dryad
1.0.0
Pesquisa de código semântico fácil em qualquer repositório do GitHub em ~ 1000 sloc.
Confira a demonstração em execução
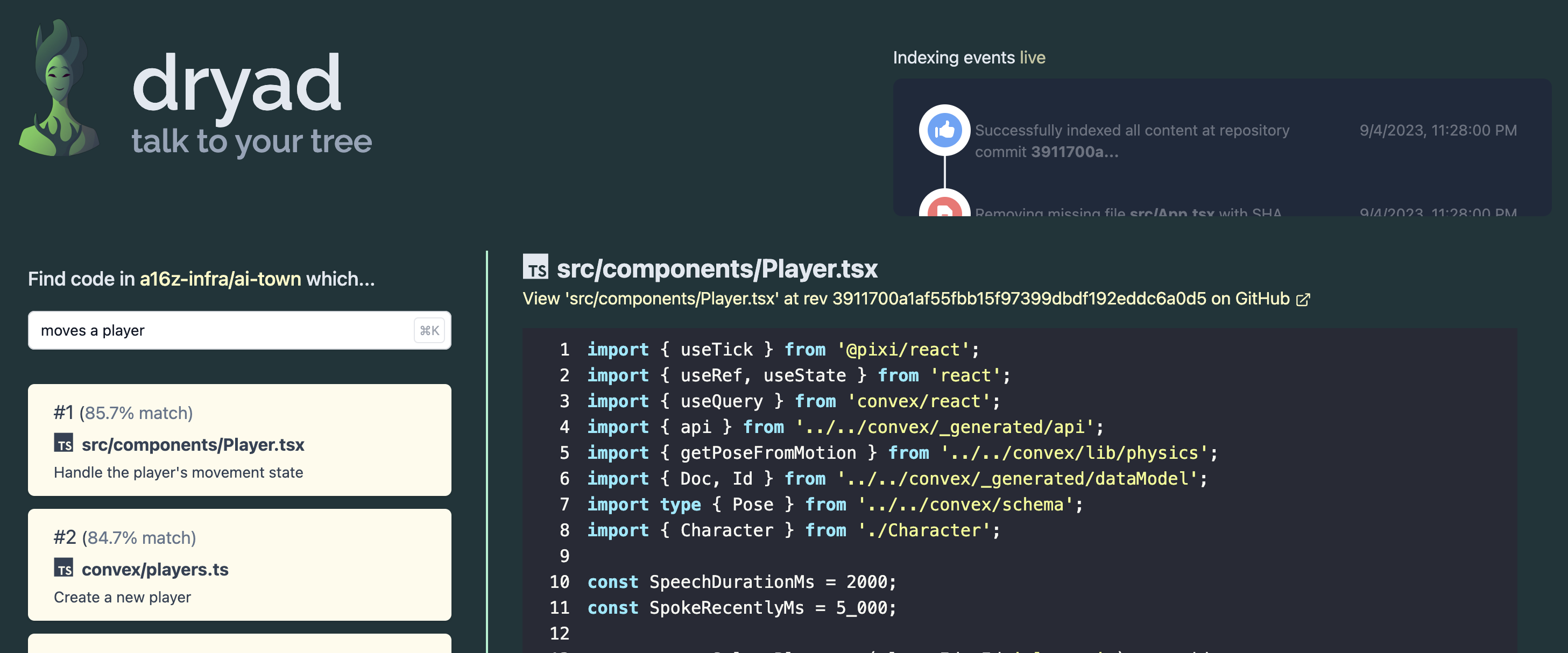
A Dryad pretende ser um projeto de demonstração útil e um modelo de partida para criar aplicativos da Web de pesquisa semântica mais sofisticados.
Características:
HEADPrimeiro, clone o repositório e comece:
$ git clone https://github.com/get-convex/dryad.git
$ npm i
$ npm run dev
Isso criará sua implantação convexa de back-end, que tentará começar a indexar o repositório padrão (https://github.com/get-convex/convex-helpers). Em seguida, o front -end começará, executando na porta usual 5173 da Vite.
Em outro terminal neste mesmo repositório, inicie o painel convexo e assista aos logs a seguir junto com a indexação de back -end:
$ npx convex dashboard
No painel Logs , você verá erros sobre variáveis de ambiente ausentes. Temos um pouco mais de configuração para fazer!
O Dryad usa o OpenAI para resumo e incorporação. Você precisará de uma conta da plataforma OpenAI e uma chave da API. Visite Platform.openai.com para cuidar disso.
️ Resumir e indexar até uma base de código moderada consome uma quantidade razoável de créditos do OpenAI. Você quase certamente precisará de uma conta paga!
Os usos anônimos da API do GitHub são limitados com muita facilidade. Portanto, a Dryad exige que você gere um token de acesso pessoal usando sua conta do GitHub. Visite https://github.com/settings/tokens para gerar um token para o Dryad.
Com sua chave de API do OpenAI e Token de acesso ao Github na mão, volte para o painel do seu implantação convexo. No painel de navegação esquerda, clique em "Configurações" e, em seguida, "variáveis de ambiente".
Nomeie as duas variáveis de ambiente secreto OPENAI_API_KEY e GITHUB_ACCESS_TOKEN , assim:
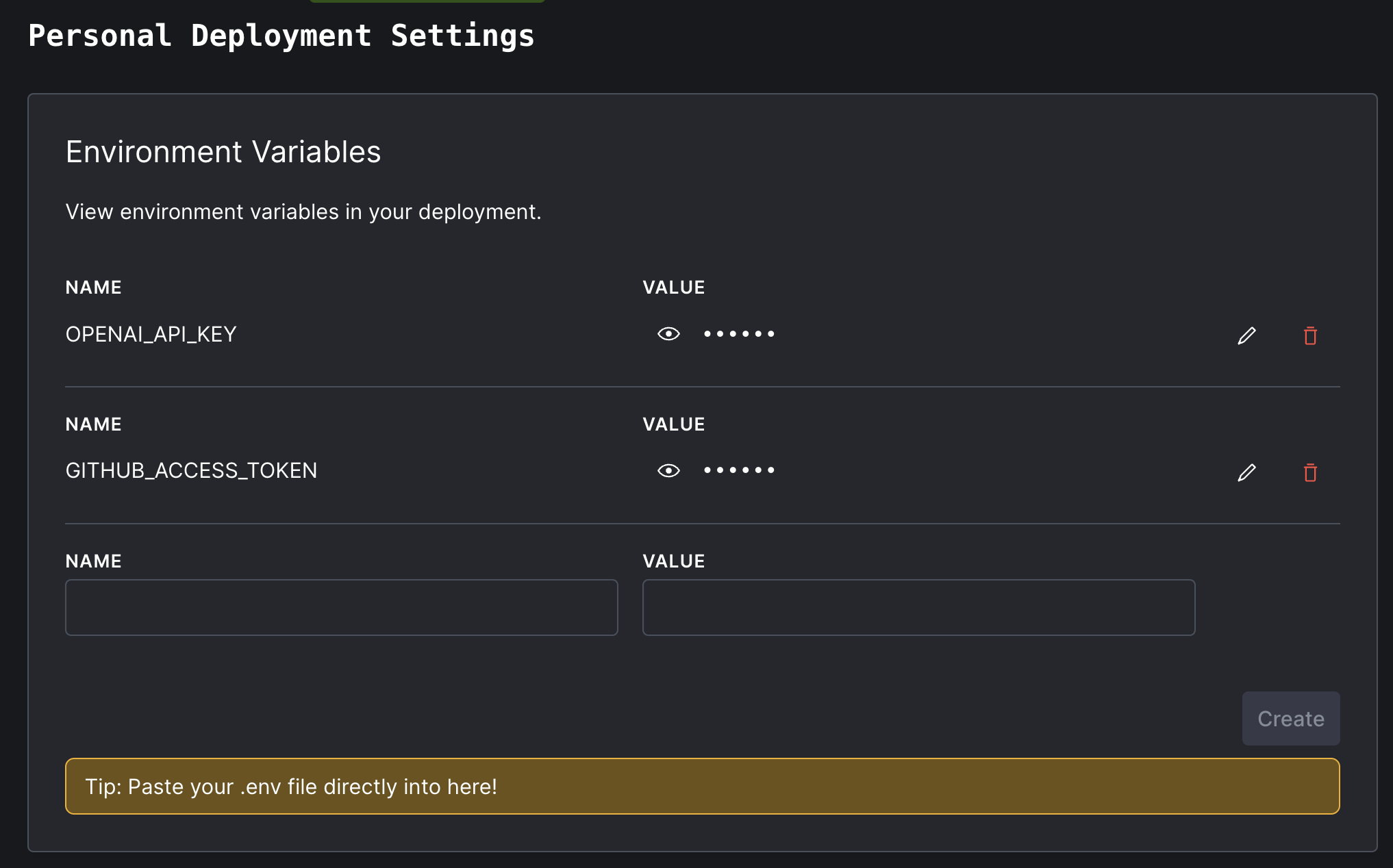
settings Se você verificar a exibição Logs no seu painel convexo, o Dryad agora deve estar funcionando com sucesso! Mas está indexando o repositório padrão, get-convex/convex-helpers . Você provavelmente deseja indexar seu próprio código.
Boas notícias! É fácil personalizar o comportamento da Dryad. O Dryad mantém toda a sua configuração em uma tabela settings no próprio banco de dados convexo. Clique na visualização Data no painel e escolha a tabela settings :
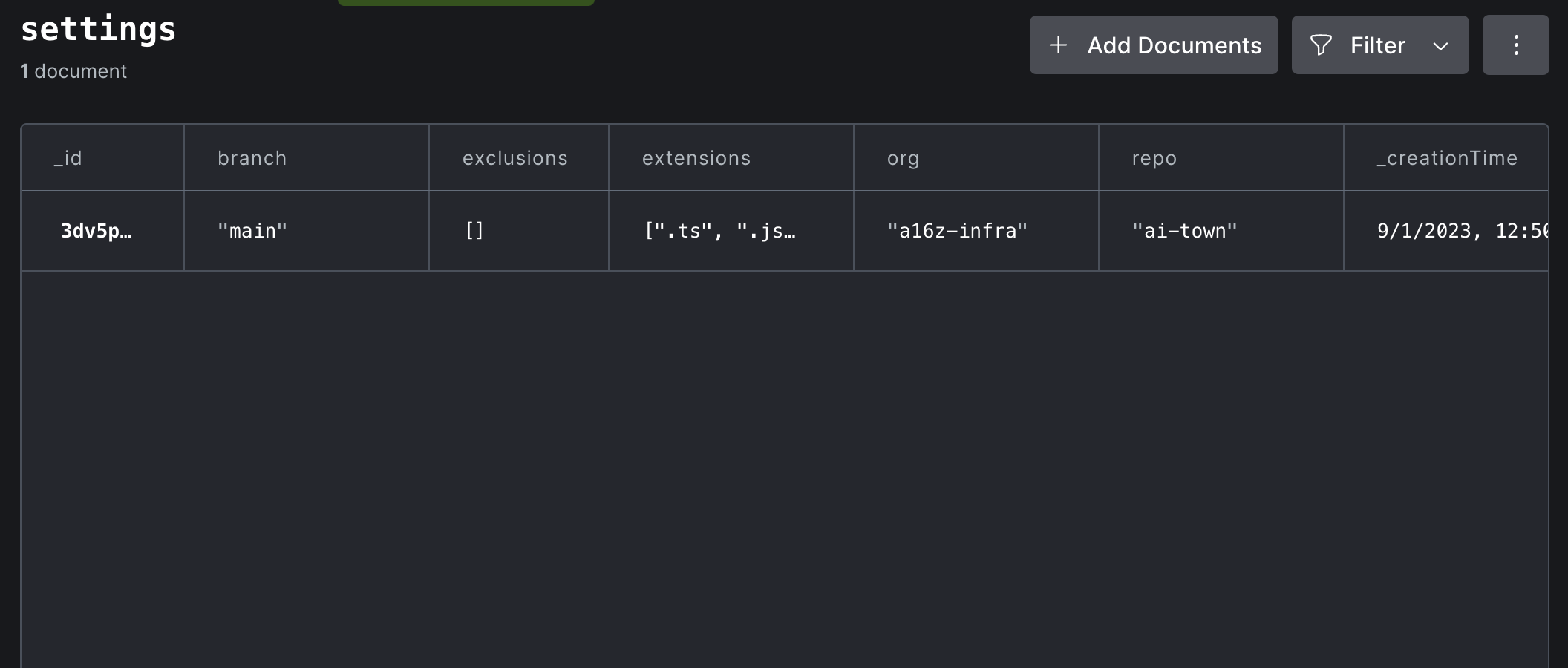
Clique duas vezes em qualquer valor no documento Configurações para editá -lo ou clique no botão Azul "Editar" para adicionar campos ausentes ao documento. Normalmente, você não precisa fazer nada por suas alterações para entrar em vigor. Mas se você deseja reindex de qualquer maneira, clique no corredor de funções Fn no painel inferior direito do painel e, em seguida, opte por executar syncState:reset a partir do menu suspenso. Nenhum argumento é necessário.
O esquema desta tabela pode ser encontrado em convex/schema.ts neste repositório. Aqui está o que parece:
// Various project settings you can tweak in the dashboard as we go.
settings : defineTable ( {
org : v . string ( ) ,
repo : v . string ( ) ,
branch : v . string ( ) ,
extensions : v . array ( v . string ( ) ) ,
exclusions : v . optional ( v . array ( v . string ( ) ) ) , // defaults to no exclusions
byteLimit : v . optional ( v . number ( ) ) , // defaults to 24,000 bytes
chatModel : v . optional ( v . string ( ) ) , // defaults to gpt-4
} ) ,facebook .react .gpt-3.5-turbo , gpt-4 .Três coisas principais para cobrir:
A cada minuto, a Dryad chama um trabalho chamado repo:sync . Esta é uma ação convexa que usa uma tabela chamada syncState para fazer um loop entre dois estados:
Enquanto pesquisou uma nova confirmação, o Dryad usa a API do GitHub (via Oclaro) para verificar o SHA da ramificação de repo + de destino. Enquanto o valor que volta do Github permanecer o mesmo que o último sha indexado no syncState.commit , repo:sync sai até a próxima pesquisa.
Mas quando uma nova confirmação é descoberta, o campo syncState.commit está definido como definido como o novo SHA, e o campo commitDone está definido como falso. Isso coloca o Dechad no modo "Indexação que cometem".
Ao indexar um compromisso, repo:sync primeiro usa a API do GitHub "Trees" para buscar toda a árvore de arquivos dessa confirmação, incluindo as somas de verificação de arquivo associadas a cada arquivo.
A Dryad então caminha por toda essa árvore, procurando arquivos de código -fonte (de acordo com a especificação de extensão da tabela 'Configurações' '). Para cada arquivo de origem, ele determina se a soma de verificação mudou desde a última vez que o arquivo foi indexado. Se o arquivo for novo ou foi alterado, ele será baixado do repo e reiniciado.
Caso contrário, o arquivo está marcado como atual - ainda válido em nova confirmação.
Finalmente, depois que todos os arquivos na árvore são indexados adequadamente, todos os arquivos que não fazem mais parte desta nova árvore de compromisso são removidos do índice.
E com isso, commitDone está definido como True e a Dryad remonta à pesquisa para uma nova confirmação.
A indexação de arquivos de origem envolve três etapas:
fileGoals da Convex, com uma referência ao registro do arquivo de origem pai nos files . O campo vetorial do objetivo está usando a indexação vetorial da Convex para oferecer suporte à pesquisa rápida no aplicativo da web. Quando alguém envia uma consulta no aplicativo da web, o Dryad usa a mesma API de incorporação do OpenAI para gerar um vetor e, em seguida, usa o índice vetorial do Convex para encontrar arquivos de origem com uma meta semanticamente similar no termo de pesquisa.
A pesquisa retorna apenas cada arquivo de origem uma vez, retornando a meta mais bem classificada como o principal motivo da inclusão desse arquivo no conjunto de resultados.
Dryad é bastante básico neste momento! Existem muitas direções em que você pode levar o projeto.
Os problemas do projeto foram semeados com uma coleção de extensões em potencial e melhorias no DRYAD para fazer com que as rodas giram coisas mais sofisticadas que poderiam ser construídas a partir do dríade.
Feliz hacking!
Junte -se à nossa discórdia para falar sobre o Dryad.
O Convex é uma plataforma de back-end hospedada com um banco de dados embutido que permite escrever seu esquema de banco de dados e funções do servidor no TypeScript. As consultas de banco de dados do lado do servidor cache e assinam automaticamente os dados, alimentando um gancho useQuery em tempo real em nosso cliente React. Existem também clientes para Python, Rust, Reactnative e Node, bem como uma API HTTP direta.
O banco de dados suporta documentos no estilo NoSQL com relacionamentos e índices personalizados (inclusive em campos em objetos aninhados).
As funções do servidor de query e mutation têm acesso transacional e de baixa latência ao banco de dados e alavancam nosso tempo de execução v8 com o determinismo guardra corrimão para fornecer as garantem as mais fortes garantias de ácido no mercado: consistência imediata, isolamento serializável e resolução automática de conflitos por meio de controle de concorrência multi-versão otimista (OCC / OCC / MVC).
As funções do servidor action têm acesso a APIs externas e permitem outros efeitos colaterais e não determinismo em nosso tempo de execução otimizado v8 ou em um tempo de execução node mais flexível.
As funções podem ser executadas em segundo plano por meio de trabalhos de programação e Cron.
O desenvolvimento é o primeiro lugar, com recarregamento a quente para edição de funções de servidor via CLI. Há uma interface do usuário do painel para navegar e editar dados, editar variáveis de ambiente, visualizar logs, executar funções do servidor e muito mais.
Existem recursos internos para paginação reativa, armazenamento de arquivos, pesquisa reativa, terminais HTTPS (para webhooks), streaming de importação/exportação e validação de dados de tempo de execução para argumentos de função e dados do banco de dados.
Tudo escala automaticamente e é gratuito para começar.


