news_research_tool_Equity Research Analysis
1.1.0
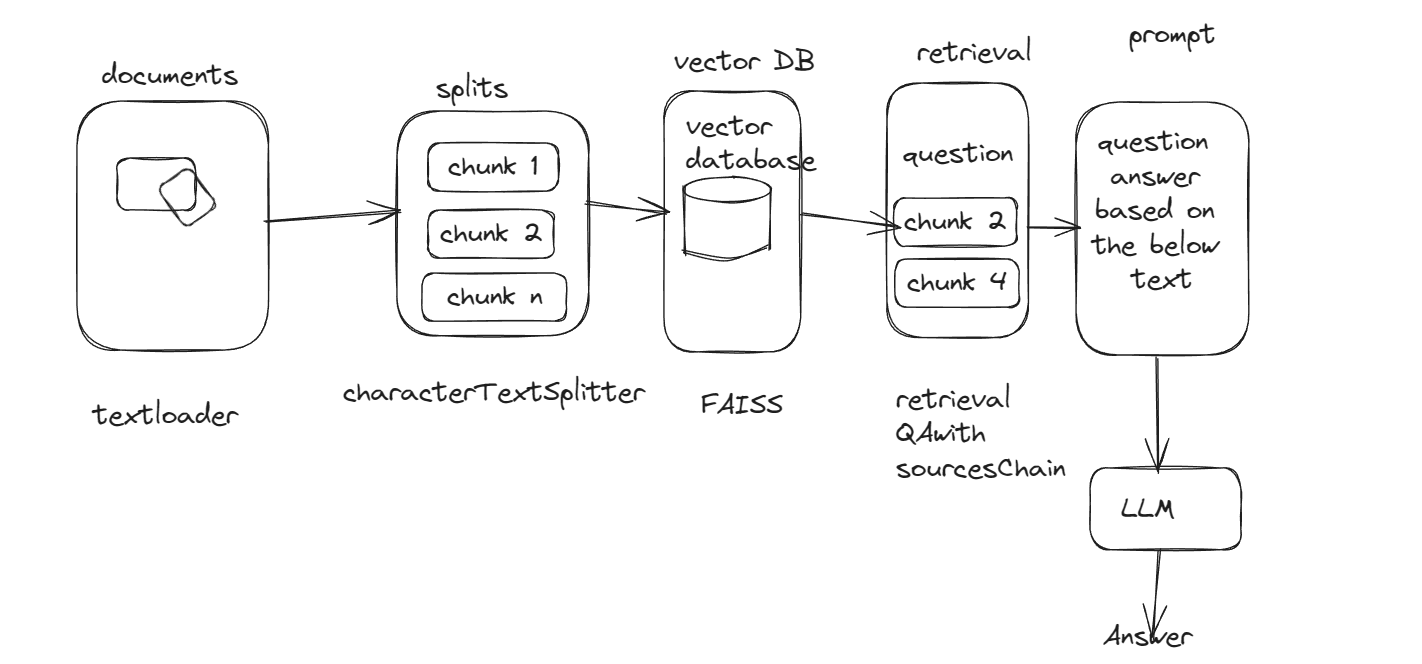
O Finguru é uma ferramenta de pesquisa de notícias que processa e analisa artigos de notícias de URLs e PDF. Ele aproveita o Langchain, o Google incorporados e o simplit para fornecer informações e respostas com base no conteúdo dos artigos.
google gemini-pro
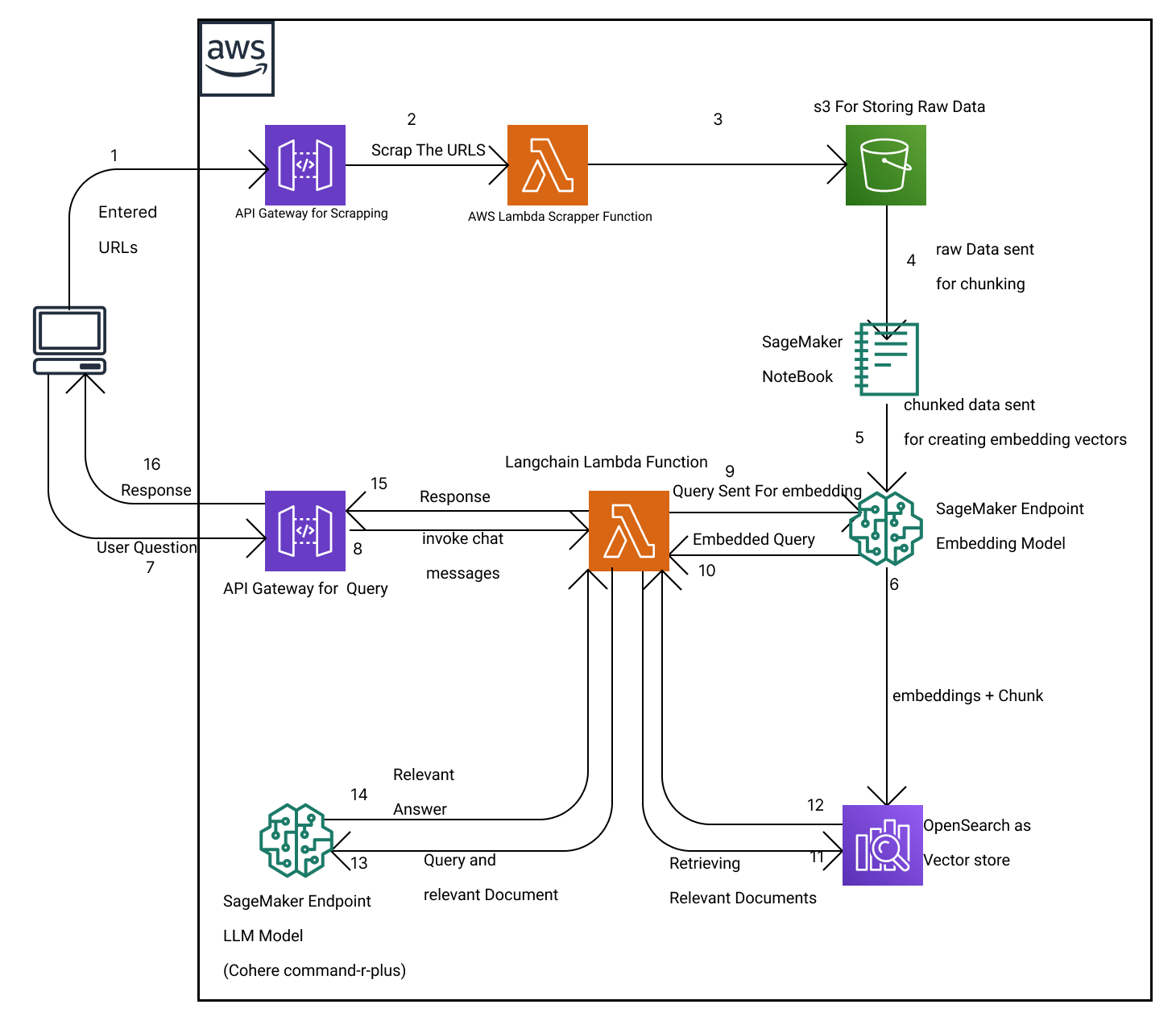
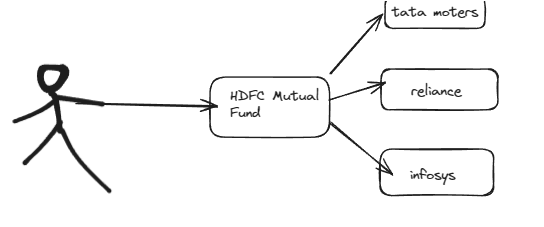
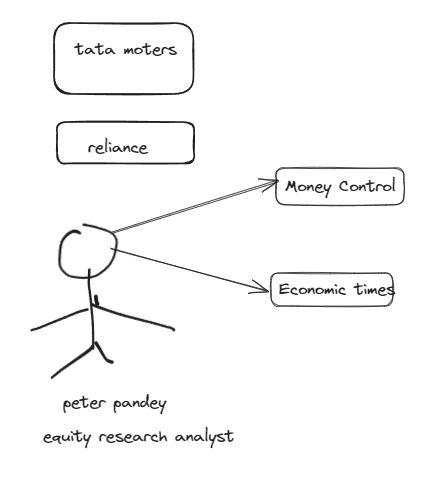
- Issue 1 : Copy pasting article in ChatGPt is tedious
- Issue 2 : We need an aggregate knowledge base
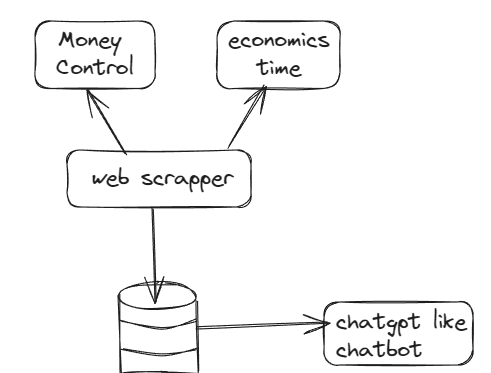
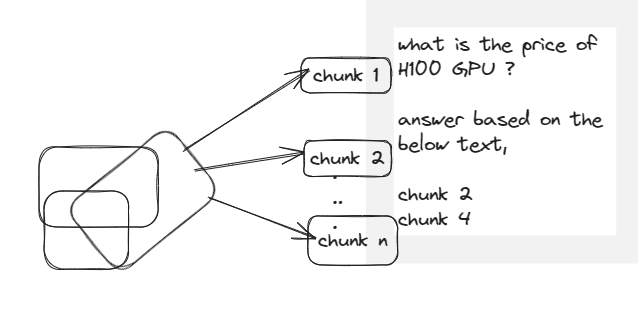


Semantic search
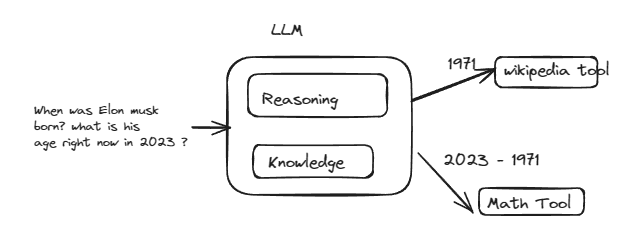
Wikipedia Google Search Google Finance duckduckGo search
git clone https://github.com/mihirh19/news_research_tool_Equity-Research-Analysis-.git
cd news_research_tool_Equity-Research-Analysis-python -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate` pip install -r requirements.txtPrimeiro, você precisa configurar as chaves da API e as variáveis de ambiente adequadas. Para configurá -lo, crie o Google_API_KEY no Google Cloud Credencial Console (https://console.cloud.google.com/apis/credentials) e um google_cse_id usando o mecanismo de pesquisa programável (https://programablearchengine.google.com/controlpanel/create). Em seguida, é bom seguir as instruções encontradas aqui.
Crie a chave da API em https://serpapi.com/
secrets.toml no diretório .streamlit com o seguinte conteúdo: GOOGLE_API_KEY = " your-google-api-key "
GOOGLE_CSE_ID = " your-cse-id "
SERP_API_KEY = " your- " streamlit run app.pywhat is the target price of tata motors ? e clique em Submit para obter a resposta. AnualReport202223.pdf Faça o upload do PDF fornecido
Clique em "Processe PDF" para iniciar o processamento.
Digite uma consulta como what is the yoy change of revenue of tata motors ? e clique em Submit para obter a resposta.
? Mihir Hadavani
Dê a um ️ se este projeto o ajudar!


