dryad
1.0.0
Recherche de code sémantique facile sur n'importe quel référentiel GitHub dans ~ 1000 sloc.
Découvrez la démo en cours d'exécution
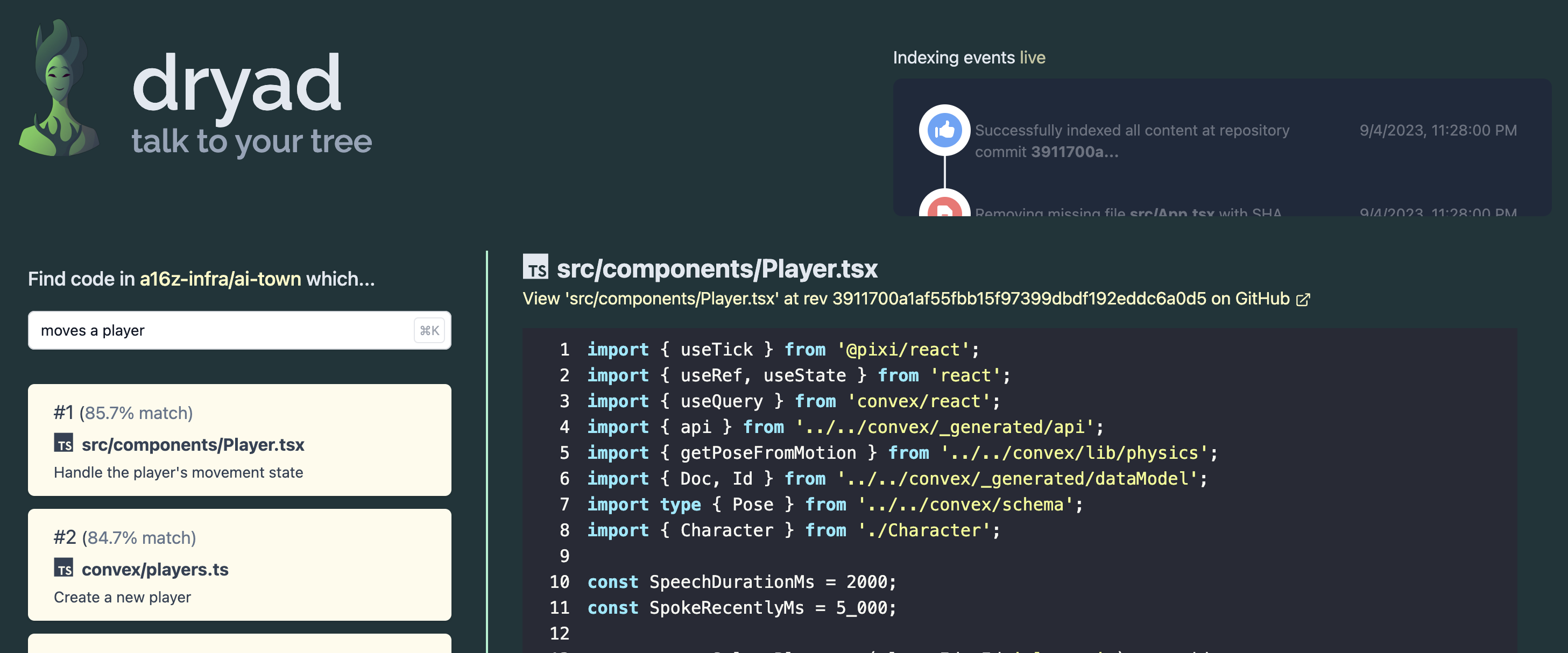
Dryad est destiné à être un modèle de démonstration et un modèle de démarrage utiles pour créer des applications Web de recherche sémantique plus sophistiquées.
Caractéristiques:
HEADTout d'abord, clonez le référentiel et démarrez-le:
$ git clone https://github.com/get-convex/dryad.git
$ npm i
$ npm run dev
Cela créera votre déploiement backend convexe, qui tentera de commencer à indexer le référentiel par défaut (https://github.com/get-convex/convex-helpers). Ensuite, le frontend démarre, fonctionnant sur le port habituel de Vite 5173.
Dans un autre terminal de ce même référentiel, lancez le tableau de bord convexe et regardez les journaux à suivre avec l'indexation du backend:
$ npx convex dashboard
Dans le panneau Logs , vous verrez des erreurs sur les variables d'environnement manquantes. Nous avons un peu plus de configuration à faire!
Dryad utilise OpenAI pour le résumé et l'incorporation. Vous aurez besoin d'un compte de plate-forme Openai et d'une clé API. Visitez la plate-forme.openai.com pour s'occuper de cela.
️ Le résumé et l'indexation même une base de code modérée consomme une bonne quantité de crédits OpenAI. Vous aurez presque certainement besoin d'un compte payant!
Les utilisations anonymes de l'API GitHub sont limitées très facilement. Dryad exige donc que vous générez un jeton d'accès personnel à l'aide de votre compte GitHub. Visitez https://github.com/settings/tokens pour générer un jeton pour Dryad.
Avec votre touche API OpenAI et votre jeton d'accès GitHub à la main, revenez au tableau de bord de votre déploiement convexe. Dans le panneau de navigation de gauche, cliquez sur "Paramètres", puis "Variables d'environnement".
Nommez les deux variables d'environnement secret OPENAI_API_KEY et GITHUB_ACCESS_TOKEN , comme ainsi:
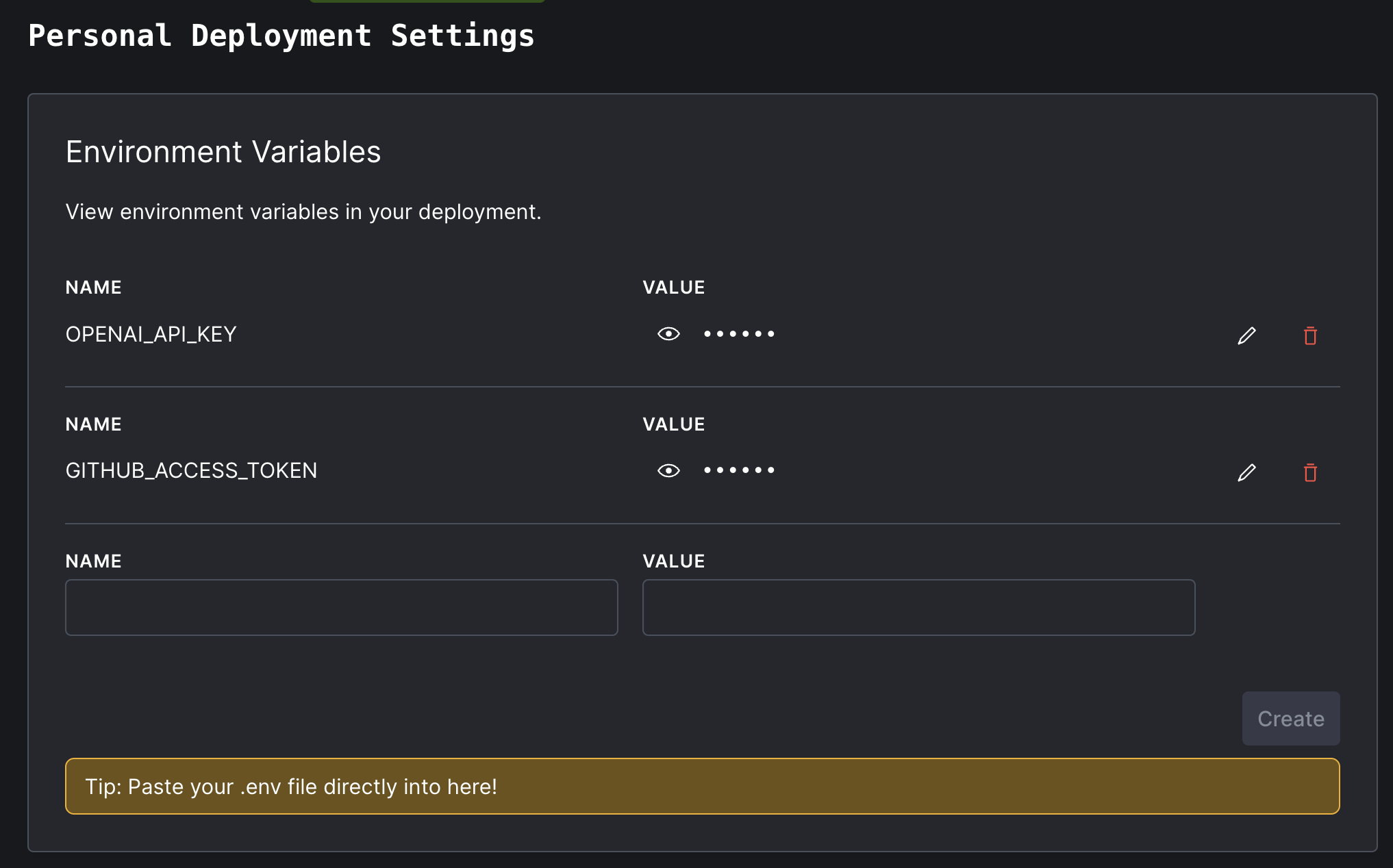
settings Si vous vérifiez la vue Logs dans votre tableau de bord convexe, Dryad devrait maintenant fonctionner avec succès! Mais il indexte le référentiel par défaut, get-convex/convex-helpers . Vous voulez probablement que cela indexent votre propre code à la place.
Bonnes nouvelles! Il est facile de personnaliser le comportement de Dryad. DryAD conserve toute sa configuration dans un tableau settings de votre base de données convexe elle-même. Cliquez sur la vue Data dans le tableau de bord, puis choisissez le tableau settings :
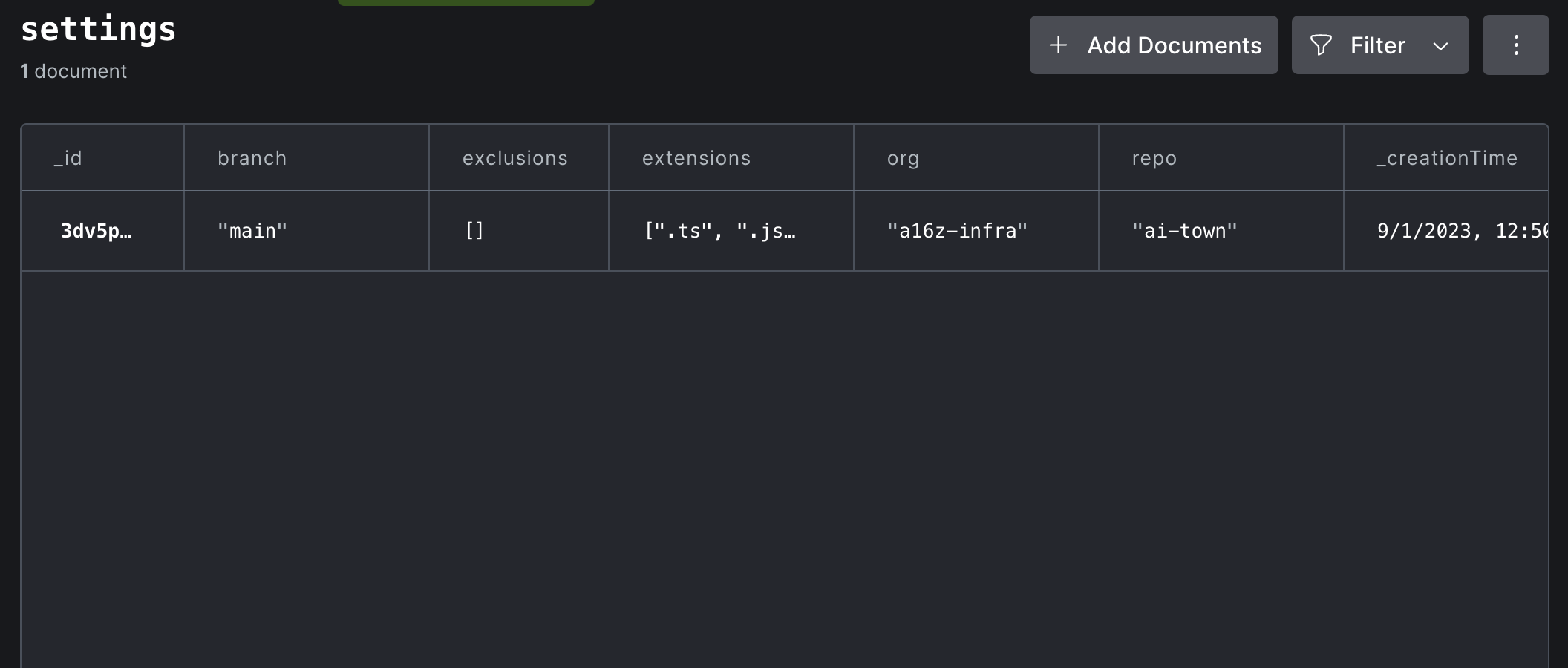
Double-cliquez sur n'importe quelle valeur dans le document Paramètres pour le modifier, ou cliquez sur le bouton "Modifier" pour ajouter des champs manquants au document. Normalement, vous ne devriez rien faire pour que vos modifications prennent effet. Mais si vous souhaitez réindexer de toute façon, cliquez sur le coureur de fonction Fn dans le panneau inférieur droit du tableau de bord, puis choisissez d'exécuter syncState:reset à partir de la liste déroulante. Aucun argument n'est requis.
Le schéma de ce tableau se trouve dans convex/schema.ts dans ce référentiel. Voici à quoi ça ressemble:
// Various project settings you can tweak in the dashboard as we go.
settings : defineTable ( {
org : v . string ( ) ,
repo : v . string ( ) ,
branch : v . string ( ) ,
extensions : v . array ( v . string ( ) ) ,
exclusions : v . optional ( v . array ( v . string ( ) ) ) , // defaults to no exclusions
byteLimit : v . optional ( v . number ( ) ) , // defaults to 24,000 bytes
chatModel : v . optional ( v . string ( ) ) , // defaults to gpt-4
} ) ,facebook .react .gpt-3.5-turbo , gpt-4 .Trois choses principales à couvrir:
Chaque minute, Dryad appelle un emploi nommé repo:sync . Il s'agit d'une action convexe qui utilise un tableau appelé syncState pour boucler entre deux états:
Lors du sondage pour un nouvel engagement, Dryad utilise l'API GitHub (via Octokit) pour vérifier le SHA de la branche Target Repo +. Tant que la valeur revenant de GitHub reste la même que le dernier SHA indexé dans syncState.commit , repo:sync sort jusqu'au prochain sondage.
Mais lorsqu'un nouvel commit est découvert, le champ syncState.commit est défini sur le nouveau SHA, et le champ commitDone est défini sur False. Cela met Dryad dans le mode "indexation de ce validation".
Lors de l'indexation d'un engagement, repo:sync utilise d'abord l'API GitHub "Trees" pour récupérer l'ensemble de l'arborescence de fichiers de cet engagement, y compris les sommes de contrôle de fichiers associées à chaque fichier.
Dryad marche ensuite sur tout cet arbre, à la recherche de fichiers de code source (selon la spécification d'extension du tableau `` Paramètres ''). Pour chaque fichier source, il détermine si la somme de contrôle a changé depuis la dernière fois que le fichier a été indexé. Si le fichier est nouveau ou a changé, il est téléchargé à partir du dépôt et réindexé.
Sinon, le fichier est marqué actuel - toujours valide dans un nouvel engagement.
Enfin, une fois que tous les fichiers de l'arborescence sont correctement indexés, tous les fichiers qui ne font plus partie de cette nouvelle arborescence de validation sont supprimés de l'index.
Et avec cela, commitDone est réglé sur True et Dryad revient au sondage pour un nouvel commit.
Indexation des fichiers source implique trois étapes:
fileGoals de convex, avec une référence à l'enregistrement du fichier source parent dans files . Le champ vectoriel de l'objectif est d'utiliser l'indexation des vecteurs de Convex pour prendre en charge la recherche rapide à partir de l'application Web. Lorsque quelqu'un soumet une requête dans l'application Web, Dryad utilise la même API OpenAI Embeddings pour générer un vecteur, puis utilise l'index vectoriel de Convex pour trouver des fichiers source avec un objectif sémantiquement similaire au terme de recherche.
La recherche ne renvoie que chaque fichier source une fois, renvoyant l'objectif le mieux classé comme raison principale de l'inclusion de ce fichier dans l'ensemble de résultats.
Dryad est assez basique à ce stade! Il y a beaucoup de directions dans lesquelles vous pourriez prendre le projet.
Les problèmes du projet ont été ensemencés avec une collection d'extensions potentielles et d'améliorations à Dryad pour que les roues tournent sur des choses plus sophistiquées qui pourraient être construites à partir de Dryad.
Joyeux piratage!
Rejoignez notre discorde pour parler de Dryad.
Convex est une plate-forme backend hébergée avec une base de données intégrée qui vous permet d'écrire votre schéma de base de données et les fonctions de serveur dans TypeScript. Les requêtes de base de données côté serveur se cachent et s'abonnent automatiquement aux données, alimentant un crochet useQuery en temps réel dans notre client React. Il existe également des clients pour Python, Rust, Reactnative et Node, ainsi qu'une API HTTP simple.
La base de données prend en charge les documents de style NoSQL avec les relations et les index personnalisés (y compris sur les champs dans les objets imbriqués).
Les fonctions de serveur query et mutation ont un accès transactionnel et à faible latence à la base de données et tirent parti de notre runtime v8 avec des garde-corps de déterminisme pour fournir les garanties d'acide les plus fortes sur le marché: cohérence immédiate, isolement sérialisable et résolution des conflits automatiques via le contrôle optimiste de la multicolyme (OCC / MVCC).
Les fonctions du serveur action ont accès aux API externes et activent d'autres effets secondaires et non-déterminisme dans notre runtime v8 optimisé ou un runtime node plus flexible.
Les fonctions peuvent s'exécuter en arrière-plan via des travaux de planification et de cron.
Le développement est d'abord en nuage, avec des recharges chaudes pour l'édition de fonctions de serveur via la CLI. Il existe une interface utilisateur de tableau de bord pour parcourir et modifier les données, modifier les variables d'environnement, afficher les journaux, exécuter les fonctions du serveur, etc.
Il existe des fonctionnalités intégrées pour la pagination réactive, le stockage de fichiers, la recherche réactive, les points de terminaison HTTPS (pour WebHooks), le streaming d'importation / exportation et la validation des données d'exécution pour les arguments de fonction et les données de base de données.
Tout évolue automatiquement et il est libre de commencer.


