soul manga
1.0.0
Um site de quadrinhos de aplicativo de uma página construído usando o Reactjs + Python/Flask + Sqlite + Scrapy também usa as ferramentas de gerenciamento e implantação do Gunicorn e Python da Fabric. Foi usado quando eu mesmo construí a implantação automática.
Node.js pré -condição, python3
npm install
pip install -r requirements.txt
cd server python web_server.py
npm start
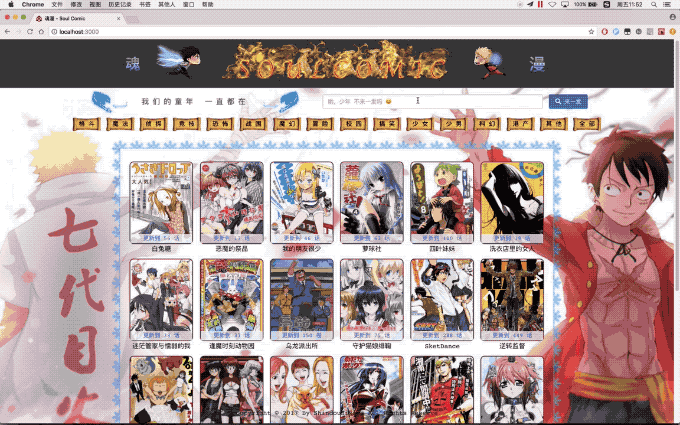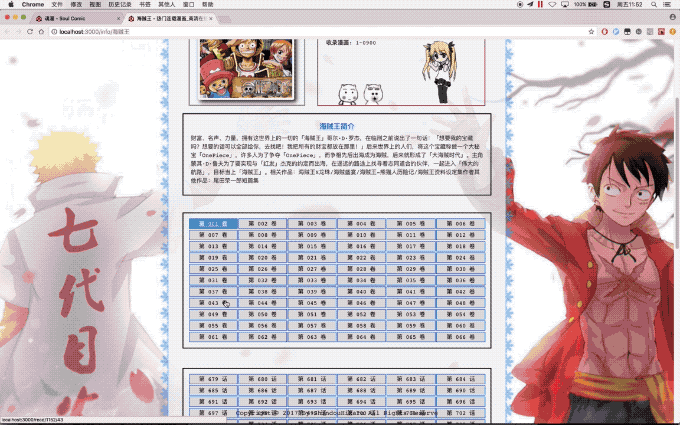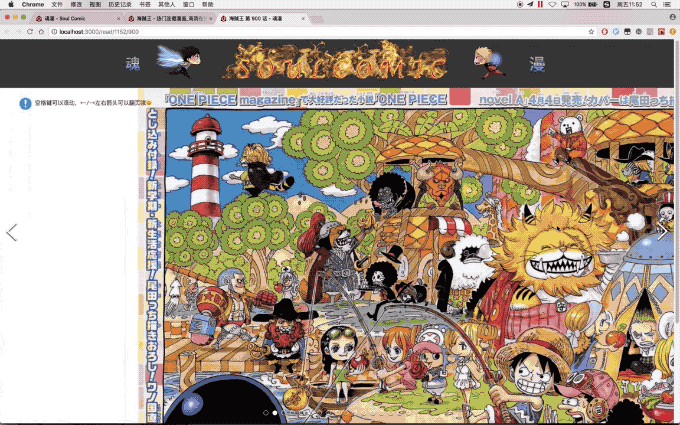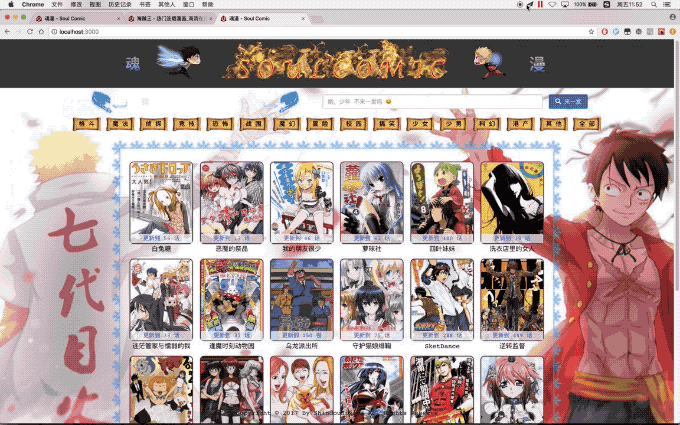
Visite localhost:3000 sobre ...
soul_manga_spider.py define três maneiras de rastejar. REQ_TYPE corresponde a diferentes tipos de URL: quadrinhos únicos, todos os quadrinhos em uma única página e todos os quadrinhos. Há também um parâmetro is_update para indicar se apenas o URL da página atualizado recentemente está rastreado e, em seguida, faça atualizações incrementais. Quando eu mesmo implantei, basicamente era suficiente usar crontab para rastejar uma vez a cada 12 horas. O padrão is_update é falso, e REQ_TYPE é padrão para não fazer nada, e o padrão é usar o banco de dados que eu rastei. O nível de log ajusta LOG_LEVEL e LOG_FILE de setting.py de acordo com suas necessidades


