bert4torch
v0.5.4

Documentation | Torch4keras | Examples | build_MiniLLM_from_scratch | bert4vector
Install stable version
pip install bert4torchInstall the latest version
pip install git+https://github.com/Tongjilibo/bert4torchgit clone https://github.com/Tongjilibo/bert4torch , modify the pretrained model file path and data path in the example to start the scripttorch==1.10 version, and has now switched to torch2.0 development. If other versions encounter disagreements, please feel free to feedback. LLM model : Load open source big model weights such as chatglm, llama, baichuan, ziya, bloom, etc. for inference and fine-tuning, and deploy big models in one line on the command line.
Core functions : Loading pre-training weights such as bert, roberta, albert, xlnet, nezha, bart, RoFormer, RoFormer_V2, ELECTRA, GPT, GPT2, T5, GAU-alpha, ERNIE, etc. continue to finetune, and support flexibly defining your own model based on bert
Rich examples : including llm, pretrain, sentence_classification, sentence_embedding, sequence_labeling, relationship_extraction, seq2seq, serving and other solutions
Experimental verification : Experimental verification has been made on the public data set, using the following examples data set and experimental indicators
Easy-to-use trick : integrates common tricks, plug and play
Other features : load the transformers library model together; call method is simple and efficient; dynamic display of training progress bars; print parameter volume with torchinfo; default Logger and Tensorboard are easy to record the training process; custom fit process to meet high-level needs
Training process :
| Function | bert4torch | transformers | Remark |
|---|---|---|---|
| Training progress bar | ✅ | ✅ | Progress bar prints loss and defined metrics |
| Distributed training dp/ddp | ✅ | ✅ | Torch comes with dp/ddp |
| Various callbacks | ✅ | ✅ | Log/tensorboard/earlystop/wandb, etc. |
| Big model reasoning, stream/batch output | ✅ | ✅ | Each model is universal and does not require separate maintenance of scripts |
| Large model fine tune | ✅ | ✅ | Lora depends on the peft library, PV2 comes with its own |
| Rich tricks | ✅ | Tricks plug and play against training and other tricks | |
| The code is simple and easy to understand, and the custom space is large | ✅ | High code reuse, keras code training style | |
| Warehouse maintenance capability/influence/usage/compatibility | ✅ | Currently, personal maintenance of the warehouse | |
| One-click deployment of large models |
# 联网下载全部文件
bert4torch-llm-server --checkpoint_path Qwen2-0.5B-Instruct
# 加载本地大模型,联网下载bert4torch_config.json
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --config_path Qwen/Qwen2-0.5B-Instruct
# 加载本地大模型,且bert4torch_config.json已经下载并放于同名目录下
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct # 命令行
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode cli
# gradio网页
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode gradio
# openai_api
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode openai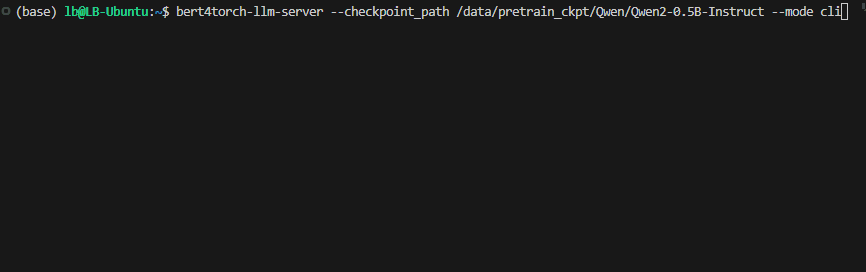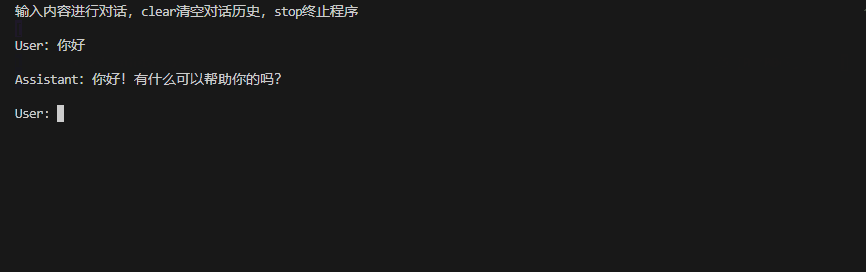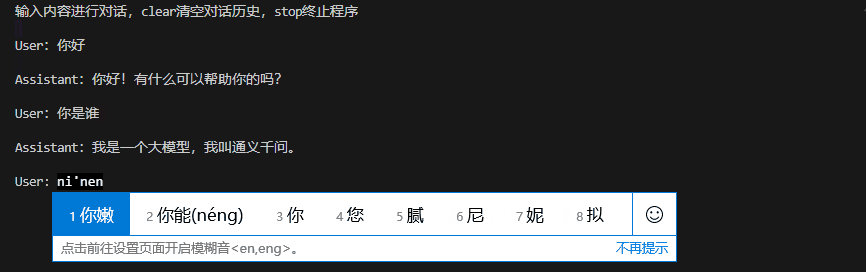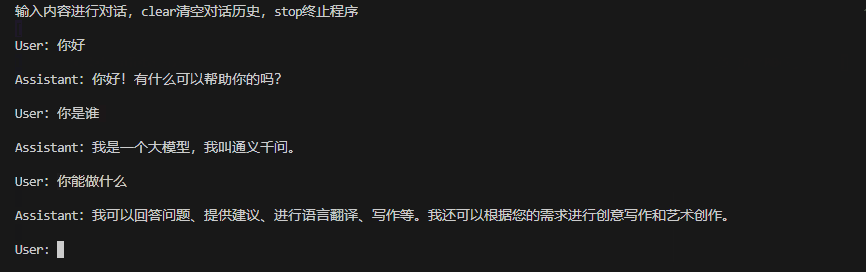
| Update date | bert4torch | torch4keras | Version Description |
|---|---|---|---|
| 20240928 | 0.5.4 | 0.2.7 | [New Features] Add deepseek series, MiniCPM, MiniCPMV, llama3.2, Qwen2.5; support device_map=auto; [Fix] Fix batch_generate and n>1 bugs |
| 20240814 | 0.5.3 | 0.2.6 | 【New Features】Add llama3.1/Yi1.5; Automatically select download from hfmirror; support command line parameters bert4torch-llm-server |
| 20240801 | 0.5.2 | 0.2.5 | [New function] Chatglm/qwen series supports function call calls, and adds internlm2 series; [Small optimization] Simplify the call of chat demo in pipeline, generate token element is allowed to be a list, unify the rope_scaling parameter name, and add rope derived classes; [bug] Fix flash_attn2 inference bug, fix bart's tie_word_embedding bug |
More versions
More history
Pre-trained models support multiple code loading methods
from bert4torch . models import build_transformer_model
# 1. 仅指定config_path: 从头初始化模型结构, 不加载预训练模型
model = build_transformer_model ( './model/bert4torch_config.json' )
# 2. 仅指定checkpoint_path:
## 2.1 文件夹路径: 自动寻找路径下的*.bin/*.safetensors权重文件 + 需把bert4torch_config.json下载并放于该目录下
model = build_transformer_model ( checkpoint_path = './model' )
## 2.2 文件路径/列表: 文件路径即权重路径/列表, bert4torch_config.json会从同级目录下寻找
model = build_transformer_model ( checkpoint_path = './pytorch_model.bin' )
## 2.3 model_name: hf上预训练权重名称, 会自动下载hf权重以及bert4torch_config.json文件
model = build_transformer_model ( checkpoint_path = 'bert-base-chinese' )
# 3. 同时指定config_path和checkpoint_path(本地路径名或model_name排列组合):
# 本地路径从本地加载,pretrained_model_name会联网下载
config_path = './model/bert4torch_config.json' # 或'bert-base-chinese'
checkpoint_path = './model/pytorch_model.bin' # 或'bert-base-chinese'
model = build_transformer_model ( config_path , checkpoint_path )Pretrained weight link and bert4torch_config.json
| Model classification | Model name | Source of weight | Weight link/checkpoint_path | config_path |
|---|---|---|---|---|
| bert | bert-base-chinese | google-bert | bert-base-chinese | bert-base-chinese |
| chinese_L-12_H-768_A-12 | TF weightTongjilibo/bert-chinese_L-12_H-768_A-12 | |||
| chinese-bert-wwm-ext | HFL | hfl/chinese-bert-wwm-ext | hfl/chinese-bert-wwm-ext | |
| bert-base-multilingual-cased | google-bert | bert-base-multilingual-cased | bert-base-multilingual-cased | |
| MacBERT | HFL | hfl/chinese-macbert-basehfl/chinese-macbert-large | hfl/chinese-macbert-basehfl/chinese-macbert-large | |
| WoBERT | Zhuyi Technology | junnyu/wobert_chinese_base , junnyu/wobert_chinese_plus_base | junnyu/wobert_chinese_basejunnyu/wobert_chinese_plus_base | |
| roberta | chinese-roberta-wwm-ext | HFL | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large(Large's mlm weight is randomly initialized) | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large |
| roberta-small/tiny | Zhuyi Technology | Tongjilibo/chinese_roberta_L-4_H-312_A-12Tongjilibo/chinese_roberta_L-6_H-384_A-12 | ||
| roberta-base | FacebookAI | roberta-base | roberta-base | |
| guwenbert | ethanyt | ethanyt/guwenbert-base | ethanyt/guwenbert-base | |
| albert | albert_zh albert_pytorch | brightmart | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge |
| nezha | NEZHA NeZha_Chinese_PyTorch | huawei_noah | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm |
| nezha_gpt_dialog | bojone | Tongjilibo/nezha_gpt_dialog | ||
| xlnet | Chinese-XLNet | HFL | hfl/chinese-xlnet-base | hfl/chinese-xlnet-base |
| transformer_xl | huggingface | transfo-xl/transfo-xl-wt103 | transfo-xl/transfo-xl-wt103 | |
| deberta | Erlangshen-DeBERTa-v2 | IDEA | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese |
| electra | Chinese-ELECTRA | HFL | hfl/chinese-electra-base-discriminator | hfl/chinese-electra-base-discriminator |
| ernie | ernie | Baidu Wenxin | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh |
| roformer | roformer | Zhuyi Technology | junnyu/roformer_chinese_base | junnyu/roformer_chinese_base |
| roformer_v2 | Zhuyi Technology | junnyu/roformer_v2_chinese_char_base | junnyu/roformer_v2_chinese_char_base | |
| simbert | simbert | Zhuyi Technology | Tongjilibo/simbert-chinese-baseTongjilibo/simbert-chinese-smallTongjilibo/simbert-chinese-tiny | |
| simbert_v2/roformer-sim | Zhuyi Technology | junnyu/roformer_chinese_sim_char_base , junnyu/roformer_chinese_sim_char_ft_base , junnyu/roformer_chinese_sim_char_small , junnyu/roformer_chinese_sim_char_ft_small | junnyu/roformer_chinese_sim_char_basejunnyu/roformer_chinese_sim_char_ft_basejunnyu/roformer_chinese_sim_char_smalljunnyu/roformer_chinese_sim_char_ft_small | |
| gau | GAU-alpha | Zhuyi Technology | Tongjilibo/chinese_GAU-alpha-char_L-24_H-768 | |
| Uie | Uie uie_pytorch | Baidu | Tongjilibo/uie-base | |
| gpt | CDial-GPT | thu-coai | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large |
| cmp_lm(2.6 billion) | Tsinghua | TsinghuaAI/CPM-Generate | TsinghuaAI/CPM-Generate | |
| nezha_gen | huawei_noah | Tongjilibo/chinese_nezha_gpt_L-12_H-768_A-12 | ||
| gpt2-chinese-cluecorpussmall | UER | uer/gpt2-chinese-cluecorpussmall | uer/gpt2-chinese-cluecorpussmall | |
| gpt2-ml | imcaspar | torrh BaiduYun(84dh) | gpt2-ml_15g_corpusgpt2-ml_30g_corpus | |
| bart | bart_base_chinese | Fudan fnlp | fnlp/bart-base-chinesev1.0 | fnlp/bart-base-chinesefnlp/bart-base-chinese-v1.0 |
| t5 | t5 | UER | uer/t5-small-chinese-cluecorpussmalluer/t5-base-chinese-cluecorpussmall | uer/t5-base-chinese-cluecorpussmalluer/t5-small-chinese-cluecorpussmall |
| mt5 | google/mt5-base | google/mt5-base | ||
| t5_pegasus | Zhuyi Technology | Tongjilibo/chinese_t5_pegasus_smallTongjilibo/chinese_t5_pegasus_base | ||
| chatyuan | clue-ai | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | |
| PromptCLUE | clue-ai | ClueAI/PromptCLUE-base | ClueAI/PromptCLUE-base | |
| chatglm | chatglm-6b | THUDM | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4v0.1.0 | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4THUDM/chatglm-6b-v0.1.0 |
| chatglm2-6b | THUDM | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | |
| chatglm3-6b | THUDM | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | |
| glm4-9b | THUDM | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | |
| llama | llama | meta | meta-llama/llama-7bmeta-llama/llama-13b | |
| llama-2 | meta | meta-llama/Llama-2-7b-hf meta-llama/Llama-2-7b-chat-hf meta-llama/Llama-2-13b-hf meta-llama/Llama-2-13b-chat-hf | meta-llama/Llama-2-7b-hfmeta-llama/Llama-2-7b-chat-hfmeta-llama/Llama-2-13b-hfmeta-llama/Llama-2-13b-chat-hf | |
| llama-3 | meta | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | |
| llama-3.1 | meta | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | |
| llama-3.2 | meta | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | |
| Chinese-LLaMA-Alpaca | HFL | hfl/chinese_alpaca_plus_7bhfl/chinese_llama_plus_7b | ||
| Chinese-LLaMA-Alpaca-2 | HFL | To be added | ||
| Chinese-LLaMA-Alpaca-3 | HFL | To be added | ||
| Belle_llama | LianjiaTech | BelleGroup/BELLE-LLaMA-7B-2M-enc | Synthesis instructions, BelleGroup/BELLE-LLaMA-7B-2M-enc | |
| Ziya | IDEA-CCNL | IDEA-CCNL/Ziya-LLaMA-13B-v1 IDEA-CCNL/Ziya-LLaMA-13B-v1.1 IDEA-CCNL/Ziya-LLaMA-13B-Pretrain-v1 | IDEA-CCNL/Ziya-LLaMA-13B-v1IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | |
| vicuna | lmsys | lmsys/vicuna-7b-v1.5 | lmsys/vicuna-7b-v1.5 | |
| Baichuan | Baichuan | baichuan-inc | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat |
| Baichuan2 | baichuan-inc | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | |
| Yi | Yi | 01-ai | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K |
| Yi-1.5 | 01-ai | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | |
| bloom | bloom | bigscience | bigscience/bloom-560mbigscience/bloomz-560m | bigscience/bloom-560mbigscience/bloomz-560m |
| Qwen | Qwen | Alibaba Cloud | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat |
| Qwen1.5 | Alibaba Cloud | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | |
| Qwen2 | Alibaba Cloud | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | |
| Qwen2-VL | Alibaba Cloud | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | |
| Qwen2.5 | Alibaba Cloud | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | |
| InternLM | InternLM | Shanghai Artificial Intelligence Laboratory | internlm/internlm-7binternlm/internlm-chat-7b | internlm/internlm-7binternlm/internlm-chat-7b |
| InternLM2 | Shanghai Artificial Intelligence Laboratory | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7binternlm/internlm2-20binternlm/internlm2-chat-20b | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7b | |
| InternLM2.5 | Shanghai Artificial Intelligence Laboratory | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | |
| Falcon | Falcon | tiiuae | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct |
| DeepSeek | DeepSeek-MoE | In-depth search | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat |
| DeepSeek-LLM | In-depth search | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | |
| DeepSeek-V2 | In-depth search | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | |
| DeepSeek-Coder | In-depth search | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | |
| DeepSeek-Coder-V2 | In-depth search | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | |
| DeepSeek-Math | In-depth search | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | |
| MiniCPM | MiniCPM | OpenBMB | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 |
| MiniCPM-V | OpenBMB | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | |
| Embedding | text2vec-base-chinese | shibing624 | shibing624/text2vec-base-chinese | shibing624/text2vec-base-chinese |
| m3e | moka-ai | moka-ai/m3e-base | moka-ai/m3e-base | |
| bge | BAAI | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | |
| gte | Thenlper | thenlper/gte-large-zhthenlper/gte-base-zh | thenlper/gte-base-zhthenlper/gte-large-zh |
*Note:
高亮格式(such as bert-base-chinese ) can be directly build_transformer_model() to download onlineHF_ENDPOINT=https://hf-mirror.com python your_script.pyexport HF_ENDPOINT=https://hf-mirror.com before executing python code import os
os . environ [ 'HF_ENDPOINT' ] = "https://hf-mirror.com" @misc{bert4torch,
title={bert4torch},
author={Bo Li},
year={2022},
howpublished={url{https://github.com/Tongjilibo/bert4torch}},
}
 WeChat ID |  WeChat group | Star History Chart |


