soul manga
1.0.0
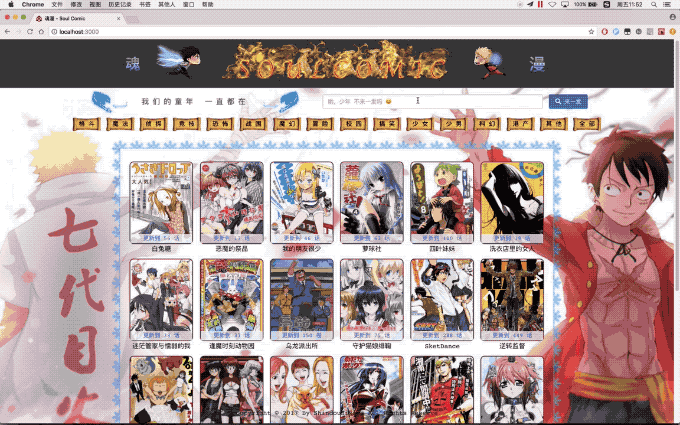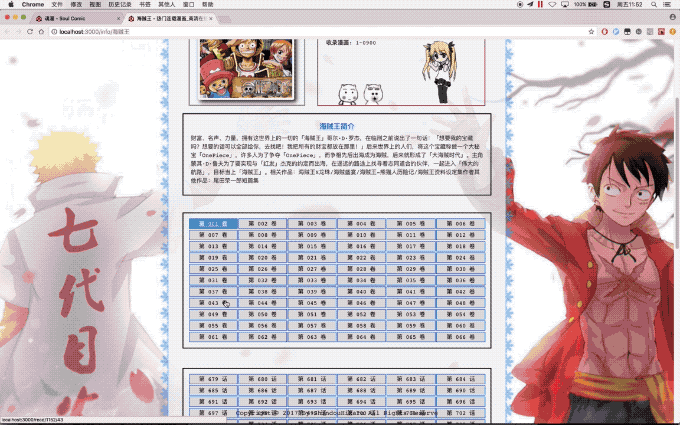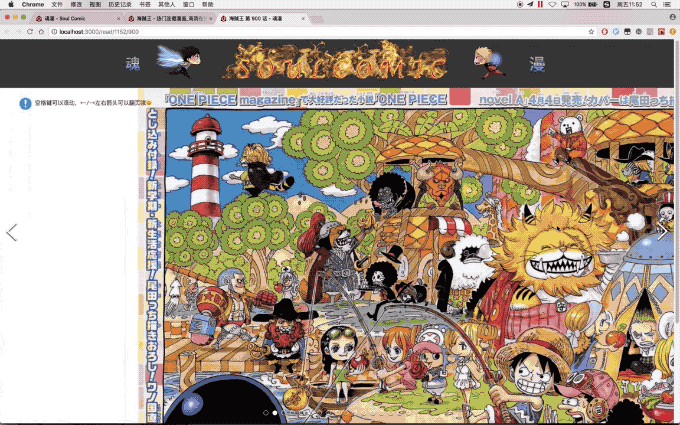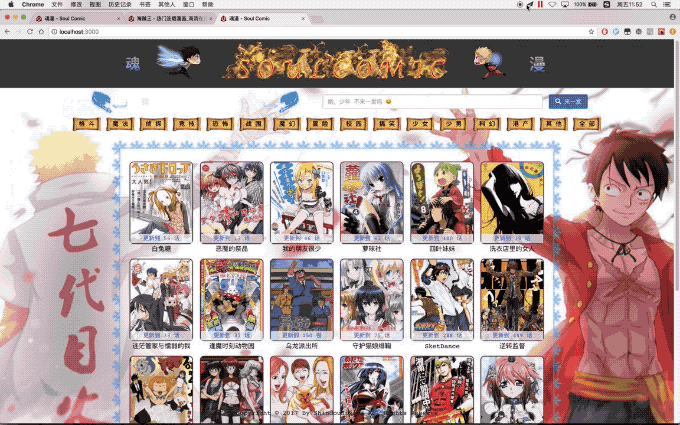
Un sitio cómico de aplicación de una sola página creada con ReactJS + Python/Flask + SQLite + Scrapy también utiliza herramientas de gestión y implementación de Python de Gunicorn y Fabric. Se usó cuando construí la implementación automática yo mismo.
Precondición Node.js, Python3
npm install
pip install -r requirements.txt
cd server python web_server.py
npm start
Visite localhost:3000 sobre ...
soul_manga_spider.py define tres formas de rastreo. REQ_TYPE corresponde a diferentes tipos de URL: cómics individuales, todos los cómics en una sola página y todos los cómics. También hay un parámetro is_update para indicar si solo la URL de la página recientemente actualizada está rastreada y luego realiza actualizaciones incrementales. Cuando lo desplegé yo mismo, fue básicamente suficiente usar crontab para gatear una vez cada 12 horas. El is_update predeterminado es falso, y REQ_TYPE es predeterminado no hacer nada, y el valor predeterminado es usar el DB que he rastreo. El nivel de registro ajusta LOG_LEVEL y LOG_FILE de setting.py de acuerdo con sus necesidades


