soul manga
1.0.0
แอปพลิเคชันหน้าเดียวเว็บไซต์การ์ตูนที่สร้างขึ้นโดยใช้ ReactJS + Python/Flask + SQLite + Scrapy ยังใช้ Gunicorn และ Python Management และเครื่องมือการปรับใช้ มันถูกใช้เมื่อฉันสร้างการปรับใช้อัตโนมัติด้วยตัวเอง
precondition node.js, python3
npm install
pip install -r requirements.txt
cd server python web_server.py
npm start
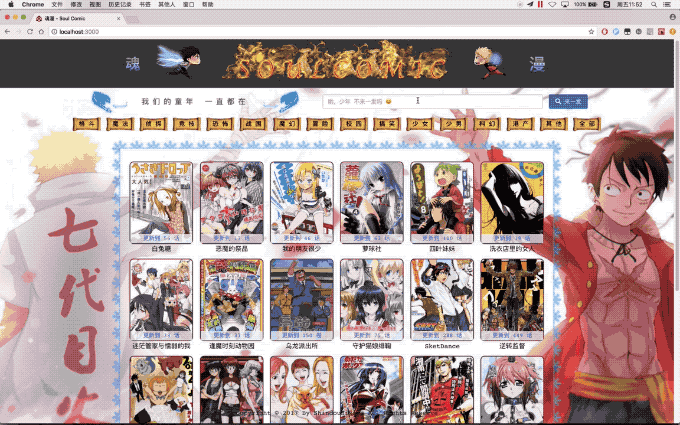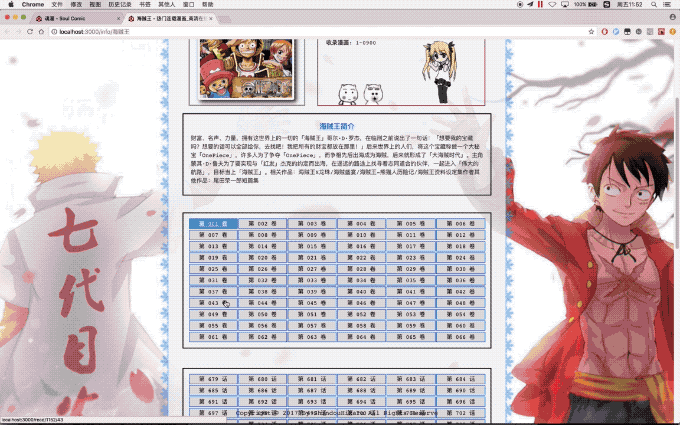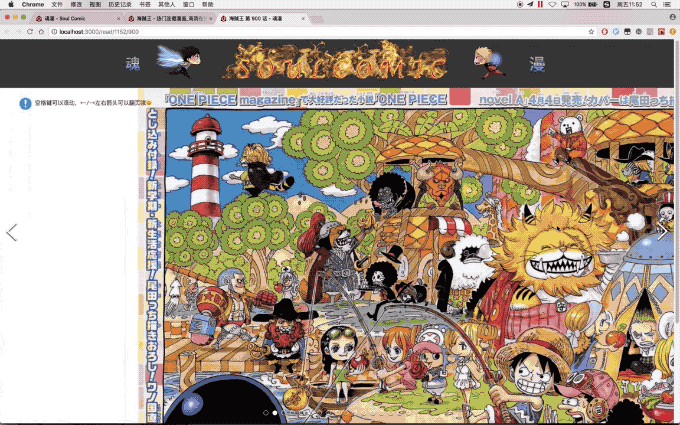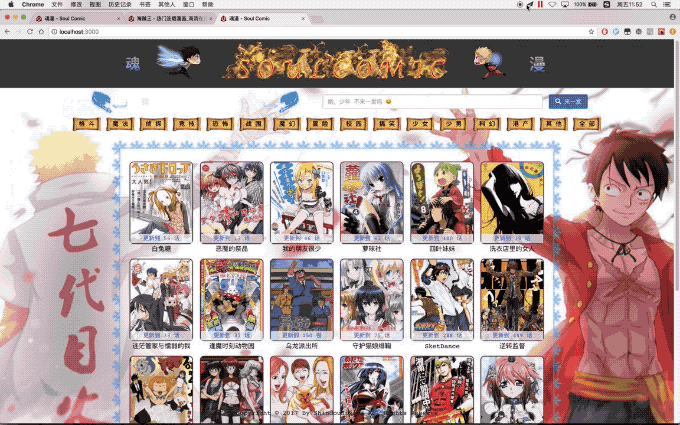
เยี่ยมชม localhost:3000 มากกว่า ...
soul_manga_spider.py กำหนดสามวิธีในการรวบรวมข้อมูล REQ_TYPE สอดคล้องกับประเภท URL ที่แตกต่างกัน: การ์ตูนเดี่ยวการ์ตูนทั้งหมดในหน้าเดียวและการ์ตูนทั้งหมด นอกจากนี้ยังมีพารามิเตอร์ is_update เพื่อระบุว่า URL หน้าอัปเดตล่าสุดเท่านั้นที่ถูกรวบรวมข้อมูลและทำการอัปเดตที่เพิ่มขึ้น เมื่อฉันนำไปใช้เองมันก็เพียงพอที่จะใช้ crontab เพื่อรวบรวมข้อมูลทุก ๆ 12 ชั่วโมง is_update เริ่มต้นเป็นเท็จและ REQ_TYPE เป็นค่าเริ่มต้นที่จะไม่ทำอะไรเลยและค่าเริ่มต้นคือการใช้ DB ที่ฉันได้รวบรวมไว้ ระดับบันทึกปรับ LOG_LEVEL และ LOG_FILE ของ setting.py ตามความต้องการของคุณ


