dryad
1.0.0
Búsqueda de código semántico fácil en cualquier repositorio de GitHub en ~ 1000 SLOC.
Mira la demostración de ejecución
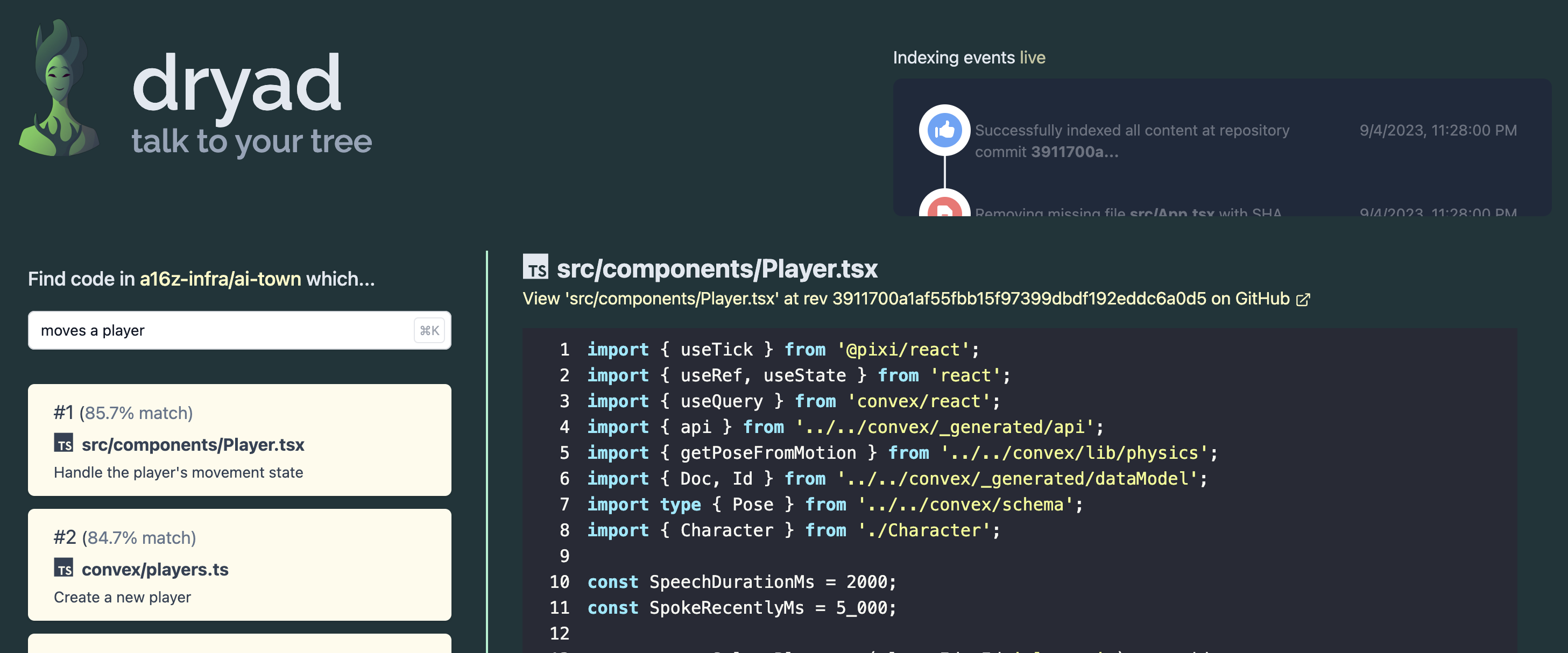
Dryad está destinado a ser un proyecto de demostración útil y una plantilla de inicio para construir aplicaciones web de búsqueda semántica más sofisticadas.
Características:
HEADPrimero, clona el repositorio y comience:
$ git clone https://github.com/get-convex/dryad.git
$ npm i
$ npm run dev
Esto creará su implementación de backend convexa, que intentará comenzar a indexar el repositorio predeterminado (https://github.com/get-convex/convex-helpers). Luego, el frontend se iniciará, ejecutándose en el puerto habitual 5173 de Vite.
En otro terminal en este mismo repositorio, inicie el tablero convexo y vea los registros para seguir junto con la indexación de backend:
$ npx convex dashboard
En el panel Logs , verá errores sobre las variables de entorno faltantes. ¡Tenemos un poco más configurado para hacer!
Dryad usa OpenAI para resumir e incrustarse. Necesitará una cuenta de plataforma Operai y una clave API. Visite plataforma.openai.com para encargarse de eso.
️ Resumir e indexar incluso una base de código moderada consume una buena cantidad de créditos de Operai. You will almost certainly need a paid account!
Los usos anónimos de la API de GitHub obtienen una velocidad limitada muy fácilmente. Por lo tanto, Dryad requiere que genere un token de acceso personal con su cuenta GitHub. Visite https://github.com/settings/tokens para generar un token para Dryad.
Con su tecla API de OpenAI y el token de acceso GitHub en la mano, regrese al tablero de su implementación convexa. En el panel de navegación izquierdo, haga clic en "Configuración" y luego "Variables de entorno".
Nombra las dos variables de entorno secreto OPENAI_API_KEY y GITHUB_ACCESS_TOKEN , como así:
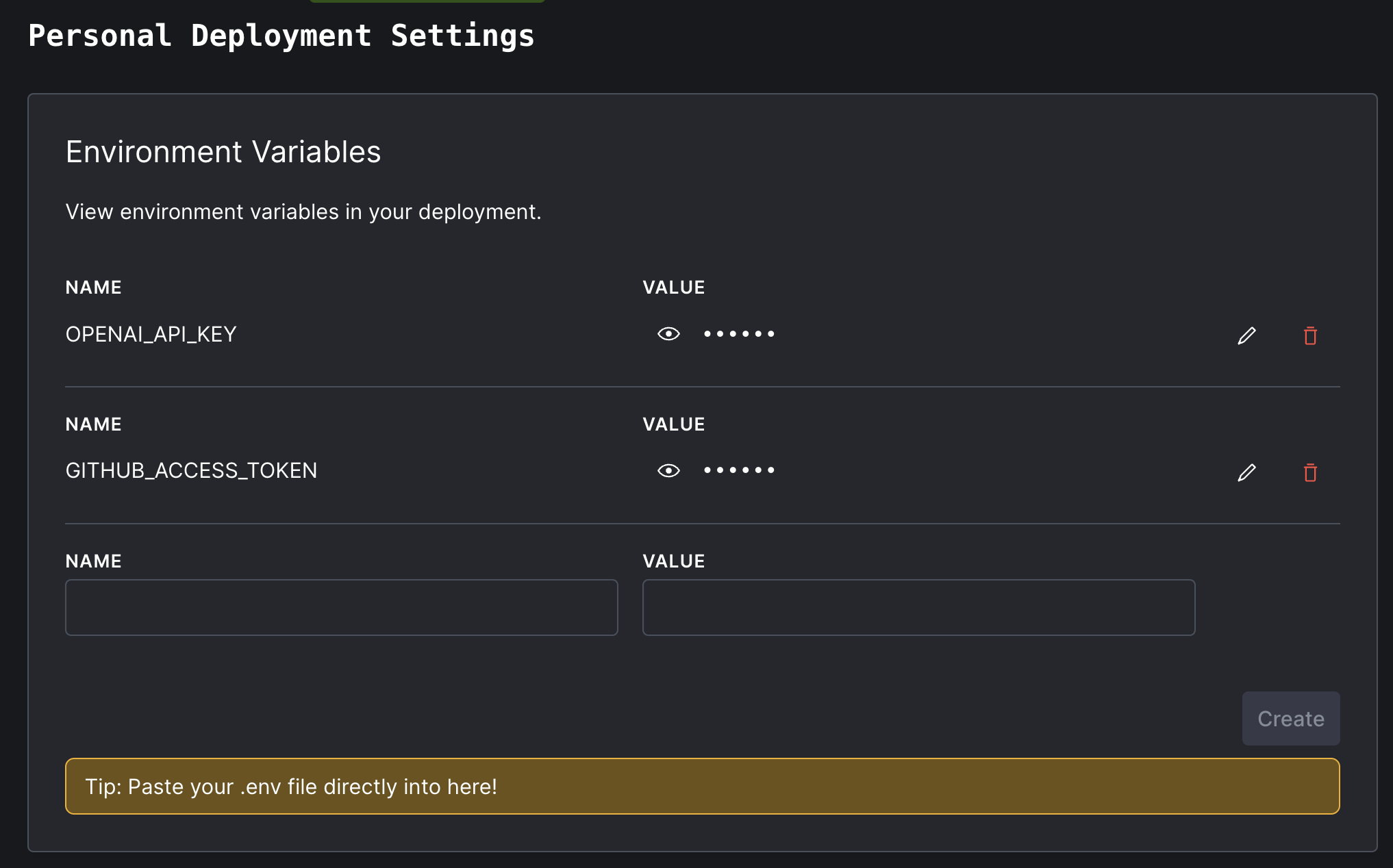
settings Si verifica la vista Logs en su tablero convexo, ¡Dryad ahora debería funcionar con éxito! Pero está indexando el repositorio predeterminado, get-convex/convex-helpers . Probablemente desee que indexe su propio código.
¡Albricias! Es fácil personalizar el comportamiento de Dryad. Dryad mantiene toda su configuración en una tabla settings en su base de datos convexa. Haga clic en la vista Data en el tablero y luego elija la tabla settings :
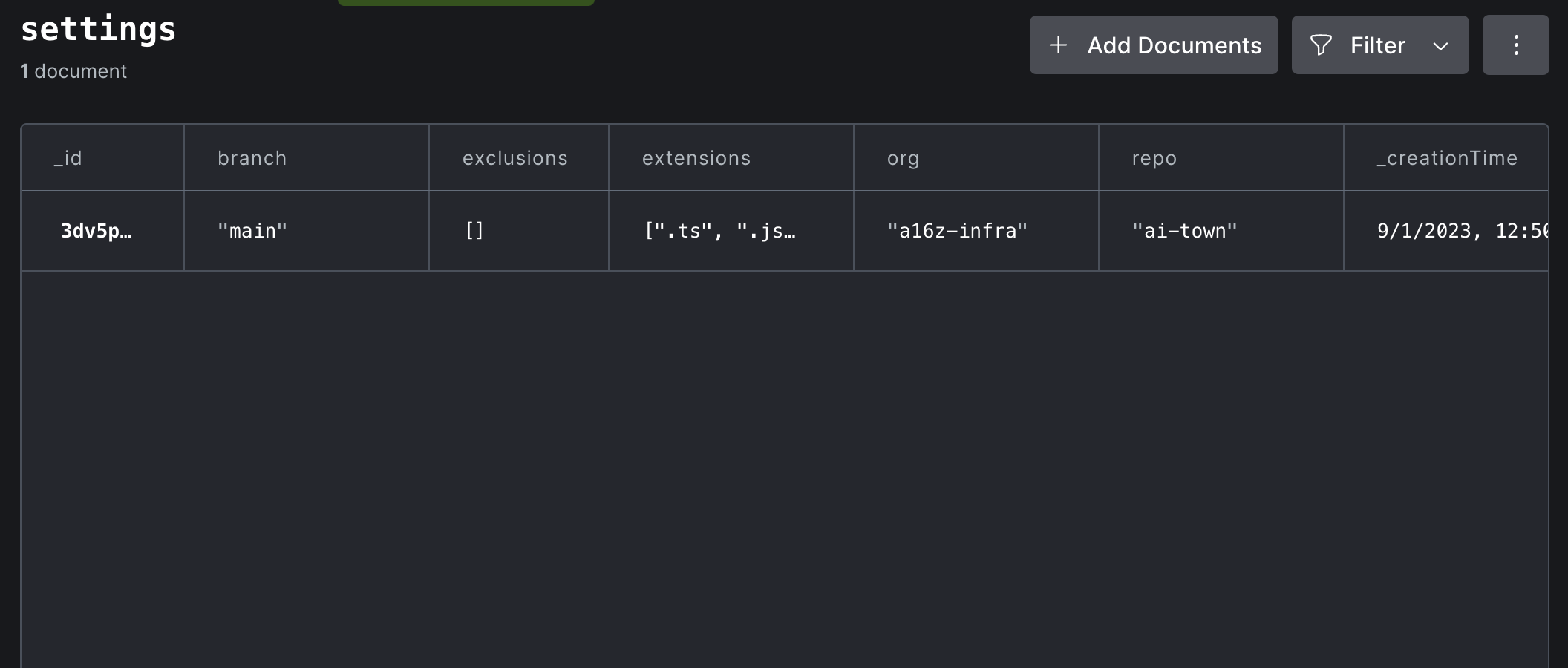
Haga doble clic en cualquier valor en el documento de configuración para editarlo, o haga clic en el botón Azul "Editar" para agregar campos faltantes al documento. Normalmente, no debería necesitar hacer nada para que sus cambios entren en vigencia. Pero si desea reindex de todos modos, haga clic en el corredor de la función Fn en el panel inferior derecho del tablero, y luego elija ejecutar syncState:reset desde el menú desplegable. No se requieren argumentos.
El esquema de esta tabla se puede encontrar en convex/schema.ts en este repositorio. Así es como se ve:
// Various project settings you can tweak in the dashboard as we go.
settings : defineTable ( {
org : v . string ( ) ,
repo : v . string ( ) ,
branch : v . string ( ) ,
extensions : v . array ( v . string ( ) ) ,
exclusions : v . optional ( v . array ( v . string ( ) ) ) , // defaults to no exclusions
byteLimit : v . optional ( v . number ( ) ) , // defaults to 24,000 bytes
chatModel : v . optional ( v . string ( ) ) , // defaults to gpt-4
} ) ,facebook .react .gpt-3.5-turbo , gpt-4 .Tres cosas principales para cubrir:
Cada minuto, Dryad llama a un trabajo llamado repo:sync . Esta es una acción convexa que utiliza una tabla llamada syncState para recorrer entre dos estados:
Mientras se encuesta para una nueva confirmación, Dryad usa la API de GitHub (a través de OctoKit) para verificar el SHA de la rama de Repo + objetivo. Mientras el valor que regrese de GitHub sigue siendo el mismo que el último repo:sync indexado en syncState.commit .
Pero cuando se descubre una nueva confirmación, el campo syncState.commit se establece en el nuevo SHA, y el campo commitDone se establece en falso. Esto pone a Dryad en el modo "indexación que confirme".
Al indexar una confirmación, repo:sync usa primero la API "Trees" GitHub para obtener todo el árbol de archivos de esa confirmación, incluidas las suma de verificación de archivos asociadas con cada archivo.
Dryad luego camina todo este árbol, buscando archivos de código fuente (de acuerdo con la especificación de extensión de la tabla 'Configuración' '). Para cada archivo fuente, determina si la suma de verificación ha cambiado desde la última vez que se indexó el archivo. Si el archivo es nuevo o ha cambiado, se descarga del repositorio y se vuelve a indicar.
De lo contrario, el archivo es marcado de corriente, todavía válida en un nuevo confirmación.
Finalmente, después de que todos los archivos en el árbol se indexan correctamente, cualquier archivo que ya no se separe de este nuevo árbol de confirmación se elimine del índice.
Y con eso, commitDone está configurado en True y Dryad se remonta a las encuestas para una nueva compromiso.
La indexación de los archivos fuente implica tres pasos:
fileGoals de Convex, con una referencia al registro de archivo de origen principal en files . El campo vectorial del objetivo es utilizar la indexación vectorial de Convex para admitir la búsqueda rápida desde la aplicación web. Cuando alguien envía una consulta en la aplicación web, Dryad usa la misma API de incrustaciones de OpenAI para generar un vector, y luego usa el índice de vectores de Convex para encontrar archivos fuente con un objetivo semánticamente similar al término de búsqueda.
La búsqueda solo devuelve cada archivo de origen una vez, devolviendo el objetivo mejor clasificado como la razón principal de la inclusión de ese archivo en el conjunto de resultados.
¡Dryad es bastante básico en este momento! Hay muchas direcciones en las que podría tomar el proyecto.
Los problemas del proyecto se han sembrado con una colección de posibles extensiones y mejoras en Dryad para que las ruedas se vuelvan más sofisticadas que podrían construirse a partir de Dryad.
¡Feliz piratería!
Únase a nuestra discordia para hablar sobre Dryad.
Convex es una plataforma de backend alojada con una base de datos incorporada que le permite escribir el esquema de su base de datos y las funciones del servidor en TypeScript. Las consultas de la base de datos del lado del servidor almacenan automáticamente en caché y suscriben datos, alimentando un gancho useQuery en tiempo real en nuestro cliente React. También hay clientes para Python, Rust, Reactnative y Node, así como una API HTTP directa.
La base de datos admite documentos de estilo NoSQL con relaciones e índices personalizados (incluso en campos en objetos anidados).
Las funciones query y servidor mutation tienen acceso transaccional y de baja latencia a la base de datos y aprovechan nuestro tiempo de ejecución v8 con barandas de determinismo para proporcionar las garantías ácidas más fuertes en el mercado: consistencia inmediata, aislamiento en serie y resolución de conflictos automáticos a través de un control de concurrencia múltiple optimista (OCC / MVCC).
Las funciones del servidor action tienen acceso a API externas y habilitan otros efectos secundarios y no determinismo en nuestro tiempo de ejecución v8 optimizado o en un tiempo de ejecución node más flexible.
Las funciones pueden ejecutarse en segundo plano a través de los trabajos de programación y cron.
El desarrollo es en la nube primero, con recargas en caliente para la edición de funciones del servidor a través de la CLI. Hay una interfaz de usuario del tablero para navegar y editar datos, editar variables de entorno, ver registros, ejecutar funciones del servidor y más.
Existen características incorporadas para paginación reactiva, almacenamiento de archivos, búsqueda reactiva, puntos finales HTTPS (para webhooks), transmisión de importación/exportación y validación de datos de tiempo de ejecución para argumentos de funciones y datos de bases de datos.
Todo escala automáticamente y es gratuito para comenzar.


