bert4torch
v0.5.4

Dokumentation | Torch4keras | Beispiele | Build_minillm_from_Scratch | Bert4Vector
Stabile Version installieren
pip install bert4torchInstallieren Sie die neueste Version
pip install git+https://github.com/Tongjilibo/bert4torchgit clone https://github.com/Tongjilibo/bert4torch , änderntorch==1.10 -Version verwendet und ist nun auf die Entwicklung torch2.0 umgestellt. Wenn andere Versionen auf Meinungsverschiedenheiten stoßen, können Sie sich gerne Feedback geben. LLM-Modell : Laden Sie Open Source Big Model Gewichte wie Chatglm, Lama, Baichuan, Ziya, Blüte usw. Für Inferenz und Feinabstimmung und Bereitstellung großer Modelle in einer Zeile in der Befehlszeile.
Kernfunktionen : Laden Sie vor dem Training Gewichten wie Bert, Roberta, Albert, XLNet, Nezha, Bart, Roformer, für Roformer_v2, Electra, GPT, GPT2, T5, Gau-Alpha, Ernie usw.
Reiche Beispiele : Einschließlich LLM, Pretrain, Satzklassifizierung, Satz_Mbedding, Sequence_Labeling, Beziehung_Extraction, SEQ2SEQ, Serving und andere Lösungen
Experimentelle Überprüfung : Die experimentelle Überprüfung wurde im öffentlichen Datensatz unter Verwendung der folgenden Beispiele Datensatz und experimentellen Indikatoren durchgeführt
Einfach zu bedienender Trick : Integriert gemeinsame Tricks, Plug-and-Play
Andere Merkmale : Laden Sie das Transformers Library -Modell zusammen; Die Anrufmethode ist einfach und effizient; dynamische Anzeige von Trainingsfortschrittsbalken; Druckparametervolumen mit Torchinfo; Standardprotokoller und Tensorboard sind einfach den Trainingsprozess aufzunehmen. benutzerdefinierte Anpassungsprozess, um die Bedürfnisse auf hoher Ebene zu erfüllen
Schulungsprozess :
| Funktion | Bert4Torch | Transformatoren | Bemerkung |
|---|---|---|---|
| Trainingsfortschrittsbalken | ✅ | ✅ | Fortschrittsbalken druckt Verlust und definierte Metriken |
| Verteilter Training DP/DDP | ✅ | ✅ | Fackel wird mit DP/DDP geliefert |
| Verschiedene Rückrufe | ✅ | ✅ | Protokoll/Tensorboard/Earlystop/Wandb usw. |
| Großmodell -Argumentation, Stream/Stapelausgabe | ✅ | ✅ | Jedes Modell ist universell und erfordert keine separate Wartung von Skripten |
| Große Modellfeinstimmung | ✅ | ✅ | Lora hängt von der PEFT -Bibliothek ab, Pv2 kommt mit seinen eigenen |
| Reiche Tricks | ✅ | Tricks Plug & Play gegen Training und andere Tricks | |
| Der Code ist einfach und leicht zu verstehen, und der benutzerdefinierte Raum ist groß | ✅ | Wiederverwendung mit hoher Code, Keras -Code -Trainingsstil | |
| Lagerhaltung/Einfluss/Einfluss/Verwendung/Kompatibilität | ✅ | Derzeit persönliche Wartung des Lagerhauses | |
| Ein-Klick-Bereitstellung großer Modelle |
# 联网下载全部文件
bert4torch-llm-server --checkpoint_path Qwen2-0.5B-Instruct
# 加载本地大模型,联网下载bert4torch_config.json
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --config_path Qwen/Qwen2-0.5B-Instruct
# 加载本地大模型,且bert4torch_config.json已经下载并放于同名目录下
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct # 命令行
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode cli
# gradio网页
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode gradio
# openai_api
bert4torch-llm-server --checkpoint_path /data/pretrain_ckpt/Qwen/Qwen2-0.5B-Instruct --mode openai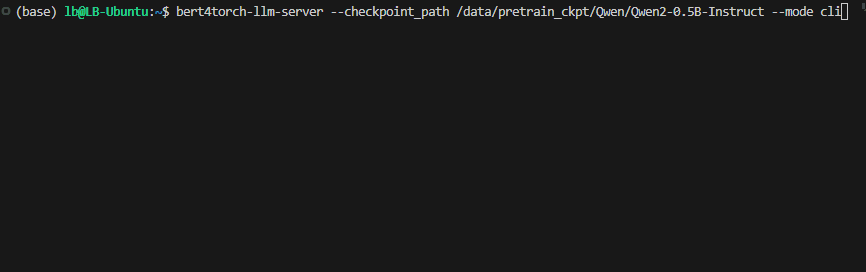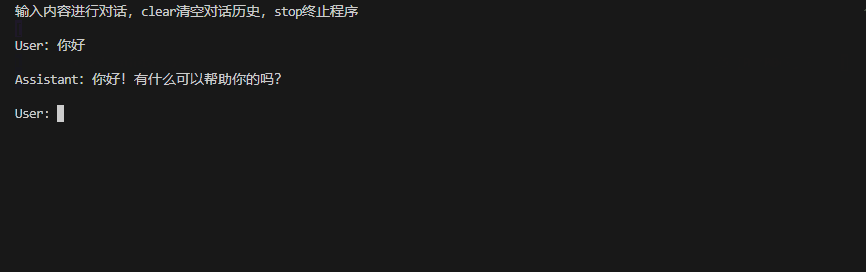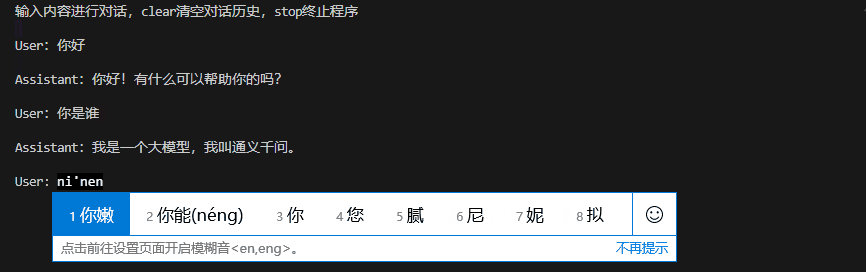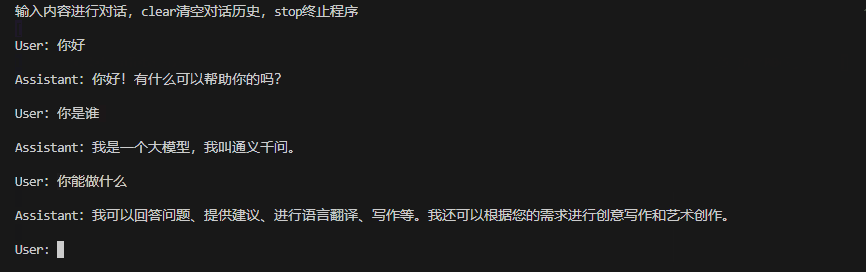
| Datum aktualisieren | Bert4Torch | Torch4keras | Versionsbeschreibung |
|---|---|---|---|
| 20240928 | 0.5.4 | 0.2.7 | [Neue Funktionen] Fügen Sie Deepseek Series, Minicpm, Minicpmv, Lama3.2, Qwen2.5 hinzu; Support Device_map = Auto; [Fix] Fix Batch_generate und N> 1 Fehler |
| 20240814 | 0.5.3 | 0.2.6 | 【Neue Funktionen】 Lama3.1/yi1.5 hinzufügen; Wählen Sie automatisch Download von HFMirror aus; Unterstützen Sie Befehlszeilenparameter bert4torch-llm-server |
| 20240801 | 0.5.2 | 0.2.5 | [Neue Funktion] Die Chatglm/Qwen -Serie unterstützt Funktionsaufrufe und fügt die International -Serie hinzu. [Kleine Optimierung] Vereinfachen Sie den Ruf der Chat -Demo in Pipeline, generieren Token -Element dürfen eine Liste sein, den Parameternamen von Rope_Scaling entfernen und Seilklassen hinzufügen. [Bug] Fix Flash_attn2 Inferenzfehler und BARTs Tie_word_embedding -Fehler beheben |
Weitere Versionen
Mehr Geschichte
Vorausgebildete Modelle unterstützen mehrere Code-Lademethoden
from bert4torch . models import build_transformer_model
# 1. 仅指定config_path: 从头初始化模型结构, 不加载预训练模型
model = build_transformer_model ( './model/bert4torch_config.json' )
# 2. 仅指定checkpoint_path:
## 2.1 文件夹路径: 自动寻找路径下的*.bin/*.safetensors权重文件 + 需把bert4torch_config.json下载并放于该目录下
model = build_transformer_model ( checkpoint_path = './model' )
## 2.2 文件路径/列表: 文件路径即权重路径/列表, bert4torch_config.json会从同级目录下寻找
model = build_transformer_model ( checkpoint_path = './pytorch_model.bin' )
## 2.3 model_name: hf上预训练权重名称, 会自动下载hf权重以及bert4torch_config.json文件
model = build_transformer_model ( checkpoint_path = 'bert-base-chinese' )
# 3. 同时指定config_path和checkpoint_path(本地路径名或model_name排列组合):
# 本地路径从本地加载,pretrained_model_name会联网下载
config_path = './model/bert4torch_config.json' # 或'bert-base-chinese'
checkpoint_path = './model/pytorch_model.bin' # 或'bert-base-chinese'
model = build_transformer_model ( config_path , checkpoint_path )Voraber Gewichtsverknüpfung und Bert4Torch_config.json
| Modellklassifizierung | Modellname | Gewichtsquelle | Gewichtsverknüpfung/Checkpoint_Path | config_path |
|---|---|---|---|---|
| Bert | Bert-Base-Chinese | Google-Bert | bert-base-chinese | bert-base-chinese |
| Chinese_L-12_H-768_A-12 | TF GewichtTongjilibo/bert-chinese_L-12_H-768_A-12 | |||
| Chinese-Bert-Wwm-EXT | Hfl | hfl/chinese-bert-wwm-ext | hfl/chinese-bert-wwm-ext | |
| Bert-Base-Multivietuell-Cased | Google-Bert | bert-base-multilingual-cased | bert-base-multilingual-cased | |
| Macbert | Hfl | hfl/chinese-macbert-basehfl/chinese-macbert-large | hfl/chinese-macbert-basehfl/chinese-macbert-large | |
| Wobert | Zhuyi -Technologie | junnyu/wobert_chinese_base , junnyu/wobert_chinese_plus_base | junnyu/wobert_chinese_basejunnyu/wobert_chinese_plus_base | |
| Roberta | Chinese-Roberta-Wwm-Outd | Hfl | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large(Großes MLM -Gewicht von großem MLM wird zufällig initialisiert) | hfl/chinese-roberta-wwm-exthfl/chinese-roberta-wwm-ext-large |
| Roberta-Small/Tiny | Zhuyi -Technologie | Tongjilibo/chinese_roberta_L-4_H-312_A-12Tongjilibo/chinese_roberta_L-6_H-384_A-12 | ||
| Roberta-Base | Facebookai | roberta-base | roberta-base | |
| Guwenbert | Ethanyt | ethanyt/guwenbert-base | ethanyt/guwenbert-base | |
| Albert | Albert_Zh Albert_pytorch | Brightmart | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge | voidful/albert_chinese_tinyvoidful/albert_chinese_smallvoidful/albert_chinese_basevoidful/albert_chinese_largevoidful/albert_chinese_xlargevoidful/albert_chinese_xxlarge |
| Nezha | Nezha Nezha_chinese_pytorch | huawei_noah | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm | sijunhe/nezha-cn-basesijunhe/nezha-cn-largesijunhe/nezha-base-wwmsijunhe/nezha-large-wwm |
| nezha_gpt_dialog | Bojone | Tongjilibo/nezha_gpt_dialog | ||
| xlnet | Chinese-XLNET | Hfl | hfl/chinese-xlnet-base | hfl/chinese-xlnet-base |
| Transformator_xl | Umarmung | transfo-xl/transfo-xl-wt103 | transfo-xl/transfo-xl-wt103 | |
| Deberta | Erlangshen-Deberta-V2 | IDEE | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese | IDEA-CCNL/Erlangshen-DeBERTa-v2-97M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-320M-ChineseIDEA-CCNL/Erlangshen-DeBERTa-v2-710M-Chinese |
| Elektra | Chinesisch-Elektra | Hfl | hfl/chinese-electra-base-discriminator | hfl/chinese-electra-base-discriminator |
| Ernie | Ernie | Baidu Wenxin | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh | nghuyong/ernie-1.0-base-zhnghuyong/ernie-3.0-base-zh |
| roformer | roformer | Zhuyi -Technologie | junnyu/roformer_chinese_base | junnyu/roformer_chinese_base |
| roformer_v2 | Zhuyi -Technologie | junnyu/roformer_v2_chinese_char_base | junnyu/roformer_v2_chinese_char_base | |
| Simbert | Simbert | Zhuyi -Technologie | Tongjilibo/simbert-chinese-baseTongjilibo/simbert-chinese-smallTongjilibo/simbert-chinese-tiny | |
| SIMBERT_V2/ROFORMER-SIM | Zhuyi -Technologie | junnyu/roformer_chinese_sim_char_base , junnyu/roformer_chinese_sim_char_ft_base , junnyu/roformer_chinese_sim_char_small , junnyu/roformer_chinese_sim_char_ft_small | junnyu/roformer_chinese_sim_char_basejunnyu/roformer_chinese_sim_char_ft_basejunnyu/roformer_chinese_sim_char_smalljunnyu/roformer_chinese_sim_char_ft_small | |
| Gau | Gau-Alpha | Zhuyi -Technologie | Tongjilibo/chinese_GAU-alpha-char_L-24_H-768 | |
| Uie | Uie uie_pytorch | Baidu | Tongjilibo/uie-base | |
| gpt | CDIAL-GPT | Thu-Coai | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large | thu-coai/CDial-GPT_LCCC-basethu-coai/CDial-GPT_LCCC-large |
| CMP_LM (2,6 Milliarden) | Tsinghua | TsinghuaAI/CPM-Generate | TsinghuaAI/CPM-Generate | |
| nezha_gen | huawei_noah | Tongjilibo/chinese_nezha_gpt_L-12_H-768_A-12 | ||
| GPT2-Chinese-Cluecorpussmall | Uer | uer/gpt2-chinese-cluecorpussmall | uer/gpt2-chinese-cluecorpussmall | |
| gpt2-ml | Imcaspar | Torrh Baiduyun (84dh) | gpt2-ml_15g_corpusgpt2-ml_30g_corpus | |
| Bart | Bart_Base_chinese | Fudan fnlp | fnlp/bart-base-chinesev1.0 | fnlp/bart-base-chinesefnlp/bart-base-chinese-v1.0 |
| T5 | T5 | Uer | uer/t5-small-chinese-cluecorpussmalluer/t5-base-chinese-cluecorpussmall | uer/t5-base-chinese-cluecorpussmalluer/t5-small-chinese-cluecorpussmall |
| MT5 | google/mt5-base | google/mt5-base | ||
| t5_pegasus | Zhuyi -Technologie | Tongjilibo/chinese_t5_pegasus_smallTongjilibo/chinese_t5_pegasus_base | ||
| Chatyuan | Hinweis | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | ClueAI/ChatYuan-large-v1ClueAI/ChatYuan-large-v2 | |
| Promptclue | Hinweis | ClueAI/PromptCLUE-base | ClueAI/PromptCLUE-base | |
| Chatglm | Chatglm-6b | Dürftig | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4v0.1.0 | THUDM/chatglm-6bTHUDM/chatglm-6b-int8THUDM/chatglm-6b-int4THUDM/chatglm-6b-v0.1.0 |
| Chatglm2-6b | Dürftig | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | THUDM/chatglm2-6bTHUDM/chatglm2-6b-int4THUDM/chatglm2-6b-32k | |
| Chatglm3-6b | Dürftig | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | THUDM/chatglm3-6bTHUDM/chatglm3-6b-32k | |
| GLM4-9B | Dürftig | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | THUDM/glm-4-9bTHUDM/glm-4-9b-chatTHUDM/glm-4-9b-chat-1m | |
| Lama | Lama | Meta | meta-llama/llama-7bmeta-llama/llama-13b | |
| LAMA-2 | Meta | meta-llama/lama-2-7b-hf meta-llama/lama-2-7b-chat-hf meta-llama/lama-2-13b-hf meta-llama/lama-2-13b-chat-hf | meta-llama/Llama-2-7b-hfmeta-llama/Llama-2-7b-chat-hfmeta-llama/Llama-2-13b-hfmeta-llama/Llama-2-13b-chat-hf | |
| Lama-3 | Meta | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | meta-llama/Meta-Llama-3-8Bmeta-llama/Meta-Llama-3-8B-Instruct | |
| Lama-3.1 | Meta | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | meta-llama/Meta-Llama-3.1-8Bmeta-llama/Meta-Llama-3.1-8B-Instruct | |
| Lama-3.2 | Meta | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | meta-llama/Llama-3.2-1Bmeta-llama/Llama-3.2-1B-Instructmeta-llama/Llama-3.2-3Bmeta-llama/Llama-3.2-3B-Instruct | |
| Chinesisch-Llama-Alpaka | Hfl | hfl/chinese_alpaca_plus_7bhfl/chinese_llama_plus_7b | ||
| Chinesisch-Llama-Alpaka-2 | Hfl | Hinzugefügt werden | ||
| Chinesisch-Llama-Alpaca-3 | Hfl | Hinzugefügt werden | ||
| Belle_llama | Lianjiatech | Bellegroup/Belle-Llama-7b-2m -c | Syntheseanweisungen, BelleGroup/BELLE-LLaMA-7B-2M-enc | |
| Ziya | Idee-ccnl | Idee-ccnl/ziya-llama-13b-v1 Idee-ccnl/ziya-llama-13b-v1.1 Idee-ccnl/ziya-llama-13b-farm-v1 | IDEA-CCNL/Ziya-LLaMA-13B-v1IDEA-CCNL/Ziya-LLaMA-13B-v1.1 | |
| Vicuna | LMSYS | lmsys/vicuna-7b-v1.5 | lmsys/vicuna-7b-v1.5 | |
| Baichuan | Baichuan | Baichuan-Inc | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat | baichuan-inc/Baichuan-7Bbaichuan-inc/Baichuan-13B-Basebaichuan-inc/Baichuan-13B-Chat |
| Baichuan2 | Baichuan-Inc | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | baichuan-inc/Baichuan2-7B-Basebaichuan-inc/Baichuan2-7B-Chatbaichuan-inc/Baichuan2-13B-Basebaichuan-inc/Baichuan2-13B-Chat | |
| Yi | Yi | 01-ai | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K | 01-ai/Yi-6B01-ai/Yi-6B-200K01-ai/Yi-9B01-ai/Yi-9B-200K |
| Yi-1.5 | 01-ai | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | 01-ai/Yi-1.5-6B01-ai/Yi-1.5-6B-Chat01-ai/Yi-1.5-9B01-ai/Yi-1.5-9B-32K01-ai/Yi-1.5-9B-Chat01-ai/Yi-1.5-9B-Chat-16K | |
| blühen | blühen | BigScience | bigscience/bloom-560mbigscience/bloomz-560m | bigscience/bloom-560mbigscience/bloomz-560m |
| Qwen | Qwen | Alibaba Cloud | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat | Qwen/Qwen-1_8BQwen/Qwen-1_8B-ChatQwen/Qwen-7BQwen/Qwen-7B-ChatQwen/Qwen-14BQwen/Qwen-14B-Chat |
| Qwen1.5 | Alibaba Cloud | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | Qwen/Qwen1.5-0.5BQwen/Qwen1.5-0.5B-ChatQwen/Qwen1.5-1.8BQwen/Qwen1.5-1.8B-ChatQwen/Qwen1.5-7BQwen/Qwen1.5-7B-ChatQwen/Qwen1.5-14BQwen/Qwen1.5-14B-Chat | |
| Qwen2 | Alibaba Cloud | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | Qwen/Qwen2-0.5BQwen/Qwen2-0.5B-InstructQwen/Qwen2-1.5BQwen/Qwen2-1.5B-InstructQwen/Qwen2-7BQwen/Qwen2-7B-Instruct | |
| Qwen2-vl | Alibaba Cloud | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | Qwen/Qwen2-VL-2B-InstructQwen/Qwen2-VL-7B-Instruct | |
| Qwen2.5 | Alibaba Cloud | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | Qwen/Qwen2.5-0.5BQwen/Qwen2.5-0.5B-InstructQwen/Qwen2.5-1.5BQwen/Qwen2.5-1.5B-InstructQwen/Qwen2.5-3BQwen/Qwen2.5-3B-InstructQwen/Qwen2.5-7BQwen/Qwen2.5-7B-InstructQwen/Qwen2.5-14BQwen/Qwen2.5-14B-Instruct | |
| Internlm | Internlm | Shanghai künstliches Intelligenzlabor | internlm/internlm-7binternlm/internlm-chat-7b | internlm/internlm-7binternlm/internlm-chat-7b |
| Internlm2 | Shanghai künstliches Intelligenzlabor | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7binternlm/internlm2-20binternlm/internlm2-chat-20b | internlm/internlm2-1_8binternlm/internlm2-chat-1_8binternlm/internlm2-7binternlm/internlm2-chat-7b | |
| Internlm2.5 | Shanghai künstliches Intelligenzlabor | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | internlm/internlm2_5-7binternlm/internlm2_5-7b-chatinternlm/internlm2_5-7b-chat-1m | |
| Falke | Falke | tiiuae | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct | tiiuae/falcon-rw-1btiiuae/falcon-7btiiuae/falcon-7b-instruct |
| Deepseek | Deepseek-Moe | Eingehende Suche | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat | deepseek-ai/deepseek-moe-16b-basedeepseek-ai/deepseek-moe-16b-chat |
| Deepseek-llm | Eingehende Suche | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | deepseek-ai/deepseek-llm-7b-basedeepseek-ai/deepseek-llm-7b-chat | |
| Deepseek-V2 | Eingehende Suche | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | deepseek-ai/DeepSeek-V2-Litedeepseek-ai/DeepSeek-V2-Lite-Chat | |
| Deepseek-Coder | Eingehende Suche | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | deepseek-ai/deepseek-coder-1.3b-basedeepseek-ai/deepseek-coder-1.3b-instructdeepseek-ai/deepseek-coder-6.7b-basedeepseek-ai/deepseek-coder-6.7b-instructdeepseek-ai/deepseek-coder-7b-base-v1.5deepseek-ai/deepseek-coder-7b-instruct-v1.5 | |
| Deepseek-Coder-V2 | Eingehende Suche | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | deepseek-ai/DeepSeek-Coder-V2-Lite-Basedeepseek-ai/DeepSeek-Coder-V2-Lite-Instruct | |
| Deepseek-Math | Eingehende Suche | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | deepseek-ai/deepseek-math-7b-basedeepseek-ai/deepseek-math-7b-instructdeepseek-ai/deepseek-math-7b-rl | |
| Minicpm | Minicpm | OpenBMB | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 | openbmb/MiniCPM-2B-sft-bf16openbmb/MiniCPM-2B-dpo-bf16openbmb/MiniCPM-2B-128kopenbmb/MiniCPM-1B-sft-bf16 |
| Minicpm-V | OpenBMB | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | openbmb/MiniCPM-V-2_6openbmb/MiniCPM-Llama3-V-2_5 | |
| Einbettung | Text2VEC-Base-Chinese | Shibing624 | shibing624/text2vec-base-chinese | shibing624/text2vec-base-chinese |
| M3E | Moka-ai | moka-ai/m3e-base | moka-ai/m3e-base | |
| bge | Baai | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | BAAI/bge-large-en-v1.5BAAI/bge-large-zh-v1.5BAAI/bge-base-en-v1.5BAAI/bge-base-zh-v1.5BAAI/bge-small-en-v1.5BAAI/bge-small-zh-v1.5 | |
| gte | Thenlper | thenlper/gte-large-zhthenlper/gte-base-zh | thenlper/gte-base-zhthenlper/gte-large-zh |
*Notiz:
高亮格式(z. B. bert-base-chinese ) kann direkt build_transformer_model() werden.HF_ENDPOINT=https://hf-mirror.com python your_script.pyexport HF_ENDPOINT=https://hf-mirror.com bevor Sie den Python-Code ausführen import os
os . environ [ 'HF_ENDPOINT' ] = "https://hf-mirror.com" @misc{bert4torch,
title={bert4torch},
author={Bo Li},
year={2022},
howpublished={url{https://github.com/Tongjilibo/bert4torch}},
}
 Wechat ID |  Wechat -Gruppe | Star History Chart |


