bert4torch
v0.5.4

Documentação | Torch4keras | Exemplos | build_minillm_from_scratch | Bert4Vector
Instale a versão estável
pip install bert4torchInstale a versão mais recente
pip install git+https://github.com/Tongjilibo/bert4torchgit clone https://github.com/Tongjilibo/bert4torch , modifique o caminho de arquivo de modelo pré -terenciado e o caminho de dados no exemplo para iniciar o scripttorch==1.10 e agora mudou para o desenvolvimento torch2.0 . Se outras versões encontrarem desacordos, sinta -se à vontade para feedback. Modelo LLM : Carregar pesos de modelo aberto de código aberto, como ChatGlm, Llama, Baichuan, Ziya, Bloom, etc. para inferência e ajuste fino, e implante grandes modelos em uma linha na linha de comando.
Funções principais : Carregando pesos pré-treinamento como Bert, Roberta, Albert, XLNet, Nezha, Bart, ROFORMER, ROFORMER_V2, ELECTRA, GPT, GPT2, T5, Gau-Alpha, Ernie, etc. Continue Finetune e apoiando flexivelmente o seu próprio modelo baseado em Bert.
Exemplos ricos : incluindo LLM, Pretain, sentença_classification, sentença_embedding, sequence_labeling, Relationscraction, seq2seq, porção e outras soluções
Verificação experimental : a verificação experimental foi feita no conjunto de dados públicos, usando os seguintes exemplos de dados de dados e indicadores experimentais
Truque fácil de usar : integra truques comuns, plugue e reproduza
Outros recursos : carregue o modelo da biblioteca Transformers; O método de chamada é simples e eficiente; exibição dinâmica das barras de progresso do treinamento; Imprima o volume do parâmetro com Torchinfo; Logger e Tensorboard padrão são fáceis de gravar o processo de treinamento; Processo de ajuste personalizado para atender às necessidades de alto nível
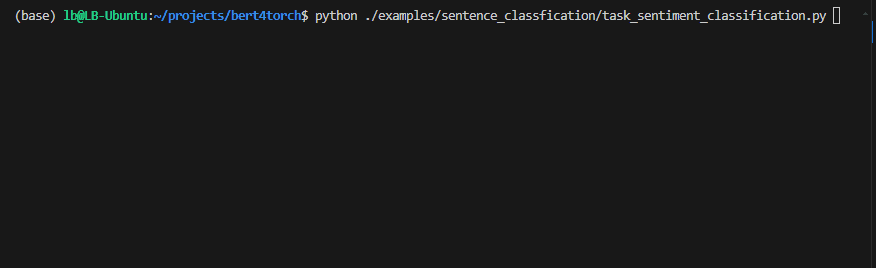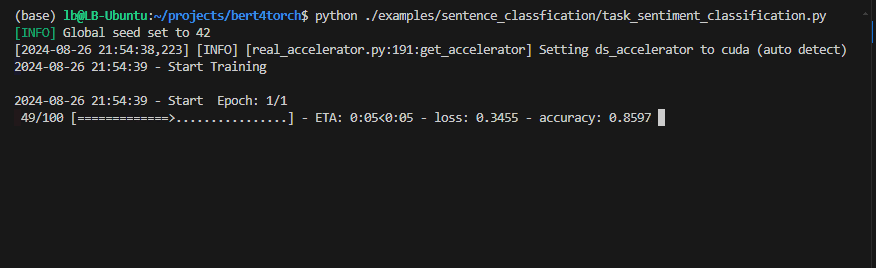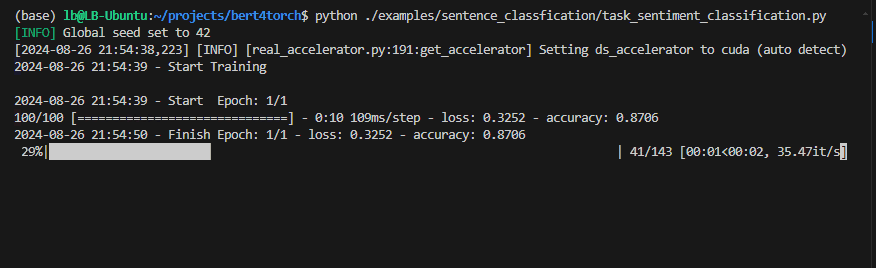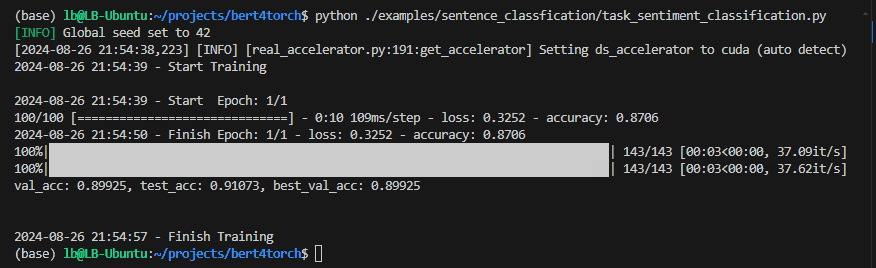
Processo de treinamento :
| Função | Bert4torch | transformadores | Observação |
|---|---|---|---|
| Barra de progresso de treinamento | ✅ | ✅ | A barra de progresso imprime perda e métricas definidas |
| Treinamento distribuído DP/DDP | ✅ | ✅ | Torch vem com DP/DDP |
| Vários retornos de chamada | ✅ | ✅ | Log/Tensorboard/EarlyStop/Wandb, etc. |
| Grande raciocínio de modelo, saída de fluxo/lote | ✅ | ✅ | Cada modelo é universal e não requer manutenção separada de scripts |
| Modelo Grande Tune Fine | ✅ | ✅ | Lora depende da biblioteca PEFT, PV2 vem com seu próprio |
| Truques ricos | ✅ | Truques plug e reproduzido contra treinamento e outros truques | |
| O código é simples e fácil de entender, e o espaço personalizado é grande | ✅ | Reutilização de código alto, estilo de treinamento de código Keras | |
| Capacidade/influência/uso/compatibilidade de manutenção do armazém | ✅ | Atualmente, manutenção pessoal do armazém | |
| Implantação de um clique de grandes modelos |
# 联网下载全部文件
bert4torch-llm-server --checkpoint_path Qwen2-0.5B-Instruct
# 加载本地大模型,联网下载bert4torch_config.json
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --config_path Qwen/Qwen2-0.5B-Instruct
# 加载本地大模型,且bert4torch_config.json已经下载并放于同名目录下
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct # 命令行
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode cli
# gradio网页
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode gradio
# openai_api
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode openai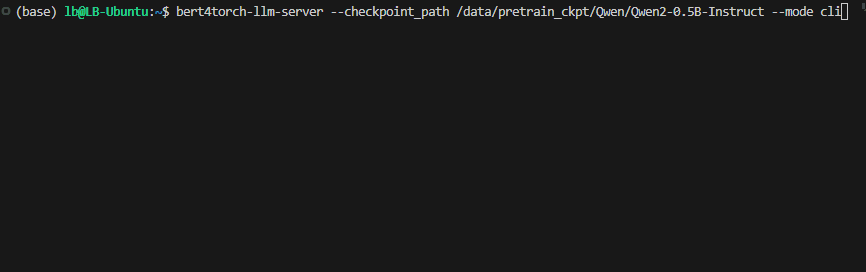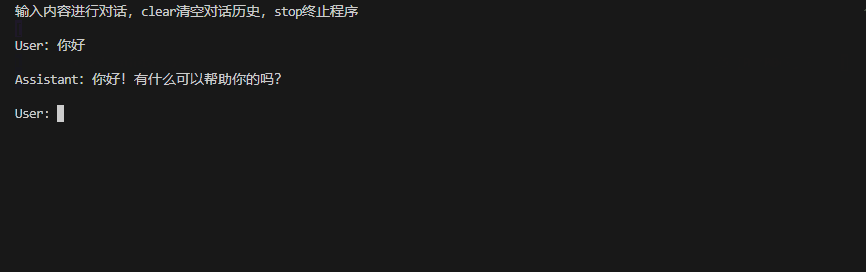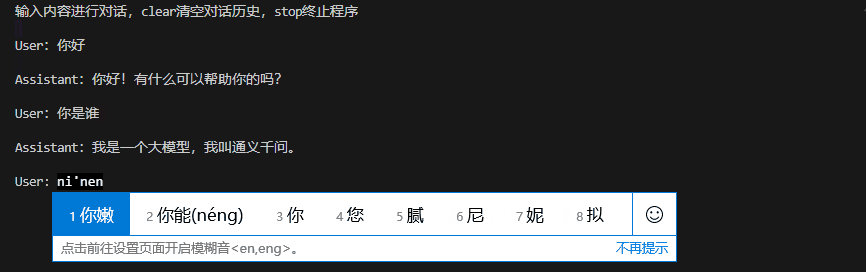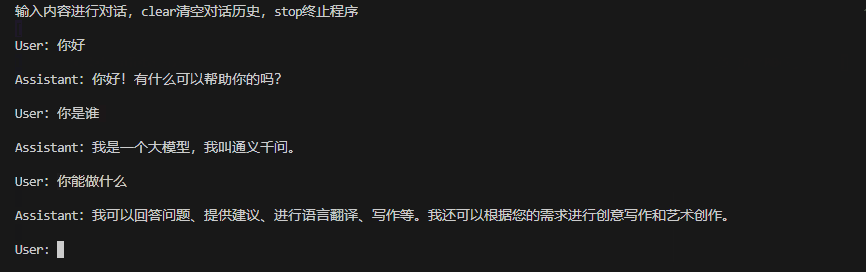
| Data de atualização | Bert4torch | Torch4keras | Descrição da versão |
|---|---|---|---|
| 20240928 | 0.5.4 | 0.2.7 | [Novos recursos] Adicionar série Deepseek, Minicpm, Minicpmv, LLAMA3.2, QWEN2.5; Suporte Device_Map = Auto; [FIX] FIXT Batch_Generate e N> 1 Bugs |
| 20240814 | 0.5.3 | 0.2.6 | 【Novos recursos】 Adicionar llama3.1/yi1.5; Selecione automaticamente o download do hfmirror; Parâmetros de linha de comando de suporte bert4torch-llm-server |
| 20240801 | 0.5.2 | 0.2.5 | [Nova função] A série ChatGlm/Qwen suporta chamadas de chamadas de função e adiciona a série InternLM2; [Pequena otimização] Simplifique a demonstração da chamada de bate -papo no pipeline, o elemento de token gerar é permitido ser uma lista, unificar o nome do parâmetro de corda e adicionar classes derivadas de corda; [Bug] Corrente flash_attn2 Bug de inferência, corrija o bug tie_word_wordding de Bart |
Mais versões
Mais história
Modelos pré-treinados suportam vários métodos de carregamento de código
from bert4torch . models import build_transformer_model
# 1. 仅指定config_path: 从头初始化模型结构, 不加载预训练模型
model = build_transformer_model ( './model/bert4torch_config.json' )
# 2. 仅指定checkpoint_path:
## 2.1 文件夹路径: 自动寻找路径下的*.bin/*.safetensors权重文件 + 需把bert4torch_config.json下载并放于该目录下
model = build_transformer_model ( checkpoint_path = './model' )
## 2.2 文件路径/列表: 文件路径即权重路径/列表, bert4torch_config.json会从同级目录下寻找
model = build_transformer_model ( checkpoint_path = './pytorch_model.bin' )
## 2.3 model_name: hf上预训练权重名称, 会自动下载hf权重以及bert4torch_config.json文件
model = build_transformer_model ( checkpoint_path = 'bert-base-chinese' )
# 3. 同时指定config_path和checkpoint_path(本地路径名或model_name排列组合):
# 本地路径从本地加载,pretrained_model_name会联网下载
config_path = './model/bert4torch_config.json' # 或'bert-base-chinese'
checkpoint_path = './model/pytorch_model.bin' # 或'bert-base-chinese'
model = build_transformer_model ( config_path , checkpoint_path )Link de peso pré -levado e bert4torch_config.json
| Classificação do modelo | Nome do modelo | Fonte de peso | Link de peso/ponto de verificação_Path | config_path |
|---|---|---|---|---|
| Bert | Bert-Base-Chinese | Google-Bert | bert-base-chinese | bert-base-chinese |
| Chinês_L-12_H-768_A-12 | Peso TFTongjilibo/bert-chinese_L-12_H-768_A-12 | |||
| Chinês-Bert-Wwm-EXT | Hfl | hfl/chinese-bert-wwm-ext | hfl/chinese-bert-wwm-ext | |
| Bert-base-multilíngue | Google-Bert | bert-base-multilingual-cased | bert-base-multilingual-cased | |
| MacBert | Hfl | hfl/chinese-macbert-basehfl/chinese-macbert-large | hfl/chinese-macbert-basehfl/chinese-macbert-large | |
| Wobert | Tecnologia Zhuyi | junnyu/wobert_chinese_base , junnyu/wobert_chinese_plus_base | junnyu/wobert_chinese_basejunnyu/wobert_chinese_plus_base | |
| Roberta | Chinês-Roberta-Wwm-Ext | Hfl | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large(O peso da MLM de grande é inicializado aleatoriamente) | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large |
| Roberta-Small/Tiny | Tecnologia Zhuyi | Tongjilibo/chinese_roberta_L-4_H-312_A-12Tongjilibo/chinese_roberta_L-6_H-384_A-12 | ||
| Roberta-Base | Facebookai | roberta-base | roberta-base | |
| Guwenbert | Ethanyt | ethanyt/guwenbert-base | ethanyt/guwenbert-base | |
| Albert | Albert_zh ALBERT_PYTORCH | Brightmart | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge |
| Nezha | Nezha Nezha_chinese_pytorch | Huawei_noah | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm |
| nezha_gpt_dialog | Bojone | Tongjilibo/nezha_gpt_dialog | ||
| xlnet | Chinês-Xlnet | Hfl | hfl/chinese-xlnet-base | hfl/chinese-xlnet-base |
| Transformer_xl | huggingface | transfo-xl/transfo-xl-wt103 | transfo-xl/transfo-xl-wt103 | |
| Deberta | Erlangshen-Deberta-V2 | IDEIA | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese |
| Electra | ELECTRA-ELECTRA | Hfl | hfl/chinese-electra-base-discriminator | hfl/chinese-electra-base-discriminator |
| Ernie | Ernie | Baidu Wenxin | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh |
| ROFORMER | ROFORMER | Tecnologia Zhuyi | junnyu/roformer_chinese_base | junnyu/roformer_chinese_base |
| roformer_v2 | Tecnologia Zhuyi | junnyu/roformer_v2_chinese_char_base | junnyu/roformer_v2_chinese_char_base | |
| Simbert | Simbert | Tecnologia Zhuyi | Tongjilibo/simbert-chinese-baseTongjilibo/simbert-chinese-smallTongjilibo/simbert-chinese-tiny | |
| Simbert_v2/roformer-sim | Tecnologia Zhuyi | junnyu/roformer_chinese_sim_char_base , junnyu/roformer_chinese_sim_char_ft_base , junnyu/roformer_chinese_sim_char_small , junnyu/roformer_chinese_sim_char_ft_small | junnyu/roformer_chinese_sim_char_basejunnyu/roformer_chinese_sim_char_ft_basejunnyu/roformer_chinese_sim_char_smalljunnyu/roformer_chinese_sim_char_ft_small | |
| gau | Gau-alfa | Tecnologia Zhuyi | Tongjilibo/chinese_GAU-alpha-char_L-24_H-768 | |
| Uie | Uie uie_pytorch | Baidu | Tongjilibo/uie-base | |
| Gpt | CDIAL-GPT | Thu-Coai | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large |
| cmp_lm (2,6 bilhões) | Tsinghua | TsinghuaAI/CPM-Generate | TsinghuaAI/CPM-Generate | |
| nezha_gen | Huawei_noah | Tongjilibo/chinese_nezha_gpt_L-12_H-768_A-12 | ||
| Gpt2-Chinese-ClueCorpussmall | Uer | uer/gpt2-chinese-cluecorpussmall | uer/gpt2-chinese-cluecorpussmall | |
| GPT2-ML | imcaspar | Torrh Baiduyun (84DH) | gpt2-ml_15g_corpusgpt2-ml_30g_corpus | |
| Bart | bart_base_chinese | FUDAN FNLP | fnlp/bart-base-chinesev1.0 | fnlp/bart-base-chinesefnlp/bart-base-chinese-v1.0 |
| T5 | T5 | Uer | uer/t5-small-chinese-cluecorpussmalluer/t5-base-chinese-cluecorpussmall | uer/t5-base-chinese-cluecorpussmalluer/t5-small-chinese-cluecorpussmall |
| mt5 | google/mt5-base | google/mt5-base | ||
| T5_PEGASUS | Tecnologia Zhuyi | Tongjilibo/chinese_t5_pegasus_smallTongjilibo/chinese_t5_pegasus_base | ||
| Chatyuan | pista-ai | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | |
| PromptClue | pista-ai | ClueAI/PromptCLUE-base | ClueAI/PromptCLUE-base | |
| chatglm | Chatglm-6b | Thudm | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4v0.1.0 | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4THUDM/chatglm-6b-v0.1.0 |
| Chatglm2-6b | Thudm | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | |
| Chatglm3-6b | Thudm | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | |
| GLM4-9B | Thudm | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | |
| lhama | lhama | Meta | meta-llama/llama-7bmeta-llama/llama-13b | |
| lhama-2 | Meta | meta-llama/llama-2-7b-hf meta-llama/llama-2-7b-chat-hf meta-llama/llama-2-13b-hf meta-llama/llama-2-13b-chat-hf | meta-llama/Llama-2-7b-hfmeta-llama/Llama-2-7b-chat-hfmeta-llama/Llama-2-13b-hfmeta-llama/Llama-2-13b-chat-hf | |
| lhama-3 | Meta | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | |
| LLAMA-3.1 | Meta | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | |
| LLAMA-3.2 | Meta | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | |
| Chinês-llama-alpaca | Hfl | hfl/chinese_alpaca_plus_7bhfl/chinese_llama_plus_7b | ||
| Chinês-llama-alpaca-2 | Hfl | A ser adicionado | ||
| Chinês-llama-alpaca-3 | Hfl | A ser adicionado | ||
| Belle_llama | Lianjiatech | BELLEGROUP/BELLE-LLAMA-7B-2M-ENC | Instruções de síntese, BelleGroup/BELLE-LLaMA-7B-2M-enc | |
| Ziya | Idea-ccnl | IDEA-CCNL/ZIYA-LLAMA-13B-V1 IDEA-CCNL/ZIYA-LLAMA-13B-V1.1 IDEA-CCNL/ZIYA-LLAMA-13B-PRESTRAIN-V1 | IDEA-CCNL/Ziya-LLaMA-13B-v1IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | |
| Vicuna | Lmsys | lmsys/vicuna-7b-v1.5 | lmsys/vicuna-7b-v1.5 | |
| Baichuan | Baichuan | Baichuan-Inc | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat |
| Baichuan2 | Baichuan-Inc | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | |
| Yi | Yi | 01-AI | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K |
| Yi-1.5 | 01-AI | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | |
| florescer | florescer | Bigscience | bigscience/bloom-560mbigscience/bloomz-560m | bigscience/bloom-560mbigscience/bloomz-560m |
| Qwen | Qwen | Cloud Alibaba | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat |
| Qwen1.5 | Cloud Alibaba | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | |
| Qwen2 | Cloud Alibaba | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | |
| QWEN2-VL | Cloud Alibaba | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | |
| Qwen2.5 | Cloud Alibaba | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | |
| Internlm | Internlm | Laboratório de Inteligência Artificial de Xangai | internlm/internlm-7binternlm/internlm-chat-7b | internlm/internlm-7binternlm/internlm-chat-7b |
| InternLM2 | Laboratório de Inteligência Artificial de Xangai | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7binternlm/internlm2-20binternlm/internlm2-chat-20b | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7b | |
| Internlm2.5 | Laboratório de Inteligência Artificial de Xangai | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | |
| Falcão | Falcão | tiiuae | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct |
| Deepseek | Deepseek-moe | Pesquisa aprofundada | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat |
| Deepseek-llm | Pesquisa aprofundada | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | |
| Deepseek-V2 | Pesquisa aprofundada | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | |
| Deepseek-Coder | Pesquisa aprofundada | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | |
| Deepseek-Coder-V2 | Pesquisa aprofundada | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | |
| Deepseek-math | Pesquisa aprofundada | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | |
| Minicpm | Minicpm | OpenBMB | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 |
| Minicpm-v | OpenBMB | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | |
| Incorporação | text2vec-bash-chinese | Shibing624 | shibing624/text2vec-base-chinese | shibing624/text2vec-base-chinese |
| m3e | Moka-AI | moka-ai/m3e-base | moka-ai/m3e-base | |
| bge | Baai | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | |
| gte | Thenlper | thenlper/gte-large-zhthenlper/gte-base-zh | thenlper/gte-base-zhthenlper/gte-large-zh |
*Observação:
高亮格式(como bert-base-chinese ) pode ser diretamente build_transformer_model() para baixar onlineHF_ENDPOINT=https://hf-mirror.com python your_script.pyexport HF_ENDPOINT=https://hf-mirror.com antes de executar o código Python import os
os . environ [ 'HF_ENDPOINT' ] = "https://hf-mirror.com" @misc{bert4torch,
title={bert4torch},
author={Bo Li},
year={2022},
howpublished={url{https://github.com/Tongjilibo/bert4torch}},
}
 WeChat ID |  Grupo WeChat | Gráfico de história da estrela |


