HeaderGen
1.0.0

El encabezado es un enfoque basado en herramientas para mejorar la comprensión y la navegación de los cuadernos Jupyter basados en Python indocumentados al crear automáticamente una estructura narrativa en el cuaderno.
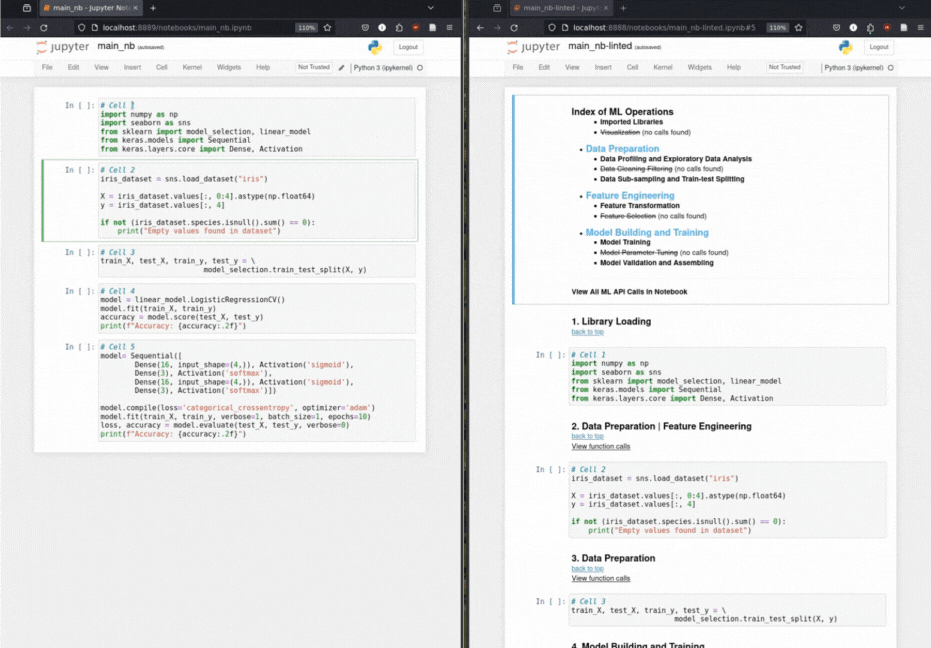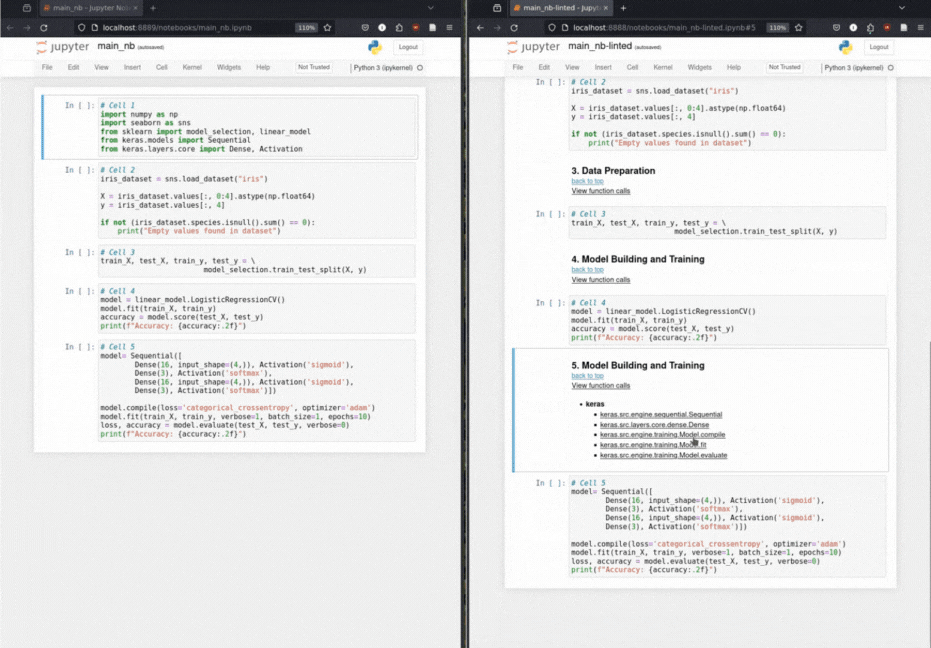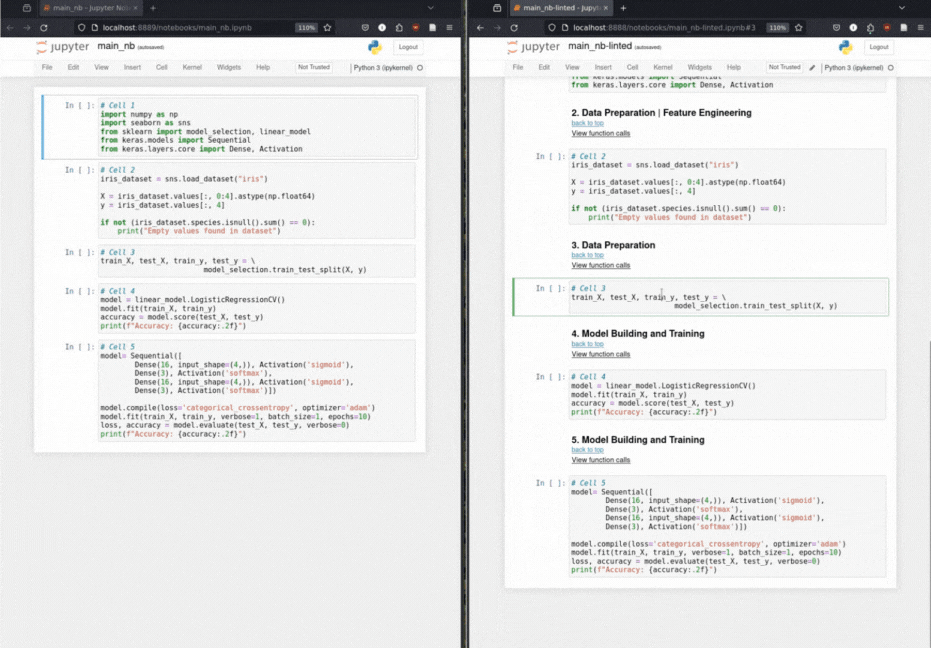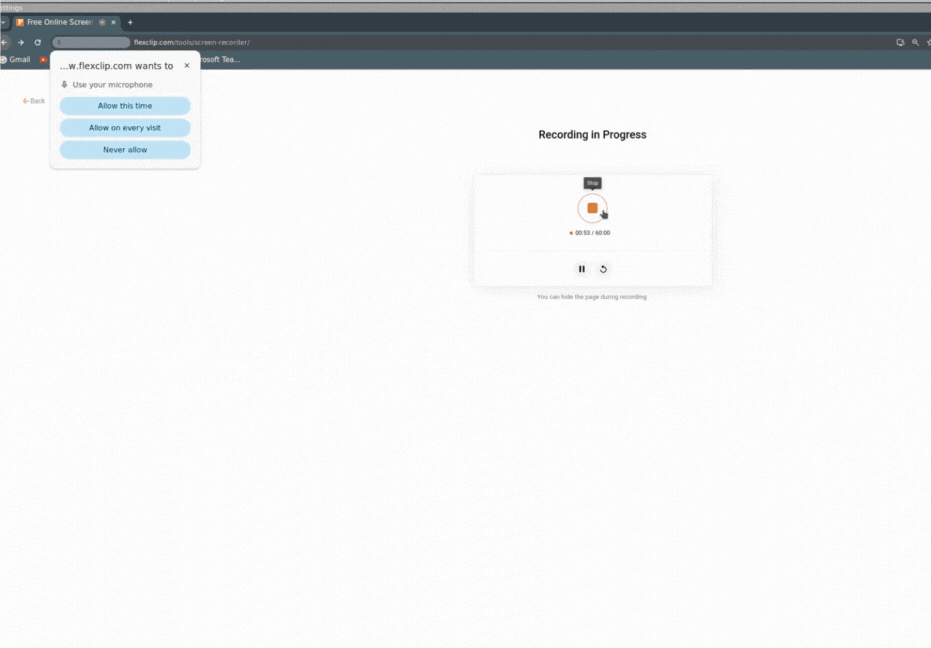
Los científicos de datos crean un cuaderno de solución basado en ML al preparar primero los datos, luego extraer características clave y luego crear y capacitar el modelo. El artista aprovecha la estructura narrativa implícita de un cuaderno ML para agregar encabezados estructurales como anotaciones a la cuaderno.
pip install headergen
Inserción de encabezado de markdown automatizado: a través de una taxonomía para las operaciones de aprendizaje automático, el encabezado anota las celdas de código con encabezados de markdown relevantes.
Taxonomía de llamadas de función: clasifica metódicamente las llamadas de función basadas en una taxonomía de operaciones de aprendizaje automático.
Análisis avanzado de gráficos de llamadas: mejora el marco PYCG con sensibilidad a flujo y resolución de tipo de retorno de la biblioteca externa.
Precisión en bibliotecas externas: capacidad para resolver con precisión los tipos de retorno de la función de bibliotecas externas que usan Typestubs.
COMPARACIÓN DE PATRÓN DE SINTAX: emplea datos de tipo para la coincidencia de patrones.
generate el comando:Genere el cuaderno anotado del encabezado en el directorio actual. Tenga en cuenta que los cachés se crearán la primera vez que se ejecuta el encabezado.
headergen generate -i /path/to/input.ipynbGenere un archivo de metadatos JSON que incluya diversa información de análisis, use el indicador --json_output o -j.
headergen generate -i /path/to/input.ipynb -o /path/to/output/ -jtypes :Ejecute la inferencia de tipo en el archivo y obtenga información de tipo.
headergen types -i /path/to/input.ipynbGenere un archivo JSON con información de tipo, use el indicador --json_output o -j.
headergen types -i /path/to/input.ipynb -o /path/to/output/ -jserver :Comenzar el servidor es sencillo:
headergen server
Esto iniciará el servidor UVICORN escuchando en el host 0.0.0.0 y el puerto 54068.
Este punto final devuelve el análisis del cuaderno especificado o el script de Python como una respuesta JSON que contiene datos de análisis como Cell_Callsites y Block_Mapping.
Ejemplo usando curl:
curl "http://0.0.0.0:54068/get_analysis_notebook?file_path=/absolute/path/to/your/file.ipynb"
Este punto final devuelve información de tipo de cuaderno especificado o script de Python como una respuesta JSON.
Ejemplo usando curl:
curl "http://0.0.0.0:54068/get_types?file_path=/absolute/path/to/your/file.ipynb"
Este punto final devuelve el cuaderno anotado en función del análisis. La respuesta será una descarga de archivos.
Ejemplo usando curl:
curl "http://0.0.0.0:54068/generate_annotated_notebook?file_path=/absolute/path/to/your/file.ipynb" --output annotated_file.ipynb
callsites-jupyternb-micro-benchmark : Micro Benchmarkcallsites-jupyternb-real-world-benchmark : Real World Benchmarkevaluation : contiene anotación de encabezado manual y resultados del estudio de usuariosframework_models : llamadas de función a ML Mapeo de taxonomíatypestub-database : Tipo de STB para bibliotecas MLheadergenpycg_extended : código fuente de PYCG extendidoheadergen-extension : complemento de cuaderno de Jupyter para HGheadergen_output : carpeta donde se almacenan los cuadernos generados desde el contenedor Docker Obtener archivos de origen
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Linux
docker build -t headergen .
docker run -v {$PWD}/headergen_output:/headergen_output -it headergen bash
Windows
docker build -t headergen .
docker run -v "%cd%"/headergen_output:/headergen_output -it headergen bash
La salida generada a partir de los siguientes comandos, como cuadernos anotados, informes, llamadas, encabezados, etc., se almacenan en la carpeta local headergen_output después de que los siguientes comandos se ejecuten.
Micro Benchmark (genera un archivo CSV con resultados)
make ROOT_PATH=/app/HeaderGen microbench
Benchmark del mundo real (genera cuadernos anotados y archivo CSV que reproduce la Tabla 2)
make ROOT_PATH=/app/HeaderGen realworldbench
Ambos puntos de referencia
make ROOT_PATH=/app/HeaderGen all
Salida de limpieza generada
make clean
Obtener archivos de origen
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Borrar caché si existe
rm framework_models/models_cache.pickle
rm pycg_extended/machinery/pytd_cache.pickle
Configurar venv y dependencias con setup.sh script
./setup.sh -i
Micro Benchmark (genera un archivo CSV con resultados)
make ROOT_PATH=<path to repo root> microbench
Benchmark del mundo real (genera cuadernos anotados y archivo CSV que reproduce la Tabla 2)
make ROOT_PATH=<path to repo root> realworldbench
Ambos puntos de referencia
make ROOT_PATH=<path to repo root> all
Salida de limpieza generada
make clean
Este repositorio contiene código para el documento "Mejora de la comprensión y navegación en cuadernos Jupyter con análisis estático" publicado en la Conferencia SANER 2023.


