HeaderGen
1.0.0

Headergen est une approche basée sur des outils pour améliorer la compréhension et la navigation des ordinateurs portables Jupyter à base de Python sans papiers en créant automatiquement une structure narrative dans le cahier.
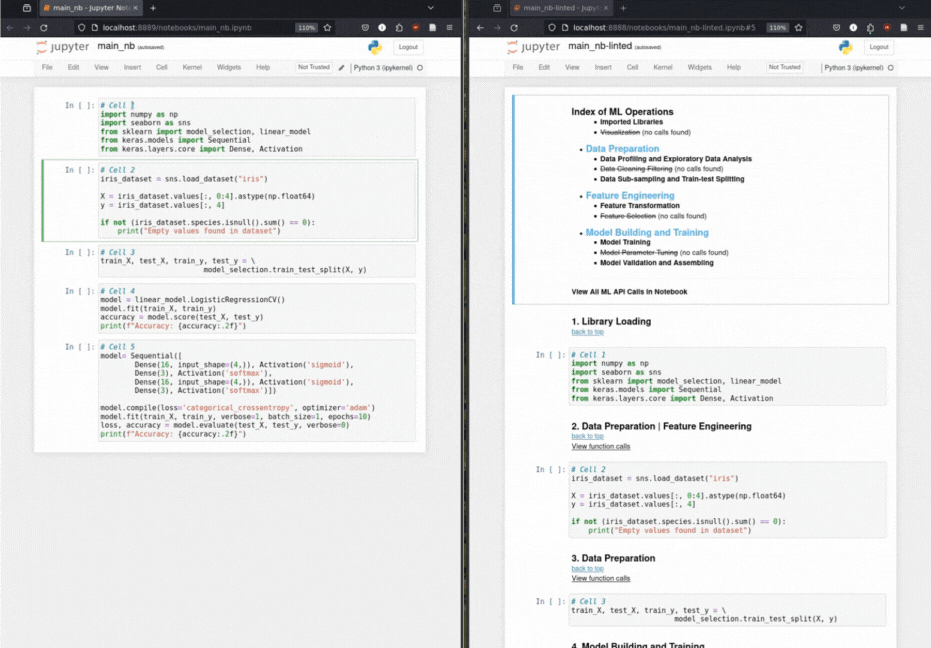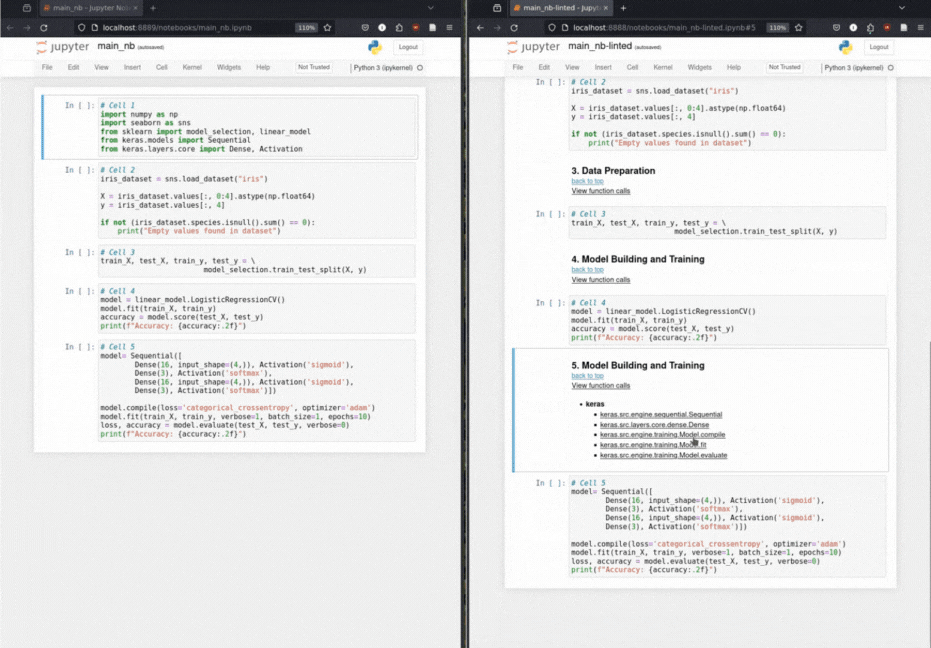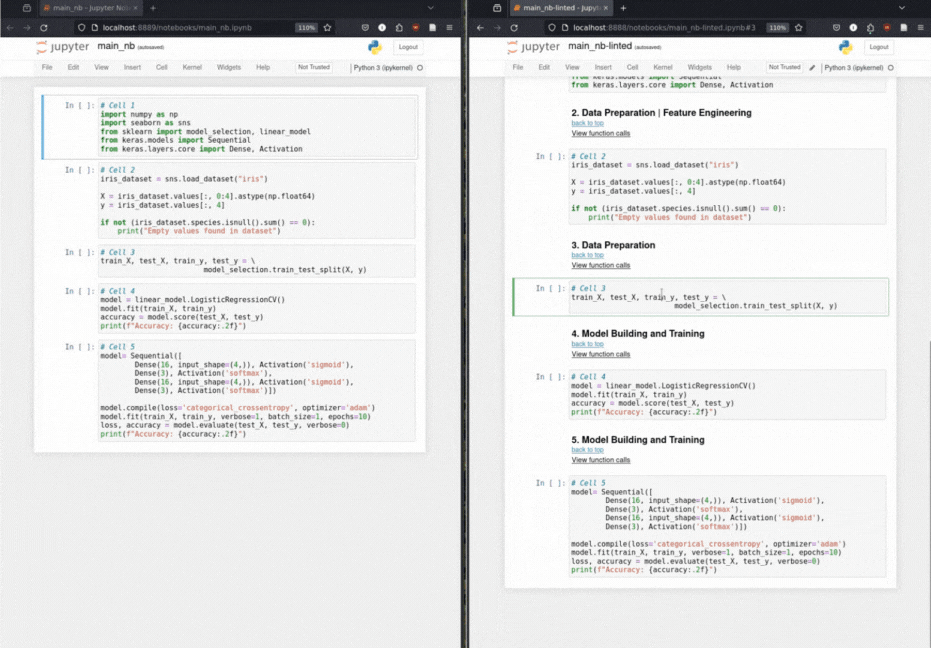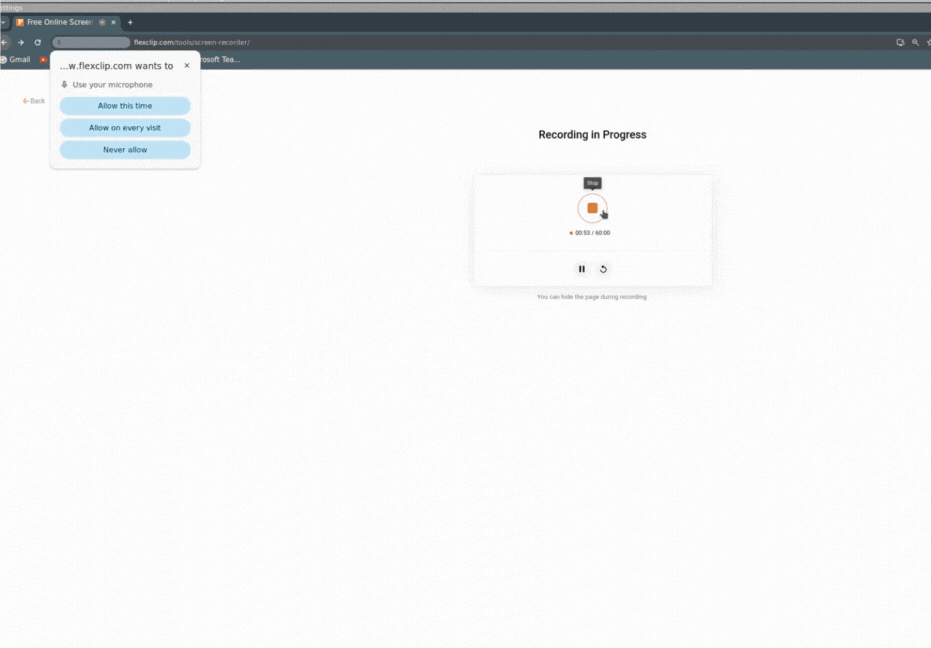
Les scientifiques des données construisent un ordinateur portable de solution basé sur ML en préparant d'abord les données, puis en extraitant des fonctionnalités clés, puis en créant et en entraînant le modèle. L'éditeur exploite la structure narrative implicite d'un cahier ML pour ajouter des en-têtes structurels comme annotations au cahier.
pip install headergen
Insertion automatisée de l'en-tête Markdown: Grâce à une taxonomie pour les opérations d'apprentissage automatique, Hereger annote les cellules de code avec des en-têtes de démarque pertinents.
Taxonomie des appels de fonction: classe méthodiquement les appels de fonction basés sur une taxonomie d'opérations d'apprentissage automatique.
Analyse des graphiques d'appel avancé: améliore le cadre PYCG avec la sensibilité à l'écoulement et la résolution de type retour de bibliothèque externe.
Précision dans les bibliothèques externes: capacité à résoudre avec précision les types de retour de fonction des bibliothèques externes à l'aide de typestubs.
Correspondance de motifs de syntaxe: utilise des données de type pour la correspondance de motifs.
generate la commande:Générez le cahier annoté du Heuregène dans le répertoire actuel. Notez que les caches seront créées le premier chef d'échange est exécuté.
headergen generate -i /path/to/input.ipynbGénérez un fichier de métadonnées JSON qui comprend diverses informations d'analyse, utilisez l'indicateur --json_output ou -j.
headergen generate -i /path/to/input.ipynb -o /path/to/output/ -jtypes Commande:Exécutez l'inférence de type sur le fichier et récupérez les informations de type.
headergen types -i /path/to/input.ipynbGénérez un fichier JSON avec des informations de type, utilisez l'indicateur --json_output ou -j.
headergen types -i /path/to/input.ipynb -o /path/to/output/ -jserver :Le démarrage du serveur est simple:
headergen server
Cela commencera le serveur Uvicorn écoutant sur l'hôte 0.0.0.0 et le port 54068.
Ce point de terminaison renvoie l'analyse du cahier ou du script Python spécifié en tant que réponse JSON contenant des données d'analyse comme Cell_CallSites et Block_Mapping.
Exemple utilisant Curl:
curl "http://0.0.0.0:54068/get_analysis_notebook?file_path=/absolute/path/to/your/file.ipynb"
Ce point de terminaison renvoie les informations de type du cahier spécifié ou du script Python en tant que réponse JSON.
Exemple utilisant Curl:
curl "http://0.0.0.0:54068/get_types?file_path=/absolute/path/to/your/file.ipynb"
Ce point de terminaison renvoie le cahier annoté en fonction de l'analyse. La réponse sera un téléchargement de fichiers.
Exemple utilisant Curl:
curl "http://0.0.0.0:54068/generate_annotated_notebook?file_path=/absolute/path/to/your/file.ipynb" --output annotated_file.ipynb
callsites-jupyternb-micro-benchmark : Micro Benchmarkcallsites-jupyternb-real-world-benchmark : Benchmark réelevaluation : Contient l'annotation en en-tête manuelle et les résultats de l'étude des utilisateursframework_models : les appels de fonction à la cartographie de la taxonomie MLtypestub-database : Type-STB pour les bibliothèques MLheadergen : Code source du Heurementpycg_extended : code source de pycg étenduheadergen-extension : Jupyter Notebook Plugin pour HGheadergen_output : dossier où les ordinateurs portables générés du conteneur Docker sont stockés Obtenez des fichiers source
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Linux
docker build -t headergen .
docker run -v {$PWD}/headergen_output:/headergen_output -it headergen bash
Fenêtre
docker build -t headergen .
docker run -v "%cd%"/headergen_output:/headergen_output -it headergen bash
La sortie générée à partir des commandes suivantes, telles que les ordinateurs portables annotés, les rapports, les appels, les en-têtes, etc., sont stockés dans le dossier local headergen_output après l'exécution des commandes suivantes.
Micro Benchmark (génère un fichier CSV avec les résultats)
make ROOT_PATH=/app/HeaderGen microbench
Benchmark réel (génère des cahiers annotés et du fichier CSV qui reproduisent le tableau 2)
make ROOT_PATH=/app/HeaderGen realworldbench
Les deux repères
make ROOT_PATH=/app/HeaderGen all
Nettoyer la sortie générée
make clean
Obtenez des fichiers source
git clone --recursive
git submodule update --init --recursive
git pull --recurse-submodules
Effacer le cache s'il existe
rm framework_models/models_cache.pickle
rm pycg_extended/machinery/pytd_cache.pickle
Configuration de Venv et de dépendances avec le script setup.sh
./setup.sh -i
Micro Benchmark (génère un fichier CSV avec les résultats)
make ROOT_PATH=<path to repo root> microbench
Benchmark réel (génère des cahiers annotés et du fichier CSV qui reproduisent le tableau 2)
make ROOT_PATH=<path to repo root> realworldbench
Les deux repères
make ROOT_PATH=<path to repo root> all
Nettoyer la sortie générée
make clean
Ce repo contient du code pour l'article "Enhancing Comprehension and Navigation in Jupyter Notebooks with static Analysis" publié à la Saner Conference 2023.


