news_research_tool_Equity Research Analysis
1.1.0
Finguru es una herramienta de investigación de noticias que procesa y analiza artículos de noticias de URL dadas y PDF. Aprovecha Langchain, Google Incrushings y Strewlit para proporcionar información y respuestas basadas en el contenido de los artículos.
google gemini-pro
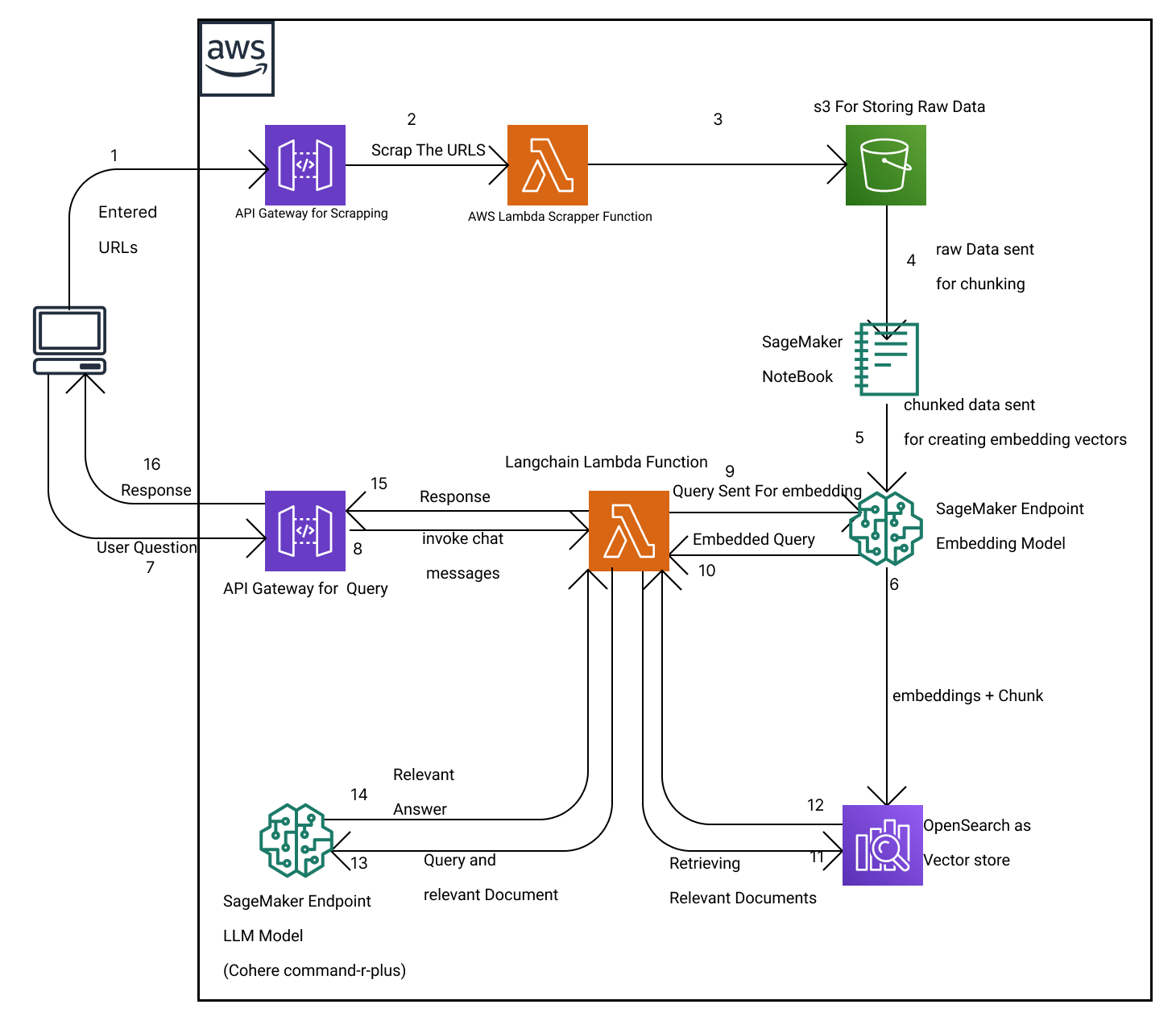
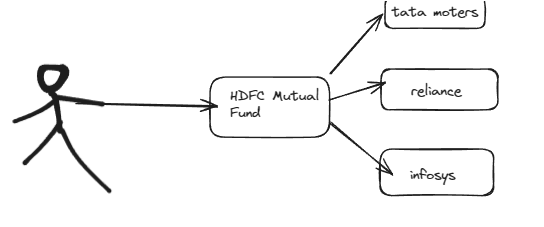
- Issue 1 : Copy pasting article in ChatGPt is tedious
- Issue 2 : We need an aggregate knowledge base
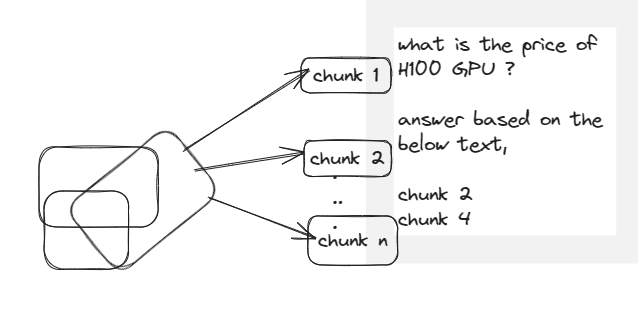


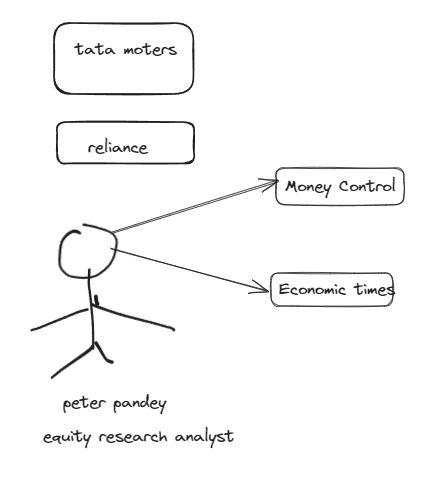
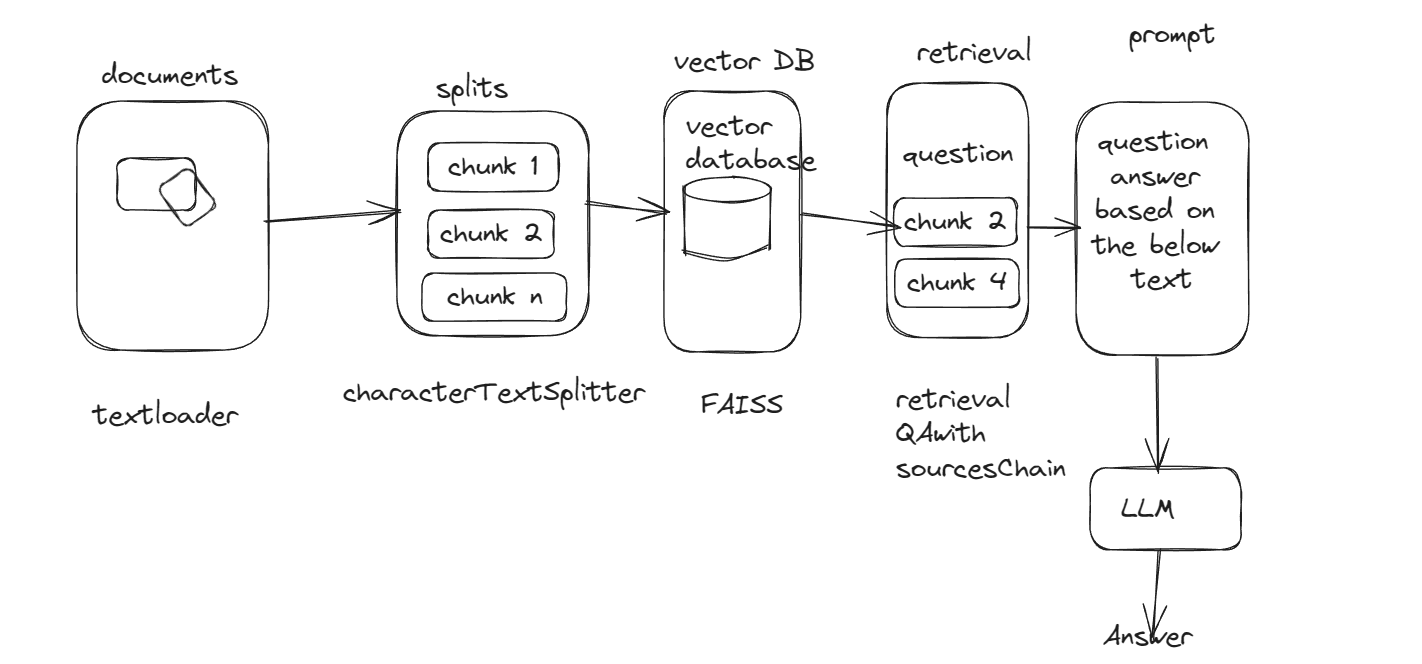
Semantic search
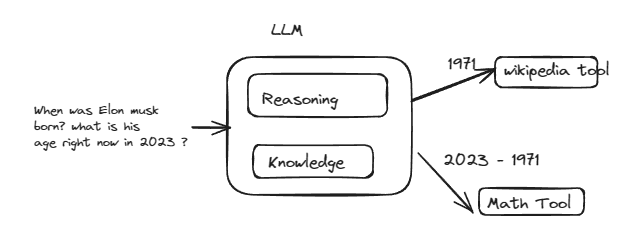
Wikipedia Google Search Google Finance duckduckGo search
git clone https://github.com/mihirh19/news_research_tool_Equity-Research-Analysis-.git
cd news_research_tool_Equity-Research-Analysis-python -m venv venv
source venv/bin/activate # On Windows use `venvScriptsactivate` pip install -r requirements.txtPrimero, debe configurar las teclas API y las variables de entorno adecuadas. Para configurarlo, cree Google_api_Key en la consola de la credencial de Google Cloud (https://console.cloud.google.com/apis/credentials) y un Google_CSE_ID usando el motor de búsqueda programable (https://programmableearchengine.google.com/controlpanel/create). A continuación, es bueno seguir las instrucciones que se encuentran aquí.
Crear clave API en https://serpapi.com/
secrets.toml en el directorio .streamlit con el siguiente contenido: GOOGLE_API_KEY = " your-google-api-key "
GOOGLE_CSE_ID = " your-cse-id "
SERP_API_KEY = " your- " streamlit run app.pywhat is the target price of tata motors ? y haga clic en Submit para obtener la respuesta. Anualreport2022223.pdf cargar el PDF dado
Haga clic en "Proceso PDF" para comenzar a procesar.
Ingrese una consulta como what is the yoy change of revenue of tata motors ? y haga clic en Submit para obtener la respuesta.
? Mihir hadavani
¡Dale una osa si este proyecto te ayudó!


