dryad
1.0.0
〜1000スロックのgithubリポジトリでの簡単なセマンティックコード検索。
実行中のデモをご覧ください
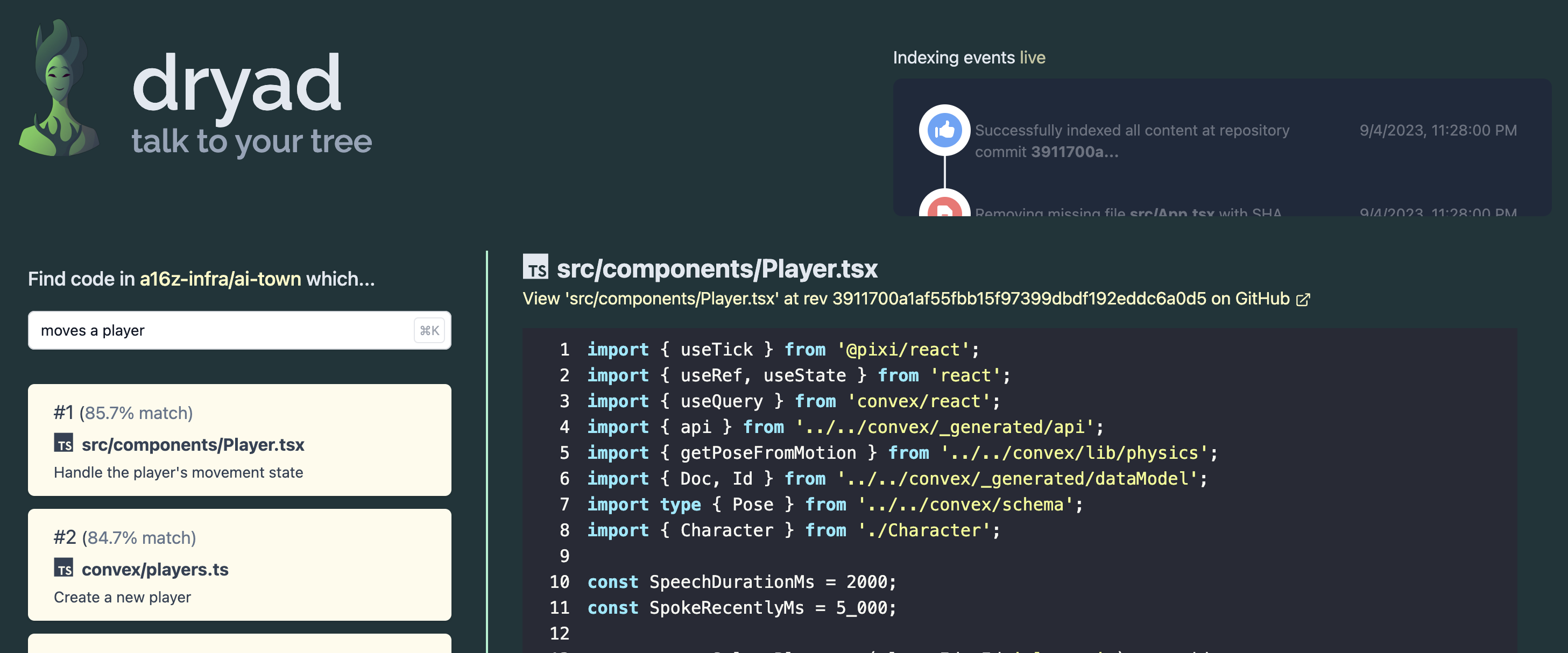
Dryadは、より洗練されたセマンティック検索Webアプリを構築するための便利なデモプロジェクトおよびスターターテンプレートになることを目的としています。
特徴:
HEADと同期させます最初に、リポジトリをクローンして起動します。
$ git clone https://github.com/get-convex/dryad.git
$ npm i
$ npm run dev
これにより、凸型のバックエンド展開が作成され、デフォルトのリポジトリ(https://github.com/getconvex/convex-helpers)のインデックス付けを開始しようとします。その後、フロントエンドが起動し、Viteの通常のポート5173で実行されます。
この同じリポジトリの別の端末で、凸面ダッシュボードを起動し、バックエンドのインデックス作成に続くログを視聴します。
$ npx convex dashboard
Logsパネルには、環境変数が欠落していることに関するエラーが表示されます。もう少しセットアップしています!
Dryadは、要約と埋め込みにOpenaiを使用します。 OpenAIプラットフォームアカウントとAPIキーが必要です。 Platform.openai.comにアクセスして、それを処理してください。
ショ和 中程度のコードベースを要約してインデックス化すると、かなりの量のOpenAIクレジットが消費されます。ほぼ間違いなく有料アカウントが必要になります!
GitHub APIの匿名の使用は、非常に簡単に制限されます。したがって、dryadは、githubアカウントを使用して個人的なアクセストークンを生成する必要があります。 https://github.com/settings/tokensにアクセスして、Dryadのトークンを生成してください。
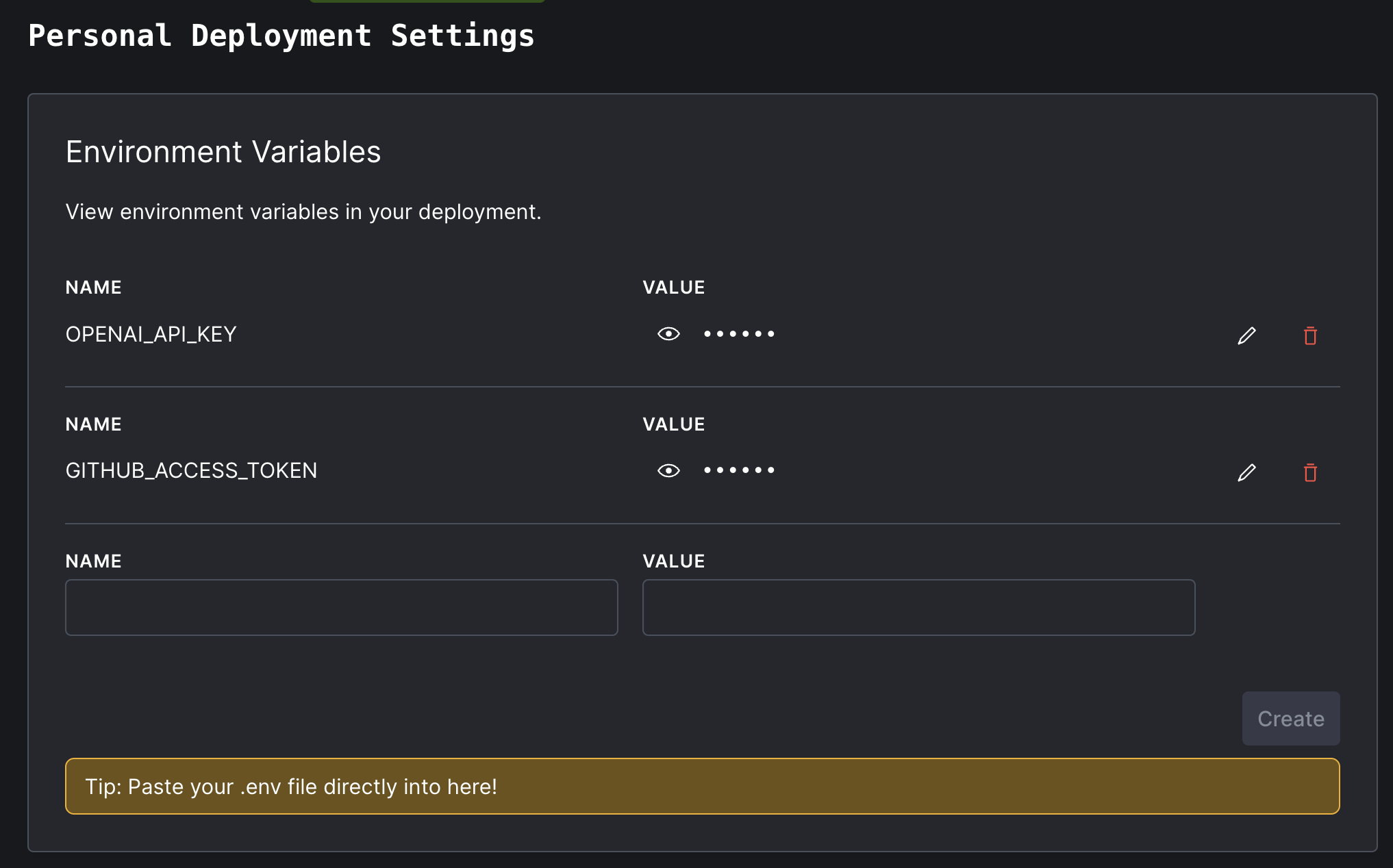
OpenAI APIキーとGitHub Accessトークンを手にして、Convex Deploymentのダッシュボードに戻ります。左のナビゲーションパネルで、[設定]をクリックしてから「環境変数」をクリックします。
2つの秘密環境変数をOPENAI_API_KEYとGITHUB_ACCESS_TOKENに名前を付けます。
settingsテーブルでドライド設定をカスタマイズしますconvexダッシュボードのLogsビューを確認すると、Dryadが正常に実行されるようになりました!ただし、デフォルトのリポジトリ、 get-convex/convex-helpersインデックス作成です。代わりに独自のコードをインデックス化することを望んでいるでしょう。
良いニュース! Dryadの動作を簡単にカスタマイズできます。 Dryadは、すべての構成を、凸データベース自体のsettingsテーブルに保持します。ダッシュボードのDataビューをクリックしてから、 settingsテーブルを選択します。
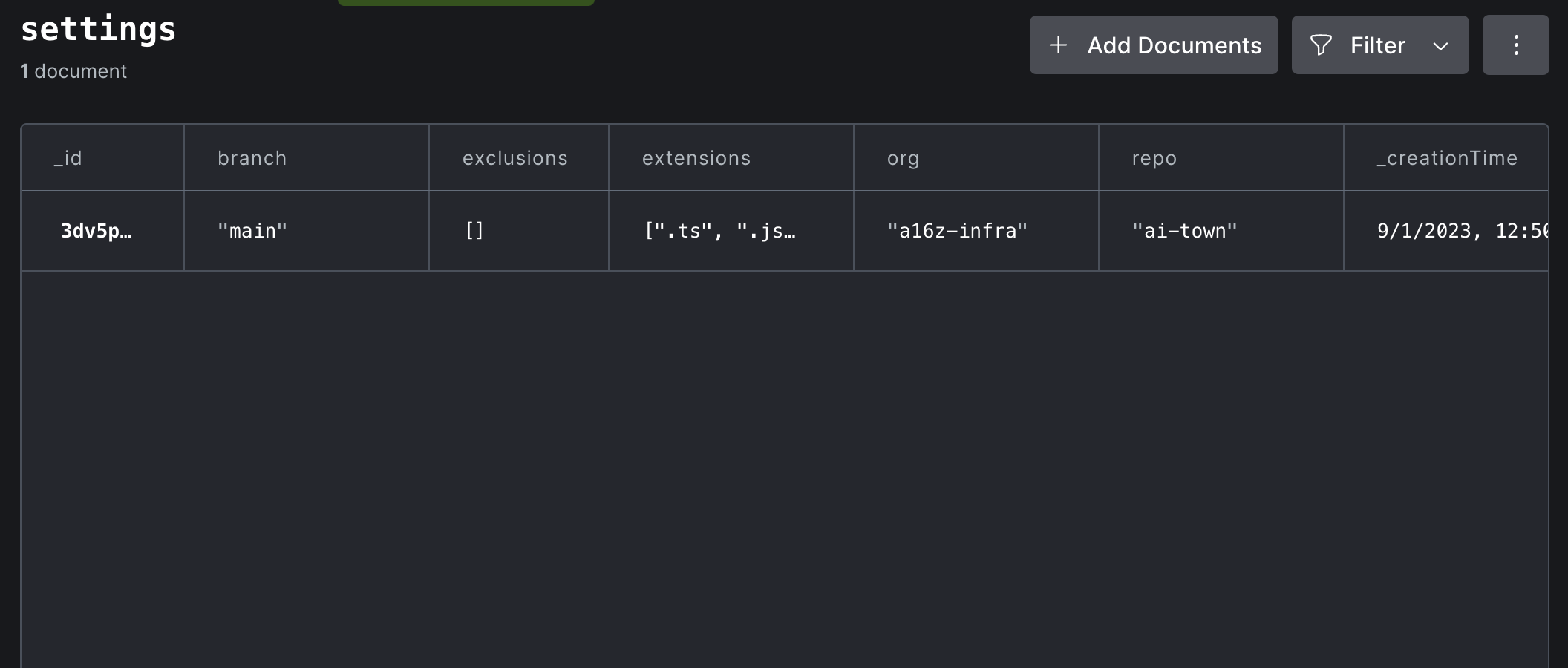
設定ドキュメントの任意の値をダブルクリックして編集するか、[青色の「編集]ボタンをクリックして、欠落しているフィールドをドキュメントに追加します。通常、変更が有効になるために何もする必要はありません。ただし、とにかく再インデックスを行う場合は、ダッシュボードの右下のパネルにあるFn関数ランナーをクリックしてから、 syncState:resetを実行することを選択します。引数は必要ありません。
このテーブルのスキーマは、このリポジトリのconvex/schema.tsにあります。これがどのように見えるかです:
// Various project settings you can tweak in the dashboard as we go.
settings : defineTable ( {
org : v . string ( ) ,
repo : v . string ( ) ,
branch : v . string ( ) ,
extensions : v . array ( v . string ( ) ) ,
exclusions : v . optional ( v . array ( v . string ( ) ) ) , // defaults to no exclusions
byteLimit : v . optional ( v . number ( ) ) , // defaults to 24,000 bytes
chatModel : v . optional ( v . string ( ) ) , // defaults to gpt-4
} ) ,facebookです。reactです。gpt-3.5-turbo 、 gpt-4です。カバーする3つの主なこと:
毎分、Dryadはrepo:syncという名前のジョブを呼び出します。これはsyncStateと呼ばれるテーブルを使用して2つの状態間でループする凸状のアクションです。
新しいコミットの投票中、DryadはGithub API(Octokit経由)を使用して、ターゲットレポ +ブランチのSHAを確認します。 GitHubから戻ってくる値が、 syncState.commitの最後のインデックス付きSHAと同じままである限り、 repo:syncは次の投票まで終了します。
しかし、新しいコミットが発見されると、 syncState.commitフィールドが新しいSHAに設定され、 commitDoneフィールドがfalseに設定されます。これにより、Dryadは「そのコミットそのコミット」モードになります。
コミットのインデックスを作成するとき、 repo:sync最初にGitHub "Tree" APIを使用して、すべてのファイルに関連付けられたファイルチェックサムを含む、そのコミットのファイルツリー全体を取得します。
その後、Dryadはこのツリー全体を歩き、ソースコードファイルを探しています(「設定」テーブルの拡張機能に従って)。すべてのソースファイルについて、ファイルが最後にインデックス化された時からチェックサムが変更されたかどうかを判断します。ファイルが新品または変更されている場合、リポジトリからダウンロードされて再インデックスされます。
それ以外の場合、ファイルは新しいコミットで有効な電流がマークされています。
最後に、ツリー内のすべてのファイルが適切にインデックス化された後、この新しいコミットツリーの一部がなくなったファイルはインデックスから削除されます。
そして、それで、 commitDoneはTrueに設定され、Dryadは新しいコミットのために投票に戻ります。
ソースファイルのインデックス作成には、次の3つのステップが含まれます。
filesの親ソースファイルレコードを参照して、各目標と関連するベクトルをconvexのfileGoalsテーブルに保存します。目標のベクトルフィールドは、convexのベクトルインデックスを使用して、Webアプリからの高速検索をサポートすることです。 誰かがWebアプリでクエリを提出すると、Dryadは同じOpenai Embeddings APIを使用してベクトルを生成し、convexのベクトルインデックスを使用して、検索用語に意味的に類似した目標を持つソースファイルを見つけます。
検索は、各ソースファイルのみを一度に返し、結果セットにそのファイルが含める主な理由として最高の目標を返します。
この時点では、Dryadは非常に基本的です!プロジェクトを取り入れることができる多くの道順があります。
このプロジェクトの問題は、潜在的な拡張とドライアドの改善のコレクションでシードされており、ホイールがドライアドから構築できるより洗練されたものを回すようにしています。
ハッピーハッキング!
私たちの不一致に参加して、ドライアドについて話してください。
convexは、タイプスクリプトにデータベーススキーマとサーバー機能を記述できる内蔵データベースを備えたホストされたバックエンドプラットフォームです。サーバー側のデータベースクエリは、自動的にデータをキャッシュして購読し、ReactクライアントのリアルタイムuseQueryフックに電力を供給します。また、Python、Rust、Reactnative、Nodeのクライアント、および簡単なHTTP APIもあります。
データベースは、関係とカスタムインデックス(ネストされたオブジェクトのフィールドを含む)を備えたNOSQLスタイルのドキュメントをサポートしています。
queryおよびmutationサーバー関数には、データベースへのトランザクション、低レイテンシアクセスがあり、 v8ランタイムを決定論的なガードレールで活用して、市場で最も強力な酸の保証を提供します。
actionサーバー関数は、外部APIにアクセスし、最適化されたv8ランタイムまたはより柔軟なnodeランタイムのいずれかで、他の副作用と非決定的な実行を有効にします。
関数は、スケジューリングおよびCronジョブを介してバックグラウンドで実行できます。
開発はクラウドファーストであり、CLIを介したサーバー機能の編集用のホットリロードがあります。データを参照して編集し、環境変数の編集、ログの表示、サーバー関数の実行など、ダッシュボードUIがあります。
リアクティブページネーション、ファイルストレージ、リアクティブ検索、HTTPSエンドポイント(Webhooks用)、インポート/エクスポートのストリーミング、および機能引数とデータベースデータのランタイムデータ検証用の組み込み機能があります。
すべてが自動的にスケーリングされ、自由に開始できます。


