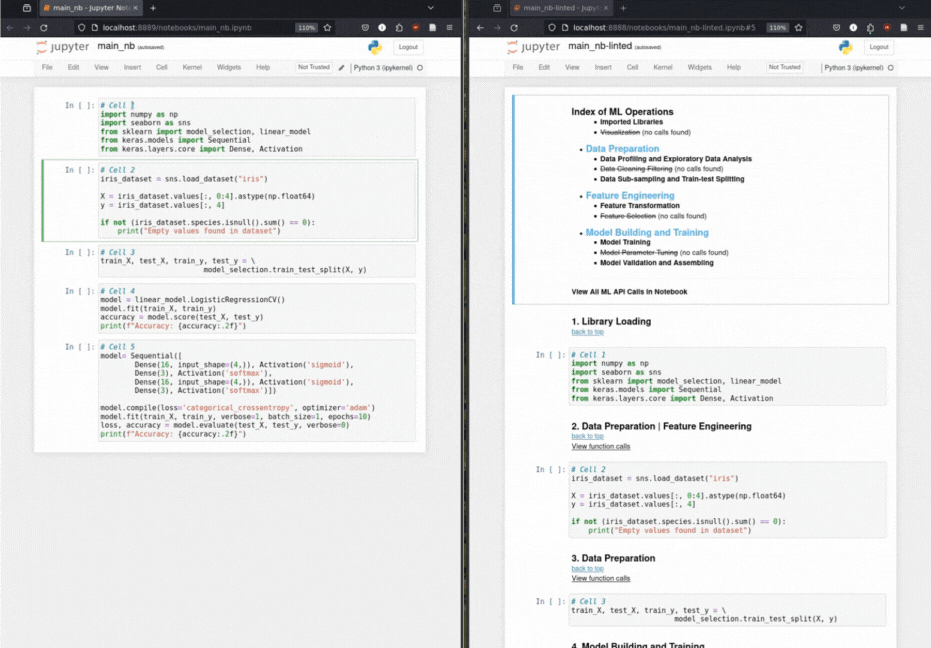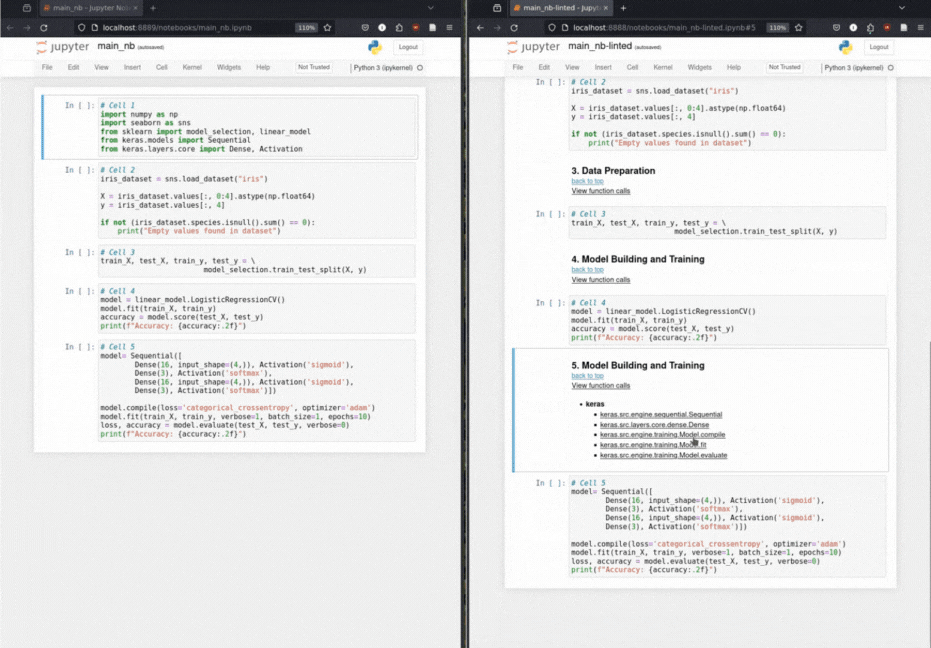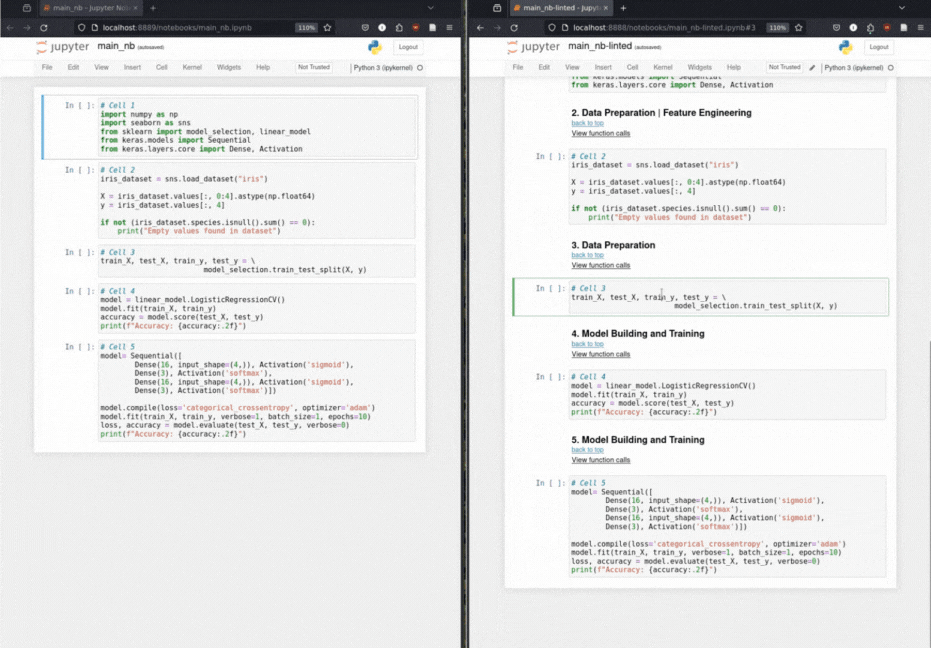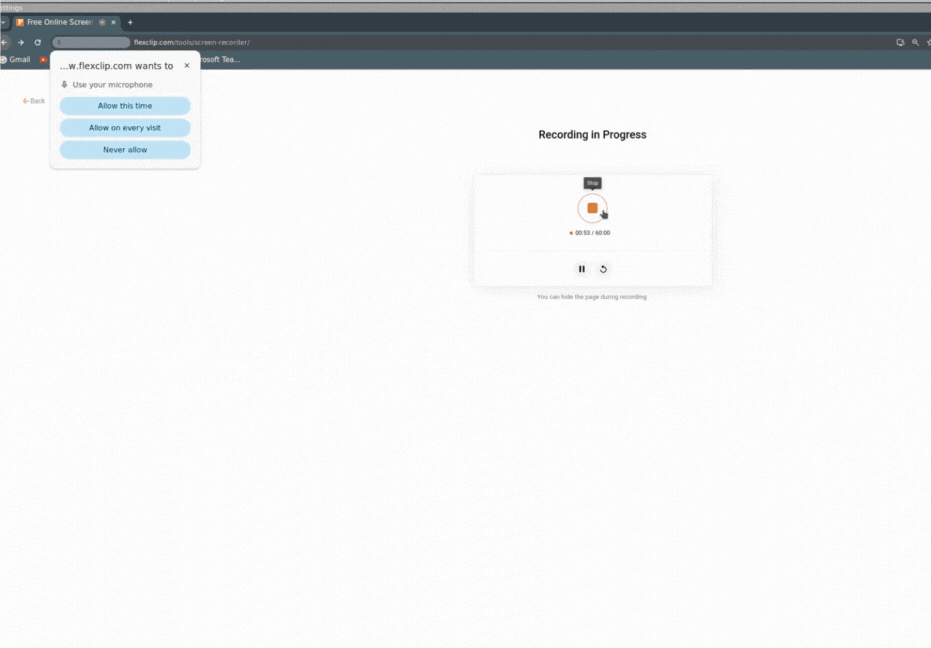
Os cientistas de dados criam um notebook de solução baseado em ML, preparando os dados, depois extraindo os principais recursos e criando e treinando o modelo. Headergen aproveita a estrutura narrativa implícita de um notebook ML para adicionar cabeçalhos estruturais como anotações ao notebook.
pip install headergen
Inserção automatizada de cabeçalho de marcação: por meio de uma taxonomia para operações de aprendizado de máquina, o Headergen anota as células de código com cabeçalhos de marcação relevantes.
Função Chamada Taxonomia: classifica metodicamente chamadas de função com base em uma taxonomia de operações de aprendizado de máquina.
Análise de gráfico de chamadas avançadas: aprimora a estrutura do PYCG com sensibilidade ao fluxo e resolução do tipo de retorno da biblioteca externa.
Precisão em bibliotecas externas: Capacidade de resolver com precisão os tipos de retorno de função de bibliotecas externas usando o tipo de tipo de tipo.
MAIS DE PADRÃO DE Sintaxe: emprega dados de tipo para correspondência de padrões.
generate comando:Gere o notebook anotado por Headergen no diretório atual. Observe que os caches serão criados na primeira vez que Headergen for executado.
headergen generate -i /path/to/input.ipynbGere um arquivo de metadados JSON que inclua várias informações de análise, use o sinalizador --json_output ou -j.
headergen generate -i /path/to/input.ipynb -o /path/to/output/ -jtypes :Executar a inferência do tipo no arquivo e buscar informações do tipo.
headergen types -i /path/to/input.ipynbGere um arquivo json com informações de tipo, use o sinalizador --json_output ou -j.
headergen types -i /path/to/input.ipynb -o /path/to/output/ -jserver :Iniciar o servidor é simples:
headergen server
Isso iniciará o servidor Uvicorn ouvindo no host 0.0.0.0 e na porta 54068.
Este terminal retorna a análise do notebook especificado ou script Python como uma resposta JSON contendo dados de análise como Cell_Callsites e Block_Mapping.
Exemplo usando CURL:
curl "http://0.0.0.0:54068/get_analysis_notebook?file_path=/absolute/path/to/your/file.ipynb"
Este endpoint retorna informações do tipo de notebook especificado ou script Python como uma resposta JSON.
Exemplo usando CURL:
curl "http://0.0.0.0:54068/get_types?file_path=/absolute/path/to/your/file.ipynb"
Este endpoint retorna o notebook anotado com base na análise. A resposta será um download de arquivo.
Exemplo usando CURL:
curl "http://0.0.0.0:54068/generate_annotated_notebook?file_path=/absolute/path/to/your/file.ipynb" --output annotated_file.ipynb
callsites-jupyternb-micro-benchmark : Micro Benchmarkcallsites-jupyternb-real-world-benchmark : Benchmark do mundo realevaluation : contém a anotação manual do cabeçalho e os resultados do estudo do usuárioframework_models : Função chamadas para o mapeamento de taxonomia MLtypestub-database : Type-STBs para bibliotecas MLheadergen : Código Fonte de Headergenpycg_extended : código -fonte de pycg estendidoheadergen-extension : Jupyter Notebook Plugin para HGheadergen_output : pasta onde os notebooks gerados do contêiner do docker são armazenados Obtenha arquivos de origem
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Linux
docker build -t headergen .
docker run -v {$PWD}/headergen_output:/headergen_output -it headergen bash
Windows
docker build -t headergen .
docker run -v "%cd%"/headergen_output:/headergen_output -it headergen bash
Saída gerada a partir dos seguintes comandos, como notebooks anotados, relatórios, chamadas, cabeçalhos etc., são armazenados na pasta local headergen_output após a execução dos seguintes comandos.
Micro Benchmark (gera um arquivo CSV com resultados)
make ROOT_PATH=/app/HeaderGen microbench
Benchmark do mundo real (gera notebooks anotados e arquivo CSV que reproduz a Tabela 2)
make ROOT_PATH=/app/HeaderGen realworldbench
Ambos os benchmarks
make ROOT_PATH=/app/HeaderGen all
Saída gerada limpa
make clean
Obtenha arquivos de origem
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Cache limpo se houver
rm framework_models/models_cache.pickle
rm pycg_extended/machinery/pytd_cache.pickle
Configure Venv e dependências com script setup.sh
./setup.sh -i
Micro Benchmark (gera um arquivo CSV com resultados)
make ROOT_PATH=<path to repo root> microbench
Benchmark do mundo real (gera notebooks anotados e arquivo CSV que reproduz a Tabela 2)
make ROOT_PATH=<path to repo root> realworldbench
Ambos os benchmarks
make ROOT_PATH=<path to repo root> all
Saída gerada limpa
make clean
Este repo contém código para o artigo "Aprimorando a compreensão e a navegação nos notebooks de Jupyter com análise estática" publicada na Conferência Saner 2023.


