HeaderGen
1.0.0

HeaGen ist ein Werkzeugbasis, um das Verständnis und die Navigation von Jupyter-Notizbüchern undokumentierter Python-basierter Python zu verbessern, indem automatisch eine narrative Struktur im Notebook erstellt wird.
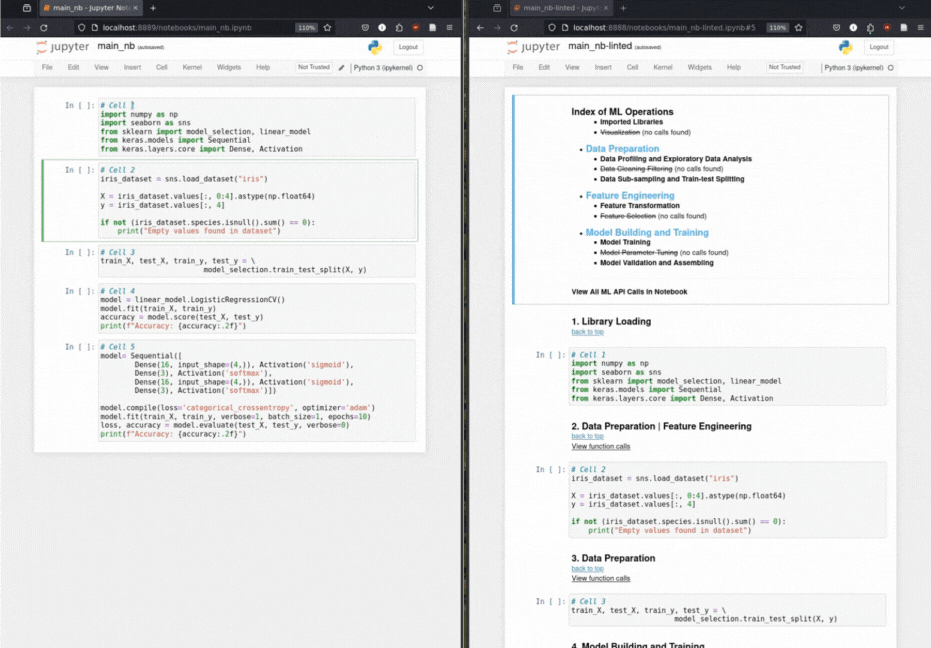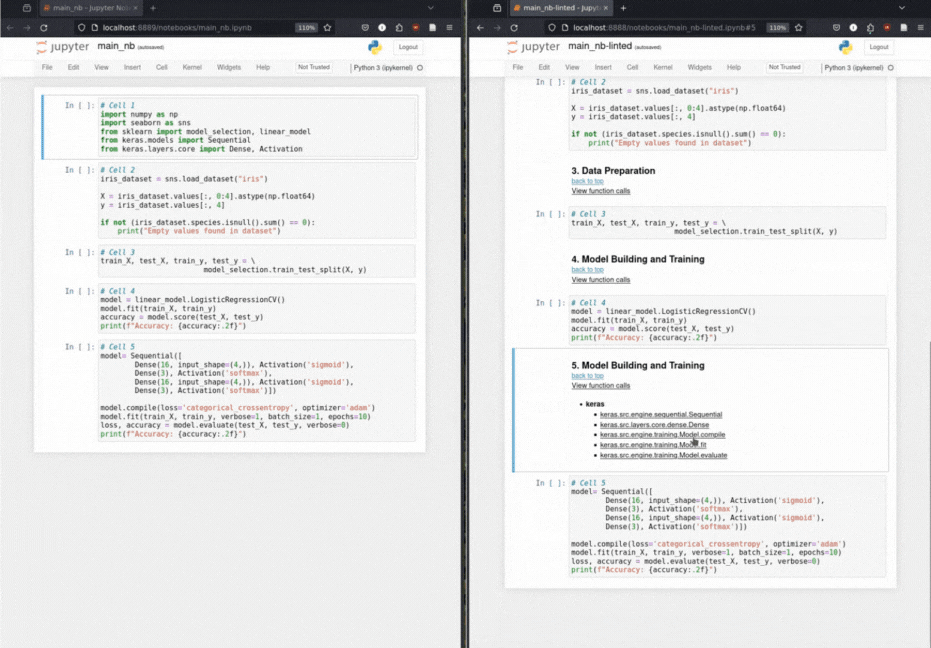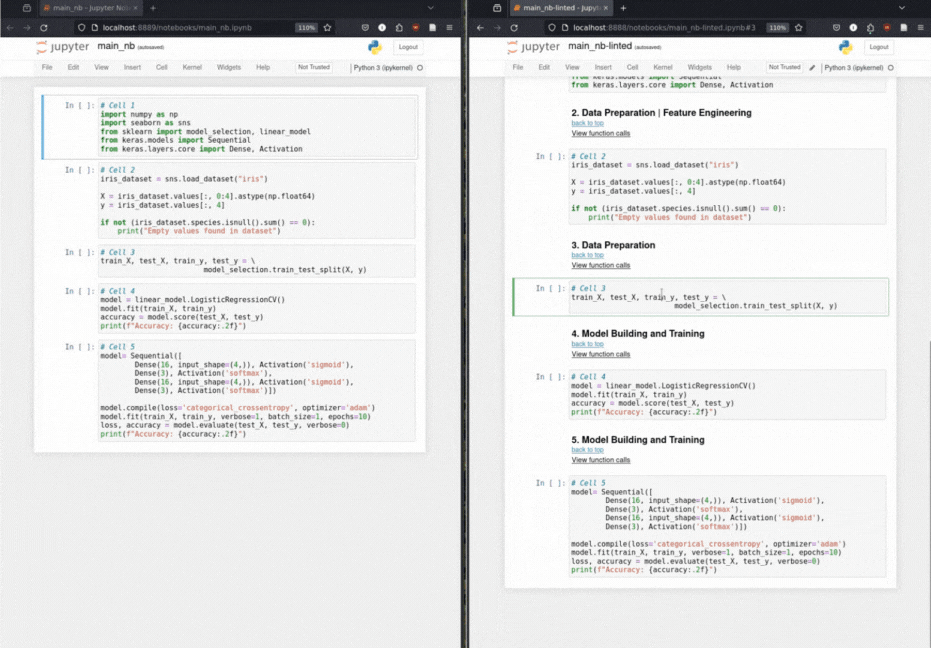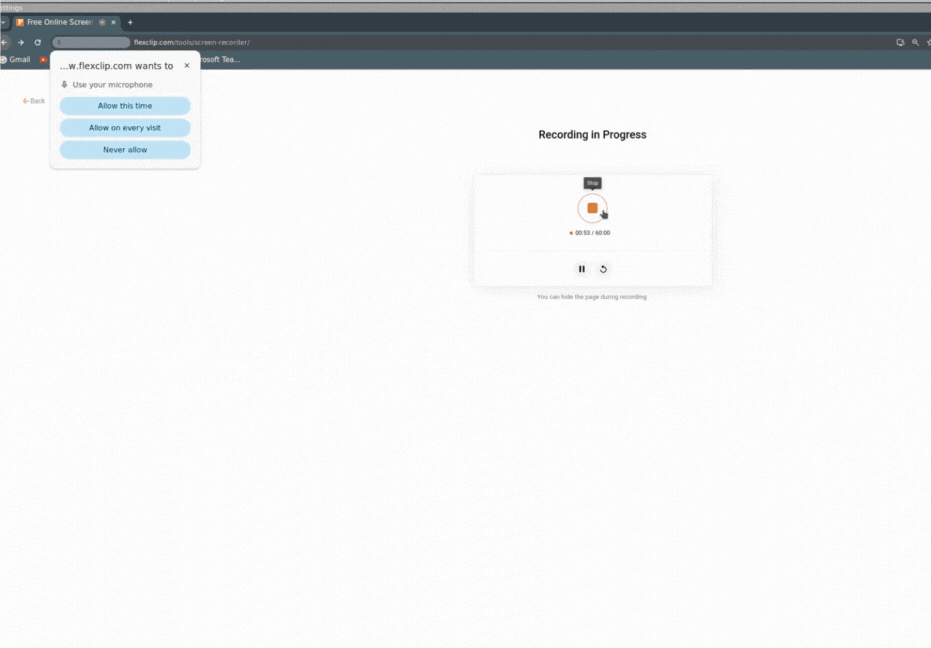
Datenwissenschaftler erstellen ein ML-basierter Lösungs-Notebook, indem er zuerst die Daten vorbereitet, dann wichtige Merkmale extrahiert und dann das Modell erstellt und trainiert. Headen nutzt die implizite narrative Struktur eines ML -Notizbuchs, um dem Notebook strukturelle Header als Annotationen hinzuzufügen.
pip install headergen
Automatisierte Markdown-Header-Einfügung: Durch eine Taxonomie für maschinell-lernende Operationen kommentiert Header Code-Zellen mit relevanten Markdown-Headern.
Funktionsaufruf Taxonomie: Klassifiziert Funktionsaufrufe methodisch auf der Grundlage einer Taxonomie des maschinellen Lernbetriebs.
Advanced Call-Diagrammanalyse: Verbessert das PYCG-Framework mit Flusssensitivität und externer Bibliotheksrückgabeauflösung.
Präzision in externen Bibliotheken: Funktionen zur genauen Auflösung von Funktionsrückgabetypen aus externen Bibliotheken mithilfe von Schreiben.
Syntax -Musteranpassung: Verwendet Typdaten für die Musteranpassung.
generate :Generieren Sie das annotierte Notizbuch des Kopfes im aktuellen Verzeichnis. Beachten Sie, dass die Caches erstellt werden, wenn das erste Mal Headergen ausgeführt wird.
headergen generate -i /path/to/input.ipynbGenerieren Sie eine JSON -Metadata -Datei, die verschiedene Analyseinformationen enthält. Verwenden Sie das Flag --json_output oder -J.
headergen generate -i /path/to/input.ipynb -o /path/to/output/ -jtypes :Führen Sie den Typ -Inferenz in den Datei- und Fetch -Typinformationen aus.
headergen types -i /path/to/input.ipynbGenerieren Sie eine JSON -Datei mit Typinformationen und verwenden Sie das Flag -Json_Output oder -J.
headergen types -i /path/to/input.ipynb -o /path/to/output/ -jserver :Das Starten des Servers ist unkompliziert:
headergen server
Dadurch wird der Uvicorn -Server gestartet, der Host 0.0.0.0 und Port 54068 anhört.
Dieser Endpunkt gibt die Analyse des angegebenen Notebook- oder Python -Skripts als JSON -Antwort zurück, das Analysedaten wie Cell_Callssite und Block_Mapping enthält.
Beispiel mit Curl:
curl "http://0.0.0.0:54068/get_analysis_notebook?file_path=/absolute/path/to/your/file.ipynb"
Dieser Endpunkt gibt Typinformationen des angegebenen Notebook- oder Python -Skripts als JSON -Antwort zurück.
Beispiel mit Curl:
curl "http://0.0.0.0:54068/get_types?file_path=/absolute/path/to/your/file.ipynb"
Dieser Endpunkt gibt das kommentierte Notizbuch basierend auf der Analyse zurück. Die Antwort ist ein Datei -Download.
Beispiel mit Curl:
curl "http://0.0.0.0:54068/generate_annotated_notebook?file_path=/absolute/path/to/your/file.ipynb" --output annotated_file.ipynb
callsites-jupyternb-micro-benchmark : Micro-Benchmarkcallsites-jupyternb-real-world-benchmark : Real-World Benchmarkevaluation : Enthält manuelle Header -Annotation und Benutzerstudienergebnisseframework_models : Funktionsaufrufe zur ML -Taxonomie -Zuordnungtypestub-database : Typ-STBS für ML-Bibliothekenheadergen : Quellcode von Heatengenpycg_extended : Quellcode von erweitertem PYCGheadergen-extension : Jupyter Notebook Plugin für HGheadergen_output : Ordner, in dem die generierten Notizbücher aus dem Docker -Container gespeichert sind Holen Sie sich Quelldateien
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Linux
docker build -t headergen .
docker run -v {$PWD}/headergen_output:/headergen_output -it headergen bash
Fenster
docker build -t headergen .
docker run -v "%cd%"/headergen_output:/headergen_output -it headergen bash
Ausgabe, die aus den folgenden Befehlen erzeugt werden, wie z. B. annotierte Notizbücher, Berichte, Callsites, Header usw., werden im lokalen Ordner headergen_output gespeichert, nachdem die folgenden Befehle ausgeführt wurden.
Micro -Benchmark (generiert eine CSV -Datei mit Ergebnissen)
make ROOT_PATH=/app/HeaderGen microbench
Real-World Benchmark (generiert kommentierte Notizbücher und CSV-Datei, die Tabelle 2 reproduzieren)
make ROOT_PATH=/app/HeaderGen realworldbench
Beide Benchmarks
make ROOT_PATH=/app/HeaderGen all
Erzeugte Ausgabe sauber
make clean
Holen Sie sich Quelldateien
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Cache löschen, wenn existiert
rm framework_models/models_cache.pickle
rm pycg_extended/machinery/pytd_cache.pickle
Setup Venv und Abhängigkeiten mit setup.sh script
./setup.sh -i
Micro -Benchmark (generiert eine CSV -Datei mit Ergebnissen)
make ROOT_PATH=<path to repo root> microbench
Real-World Benchmark (generiert kommentierte Notizbücher und CSV-Datei, die Tabelle 2 reproduzieren)
make ROOT_PATH=<path to repo root> realworldbench
Beide Benchmarks
make ROOT_PATH=<path to repo root> all
Erzeugte Ausgabe sauber
make clean
Dieses Repo enthält Code für das Papier "Verbesserung des Verständnisses und Navigation in Jupyter -Notizbüchern mit statischer Analyse", die auf der Saner Conference 2023 veröffentlicht wurde.


