? Finguru: outil de recherche d'actualités
Finguru est un outil de recherche d'actualités qui traite et analyse les articles d'information des URL et du PDF donné. Il tire parti de Langchain, Google Embeddings et rational pour fournir des informations et des réponses basées sur le contenu des articles.
Caractéristiques
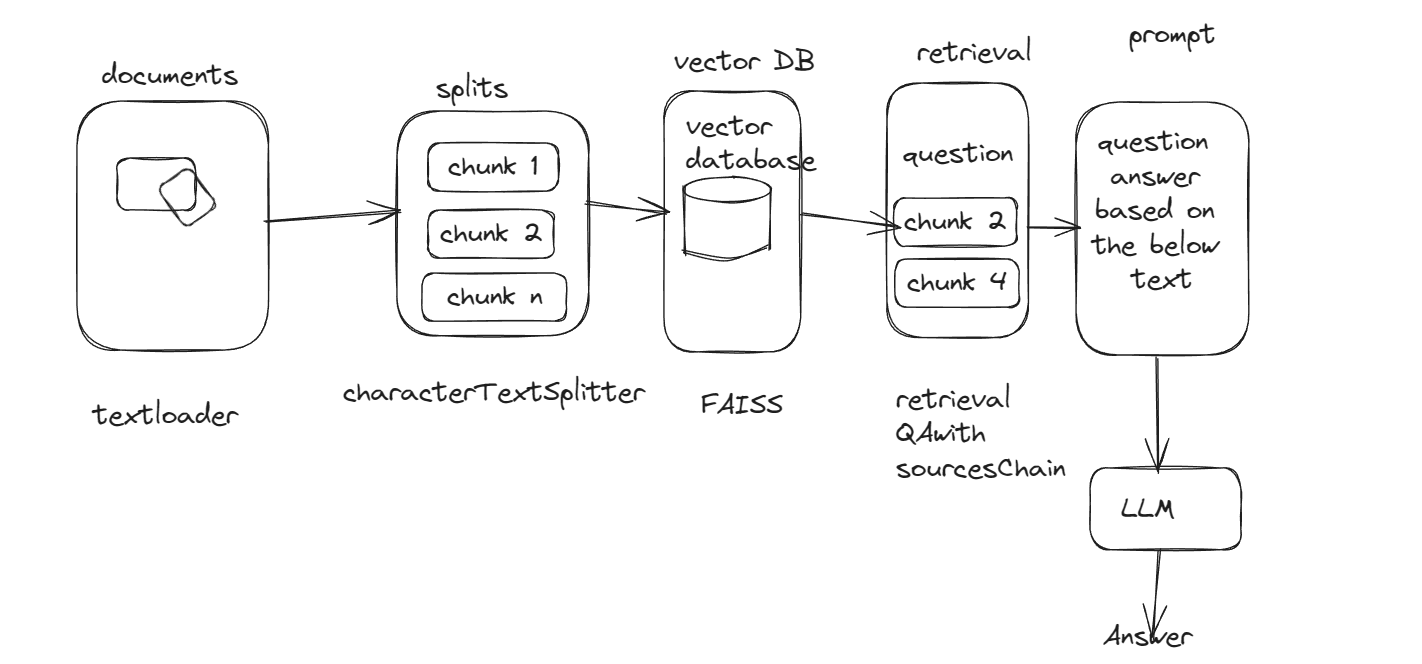
- Recherchez et analyser les articles de presse à partir des URL ou des données d'analyse du PDF donné
- Diviser les articles en morceaux gérables
- Créer des intégres pour le texte à l'aide du modèle GoogleMedding
- Stocker des intégres dans un index FAIS pour une récupération efficace
- Interrogez les données traitées pour obtenir des réponses et des sources
Comment il est construit
- Python 3.7+
- Rationaliser
- Lubriole
- Clé Google API
- Google_cse_id
LLM utilisé
google gemini-pro
Architecture AWS
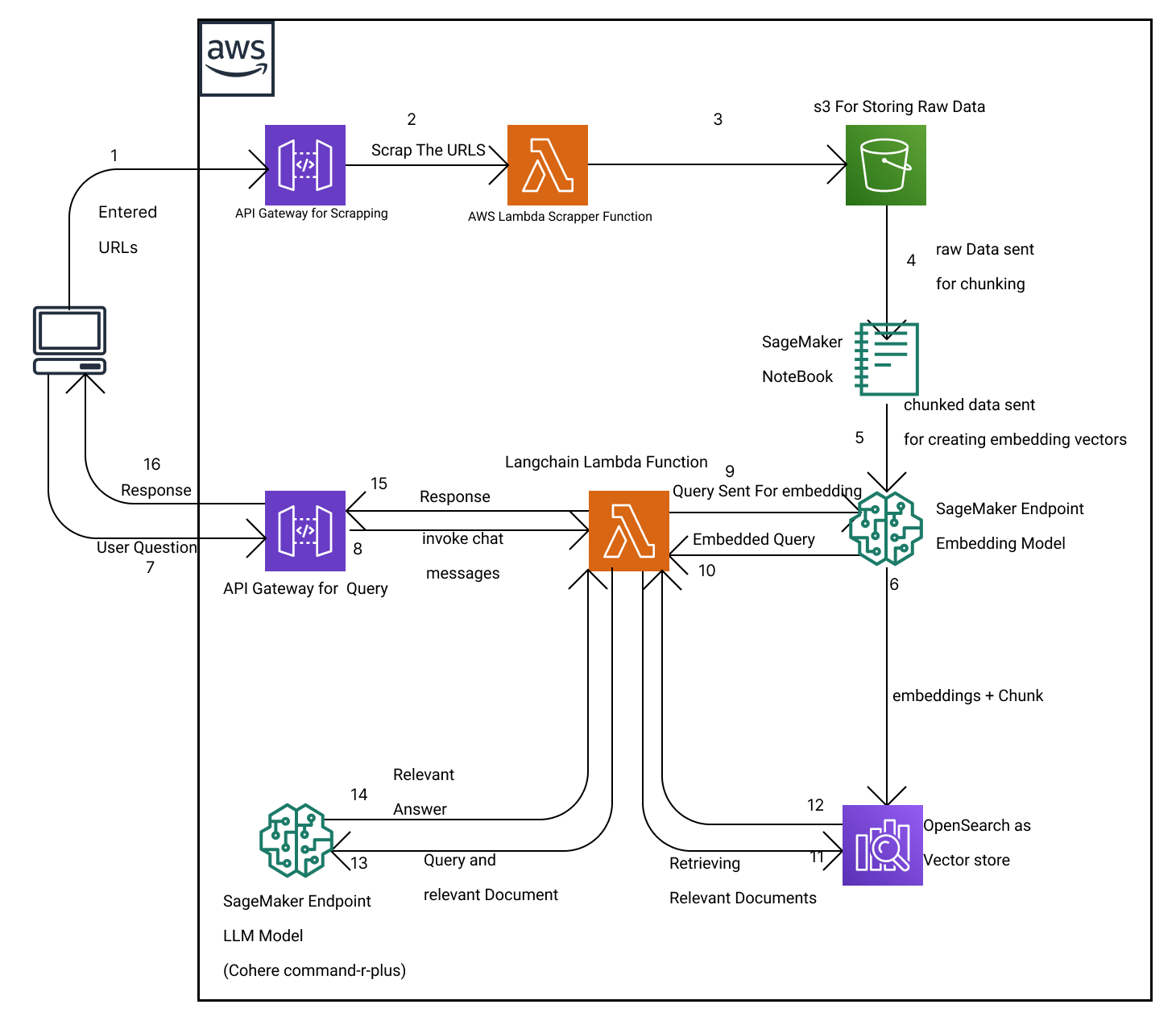
Analyse de la recherche sur les actions
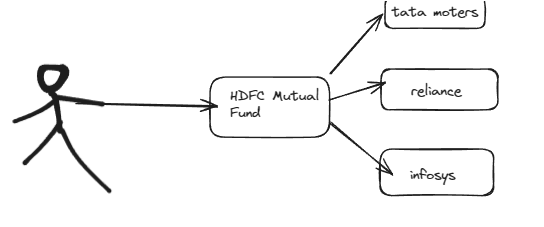
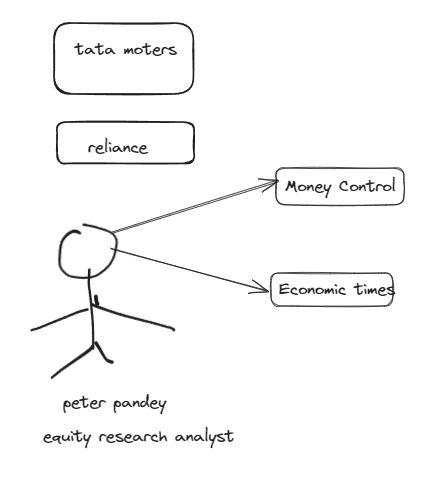
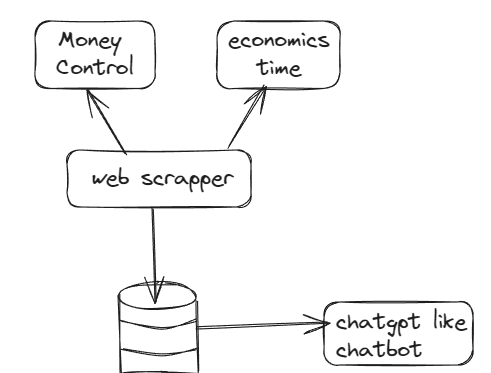
Architecture technologique
- Issue 1 : Copy pasting article in ChatGPt is tedious
- Issue 2 : We need an aggregate knowledge base
Revenu de la pomme

calories en pomme

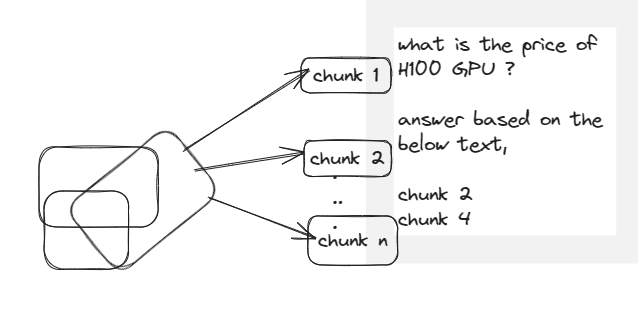
Semantic search
Base de données vectorielle
Agents
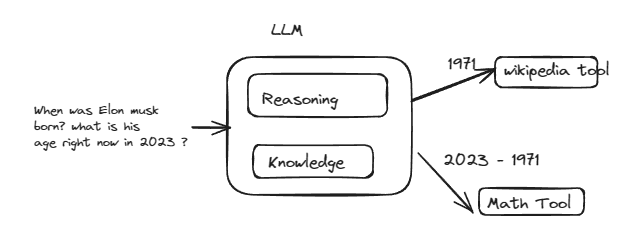
Agents d'occasion
Wikipedia Google Search Google Finance duckduckGo search
Commencer
Installation
1. Clone le référentiel:
git clone https://github.com/mihirh19/news_research_tool_Equity-Research-Analysis-.git
cd news_research_tool_Equity-Research-Analysis-
2. Créez et activez un environnement virtuel:
python -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate`
3. Installez les packages requis:
pip install -r requirements.txt
Installation
Tout d'abord, vous devez configurer les clés API et les variables d'environnement appropriées. Pour le configurer, créez le Google_API_KEY dans la console d'identification Google Cloud (https://console.cloud.google.com/apis/credentials) et un google_cse_id à l'aide du moteur de recherche programmable (https://programmablesearchngine.google.com/contrelpanel/create). Ensuite, il est bon de suivre les instructions trouvées ici.
Créez une clé API sur https://serpapi.com/
3. Créez un fichier nommé secrets.toml dans le répertoire .streamlit avec le contenu suivant:
GOOGLE_API_KEY = " your-google-api-key "
GOOGLE_CSE_ID = " your-cse-id "
SERP_API_KEY = " your- "
Exécution de l'application
Usage
- Ouvrez l'application Streamlit dans votre navigateur.
- Sélectionnez des options dans le menu déroulant dans la barre latérale
- Pour URL:
- Entrez le nombre d'URL que vous souhaitez traiter dans la barre latérale.
- Fournissez les URL pour les articles de presse.
- Cliquez sur "Traiter les URL" pour récupérer et analyser les articles.
- Pour PDF
- Téléchargez un PDF.
- Cliquez sur "Process PDF" pour analyser le PDF.
- Entrez une requête dans la zone d'entrée de texte et cliquez sur "Soumettre" pour obtenir des réponses en fonction des données traitées.
Vous pouvez également utiliser l'avance Google Rechercher des questions financières.
Exemple 1 URL:
- Entrez 3 comme nombre d'URL
- Fournir des URL suivantes:
- https://www.moneycontrol.com/news/business/tata-motors-to-use-new-1-billion-plant-to-make-jaguar-land-rover-cars-report-2666941.html
- https://www.moneycontrol.com/news/business/stocks/tata-motors-stock-jumps-x-after-robust-jlr-sales-brokerages-bullish-12603201.html
- https://www.moneyontrol.com/news/business/stocks/buy-tata-motors-target-of-rs--1188-sharekhan-12411611.html
- Cliquez sur "Traiter les URL" pour commencer le traitement.
- Entrez une requête comme
what is the target price of tata motors ? Et cliquez sur Submit pour obtenir la réponse.
Exemple 2 PDF:
AnnualReport202223.pdf Téléchargez le PDF donné
Cliquez sur "Processus PDF" pour commencer le traitement.
Entrez dans une question comme what is the yoy change of revenue of tata motors ? Et cliquez sur Submit pour obtenir une réponse.
Auteur
? Mihir Hadavani
- Twitter: @ mihirh21
- Github: @ mihirh19
- LinkedIn: @ Mihir-Hadavani-996263232
Montrez votre soutien
Donnez un ️ si ce projet vous a aidé!


