bert4torch
v0.5.4

Documentation | Torch4keras | Exemples | build_minillm_from_scratch | Bert4Vector
Installez la version stable
pip install bert4torchInstallez la dernière version
pip install git+https://github.com/Tongjilibo/bert4torchgit clone https://github.com/Tongjilibo/bert4torch , modifiez le chemin du fichier du modèle prétrait et le chemin de données dans l'exemple pour démarrer le scripttorch==1.10 , et est maintenant passé au développement torch2.0 . Si d'autres versions rencontrent des désaccords, n'hésitez pas à faire des commentaires. Modèle LLM : Chargez des poids de gros modèle open source tels que chatglm, llama, baichuan, ziya, floom, etc. pour une inférence et un réglage fin, et déploiez les gros modèles en une seule ligne sur la ligne de commande.
Fonctions principales : Chargement des poids pré-formation tels que Bert, Roberta, Albert, XLNET, Nezha, Bart, Roformer, Roformer_V2, Electra, GPT, GPT2, T5, Gau-alpha, Ernie, etc.
Exemples riches : y compris LLM, Pretrain, phrase_classification, phrase_embedding, Sequence_Labeling, relation_extraction, seq2seq, service et autres solutions
Vérification expérimentale : une vérification expérimentale a été effectuée sur l'ensemble de données publiques, en utilisant l'ensemble de données d'exemples suivants et les indicateurs expérimentaux
Astuce facile à utiliser : intègre des astuces communes, se brancher et jouer
Autres fonctionnalités : Chargez le modèle de bibliothèque Transformers ensemble; La méthode d'appel est simple et efficace; Affichage dynamique des barres de progression de la formation; Volume d'impression des paramètres avec torchinfo; L'enregistreur par défaut et Tensorboard sont faciles à enregistrer le processus de formation; Processus d'ajustement personnalisé pour répondre aux besoins de haut niveau
Processus de formation :
| Fonction | bert4torch | transformateurs | Remarque |
|---|---|---|---|
| Barre de progrès de la formation | ✅ | ✅ | La barre de progression imprime la perte et les mesures définies |
| Formation distribuée DP / DDP | ✅ | ✅ | Torch est livré avec DP / DDP |
| Divers rappels | ✅ | ✅ | Log / tensorboard / Earlystop / Wandb, etc. |
| Raisonnement de gros modèle, sortie de flux / lot | ✅ | ✅ | Chaque modèle est universel et ne nécessite pas de maintenance séparée des scripts |
| Grand modèle Fine Clat | ✅ | ✅ | Lora dépend de la bibliothèque PEFT, PV2 est livrée avec la sienne |
| Astuces riches | ✅ | Tricks Plug and joue contre la formation et d'autres astuces | |
| Le code est simple et facile à comprendre, et l'espace personnalisé est grand | ✅ | Réutilisation du code élevé, style de formation du code Keras | |
| Capacité de maintenance de l'entrepôt / influence / utilisation / compatibilité | ✅ | Actuellement, l'entretien personnel de l'entrepôt | |
| Déploiement en un clic de grands modèles |
# 联网下载全部文件
bert4torch-llm-server --checkpoint_path Qwen2-0.5B-Instruct
# 加载本地大模型,联网下载bert4torch_config.json
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --config_path Qwen/Qwen2-0.5B-Instruct
# 加载本地大模型,且bert4torch_config.json已经下载并放于同名目录下
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct # 命令行
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode cli
# gradio网页
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode gradio
# openai_api
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode openai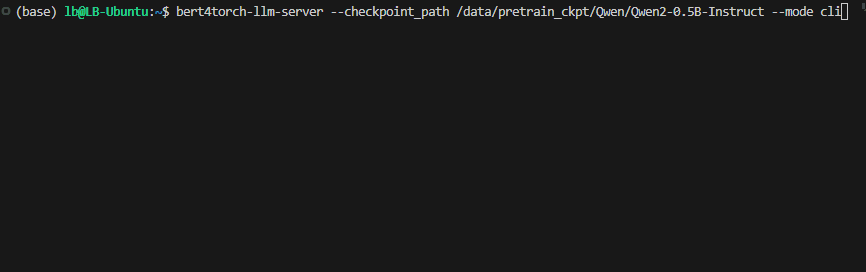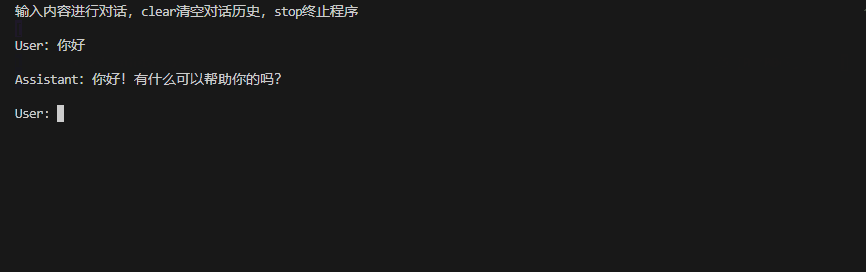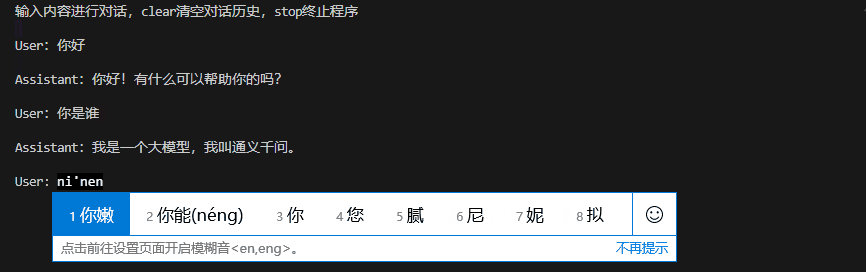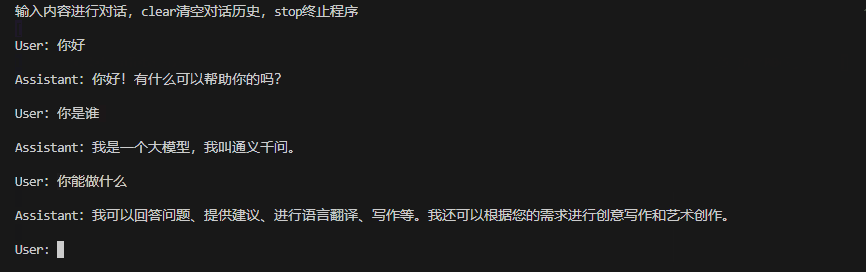
| Date de mise à jour | bert4torch | Torch4keras | Description de la version |
|---|---|---|---|
| 20240928 | 0.5.4 | 0.2.7 | [Nouvelles fonctionnalités] Ajouter une série Deepseek, MINICPM, MINICPMV, LLAMA3.2, QWEN2.5; Support Device_map = Auto; [Correction] Correction de Batch_generate et N> 1 Bogues |
| 20240814 | 0.5.3 | 0.2.6 | 【Nouvelles fonctionnalités】 Ajouter LLAMA3.1 / YI1.5; Sélectionnez automatiquement le téléchargement à partir de hfMirror; Prise en charge des paramètres de ligne de commande bert4torch-llm-server |
| 20240801 | 0.5.2 | 0.2.5 | [Nouvelle fonction] La série ChatGLM / QWEN prend en charge les appels de fonction et ajoute des séries Interlm2; [Petite optimisation] Simplifier la démo de l'appel de Chat dans le pipeline, Générer un élément de jeton est autorisé à être une liste, à unifier le nom du paramètre ROPE_SCALING et à ajouter des classes dérivées de la corde; [Bogue] Correction du bug d'inférence Flash_Attn2, corrigez le bogue Tie_Word_Embedding de Bart |
Plus de versions
Plus d'histoire
Les modèles pré-formés prennent en charge plusieurs méthodes de chargement de code
from bert4torch . models import build_transformer_model
# 1. 仅指定config_path: 从头初始化模型结构, 不加载预训练模型
model = build_transformer_model ( './model/bert4torch_config.json' )
# 2. 仅指定checkpoint_path:
## 2.1 文件夹路径: 自动寻找路径下的*.bin/*.safetensors权重文件 + 需把bert4torch_config.json下载并放于该目录下
model = build_transformer_model ( checkpoint_path = './model' )
## 2.2 文件路径/列表: 文件路径即权重路径/列表, bert4torch_config.json会从同级目录下寻找
model = build_transformer_model ( checkpoint_path = './pytorch_model.bin' )
## 2.3 model_name: hf上预训练权重名称, 会自动下载hf权重以及bert4torch_config.json文件
model = build_transformer_model ( checkpoint_path = 'bert-base-chinese' )
# 3. 同时指定config_path和checkpoint_path(本地路径名或model_name排列组合):
# 本地路径从本地加载,pretrained_model_name会联网下载
config_path = './model/bert4torch_config.json' # 或'bert-base-chinese'
checkpoint_path = './model/pytorch_model.bin' # 或'bert-base-chinese'
model = build_transformer_model ( config_path , checkpoint_path )Lien de poids pré-entraîné et bert4torch_config.json
| Classification du modèle | Nom du modèle | Source de poids | Lien de poids / checkpoint_path | config_path |
|---|---|---|---|---|
| bert | bert-bassin-chinois | google-abri | bert-base-chinese | bert-base-chinese |
| chinois_l-12_h-768_a-12 | TFTongjilibo/bert-chinese_L-12_H-768_A-12 | |||
| chinois-bert-wwm-ext | HFL | hfl/chinese-bert-wwm-ext | hfl/chinese-bert-wwm-ext | |
| bert-base-multitilingue à base | google-abri | bert-base-multilingual-cased | bert-base-multilingual-cased | |
| Macbert | HFL | hfl/chinese-macbert-basehfl/chinese-macbert-large | hfl/chinese-macbert-basehfl/chinese-macbert-large | |
| Wobert | Technologie Zhuyi | junnyu/wobert_chinese_base , junnyu/wobert_chinese_plus_base | junnyu/wobert_chinese_basejunnyu/wobert_chinese_plus_base | |
| Roberta | Chinese-Roberta-WWM-EXT | HFL | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large(Le poids MLM de Large est initialisé au hasard) | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large |
| Roberta-Small / Tiny | Technologie Zhuyi | Tongjilibo/chinese_roberta_L-4_H-312_A-12Tongjilibo/chinese_roberta_L-6_H-384_A-12 | ||
| base de Roberta | Facebookai | roberta-base | roberta-base | |
| Guwenbert | ethanyt | ethanyt/guwenbert-base | ethanyt/guwenbert-base | |
| Albert | albert_zh albert_pytorch | brillant | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge |
| Nezha | Nezha Nezha_chinese_pytorch | huawei_noah | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm |
| nezha_gpt_dialog | bojone | Tongjilibo/nezha_gpt_dialog | ||
| xlnet | Chinois-xlnet | HFL | hfl/chinese-xlnet-base | hfl/chinese-xlnet-base |
| transformateur_xl | étreinte | transfo-xl/transfo-xl-wt103 | transfo-xl/transfo-xl-wt103 | |
| deberta | Erlangshen-deberta-v2 | IDÉE | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese |
| électra | Chinois-électra | HFL | hfl/chinese-electra-base-discriminator | hfl/chinese-electra-base-discriminator |
| Ernie | Ernie | Baidu wenxin | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh |
| roformer | roformer | Technologie Zhuyi | junnyu/roformer_chinese_base | junnyu/roformer_chinese_base |
| roformer_v2 | Technologie Zhuyi | junnyu/roformer_v2_chinese_char_base | junnyu/roformer_v2_chinese_char_base | |
| timide | timide | Technologie Zhuyi | Tongjilibo/simbert-chinese-baseTongjilibo/simbert-chinese-smallTongjilibo/simbert-chinese-tiny | |
| simbert_v2 / roformer-sim | Technologie Zhuyi | junnyu/roformer_chinese_sim_char_base , junnyu/roformer_chinese_sim_char_ft_base , junnyu/roformer_chinese_sim_char_small , junnyu/roformer_chinese_sim_char_ft_small | junnyu/roformer_chinese_sim_char_basejunnyu/roformer_chinese_sim_char_ft_basejunnyu/roformer_chinese_sim_char_smalljunnyu/roformer_chinese_sim_char_ft_small | |
| gazouillis | Mât alpha | Technologie Zhuyi | Tongjilibo/chinese_GAU-alpha-char_L-24_H-768 | |
| Uie | Uie uie_pytorch | Baidu | Tongjilibo/uie-base | |
| gp | CDIAL-GPT | thu-coai | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large |
| CMP_LM (2,6 milliards) | Tsinghua | TsinghuaAI/CPM-Generate | TsinghuaAI/CPM-Generate | |
| Nezha_gen | huawei_noah | Tongjilibo/chinese_nezha_gpt_L-12_H-768_A-12 | ||
| gpt2-chinois-Cluecorpussmall | Uer | uer/gpt2-chinese-cluecorpussmall | uer/gpt2-chinese-cluecorpussmall | |
| gpt2-ml | imcaspar | torrh Baiduyun (84dh) | gpt2-ml_15g_corpusgpt2-ml_30g_corpus | |
| barbe | bart_base_chinese | FUDAN FNLP | fnlp/bart-base-chinesev1.0 | fnlp/bart-base-chinesefnlp/bart-base-chinese-v1.0 |
| t5 | t5 | Uer | uer/t5-small-chinese-cluecorpussmalluer/t5-base-chinese-cluecorpussmall | uer/t5-base-chinese-cluecorpussmalluer/t5-small-chinese-cluecorpussmall |
| MT5 | google/mt5-base | google/mt5-base | ||
| t5_pegasus | Technologie Zhuyi | Tongjilibo/chinese_t5_pegasus_smallTongjilibo/chinese_t5_pegasus_base | ||
| chatyuan | Clue-ai | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | |
| Prompt-clue | Clue-ai | ClueAI/PromptCLUE-base | ClueAI/PromptCLUE-base | |
| chatglm | chatglm-6b | Jumeau | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4v0.1.0 | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4THUDM/chatglm-6b-v0.1.0 |
| chatglm2-6b | Jumeau | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | |
| chatglm3-6b | Jumeau | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | |
| GLM4-9B | Jumeau | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | |
| lama | lama | méta | meta-llama/llama-7bmeta-llama/llama-13b | |
| lama-2 | méta | méta-llama / lama-2-7b-hf méta-llama / lama-2-7b-chat-hf méta-llama / lama-2-13b-hf méta-llama / lama-2-13b-chat-hf | meta-llama/Llama-2-7b-hfmeta-llama/Llama-2-7b-chat-hfmeta-llama/Llama-2-13b-hfmeta-llama/Llama-2-13b-chat-hf | |
| lama-3 | méta | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | |
| lama-3.1 | méta | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | |
| lama-3.2 | méta | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | |
| Chinois-llama-alpaca | HFL | hfl/chinese_alpaca_plus_7bhfl/chinese_llama_plus_7b | ||
| Chinese-Llama-Alpaca-2 | HFL | À ajouter | ||
| Chinese-Llama-Alpaca-3 | HFL | À ajouter | ||
| Belle_Llama | Lianjatech | BelleGroup / Belle-Ellema-7B-2M-ENC | Instructions de synthèse, BelleGroup/BELLE-LLaMA-7B-2M-enc | |
| Ziya | IDEA-CCNL | IDEA-CCNL / ZIYA-LALAMA-13B-V1 IDEA-CCNL / ZIYA-LALAMA-13B-V1.1 IDEA-CCNL / ZIYA-LALAMA-13B-PRETRAIN-V1 | IDEA-CCNL/Ziya-LLaMA-13B-v1IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | |
| vicuna | LMSYS | lmsys/vicuna-7b-v1.5 | lmsys/vicuna-7b-v1.5 | |
| Baichuan | Baichuan | baichuan-inc | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat |
| Baichuan2 | baichuan-inc | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | |
| Yi | Yi | 01-AI | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K |
| Yi-1,5 | 01-AI | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | |
| floraison | floraison | bigscience | bigscience/bloom-560mbigscience/bloomz-560m | bigscience/bloom-560mbigscience/bloomz-560m |
| Qwen | Qwen | Nuage d'alibaba | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat |
| Qwen1.5 | Nuage d'alibaba | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | |
| Qwen2 | Nuage d'alibaba | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | |
| Qwen2-vl | Nuage d'alibaba | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | |
| Qwen2.5 | Nuage d'alibaba | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | |
| Interne | Interne | Laboratoire d'intelligence artificielle de Shanghai | internlm/internlm-7binternlm/internlm-chat-7b | internlm/internlm-7binternlm/internlm-chat-7b |
| Interlm2 | Laboratoire d'intelligence artificielle de Shanghai | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7binternlm/internlm2-20binternlm/internlm2-chat-20b | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7b | |
| Interlm2.5 | Laboratoire d'intelligence artificielle de Shanghai | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | |
| Faucon | Faucon | tiiuae | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct |
| En profondeur | Profondeur de profondeur | Recherche approfondie | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat |
| Deepseek-llm | Recherche approfondie | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | |
| Deepseek-V2 | Recherche approfondie | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | |
| Coder en profondeur | Recherche approfondie | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | |
| Coder profonde-v2 | Recherche approfondie | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | |
| Deepseek-Math | Recherche approfondie | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | |
| Minimicpm | Minimicpm | OpenBMB | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 |
| Minicpm-v | OpenBMB | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | |
| Intégration | text2vec-bass-chinois | shibing624 | shibing624/text2vec-base-chinese | shibing624/text2vec-base-chinese |
| m3e | moka-ai | moka-ai/m3e-base | moka-ai/m3e-base | |
| bge | Baai | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | |
| goer | Alors | thenlper/gte-large-zhthenlper/gte-base-zh | thenlper/gte-base-zhthenlper/gte-large-zh |
*Note:
高亮格式(comme bert-base-chinese ) peut être directement build_transformer_model() à télécharger en ligneHF_ENDPOINT=https://hf-mirror.com python your_script.pyexport HF_ENDPOINT=https://hf-mirror.com avant d'exécuter le code Python import os
os . environ [ 'HF_ENDPOINT' ] = "https://hf-mirror.com" @misc{bert4torch,
title={bert4torch},
author={Bo Li},
year={2022},
howpublished={url{https://github.com/Tongjilibo/bert4torch}},
}
 ID de WeChat |  Groupe de WeChat | Star History Chart |


