codeqai
0.0.18
Pesquise sua base de código semanticamente ou converse com ela da CLI. Mantenha o banco de dados vetorial super rápido até as mudanças mais recentes de código. 100% de suporte local sem dados de dados.
Construído com Langchain, Treesitter, Transformadores de frases, Encedimento de Instrutores, Faiss, Lama.CPP, Ollama, Streamlit.
Observação
Haverá melhores resultados se o código estiver bem documentado. Você pode considerar o Doc-Commments-AI para a geração de documentação do código.
codeqai search
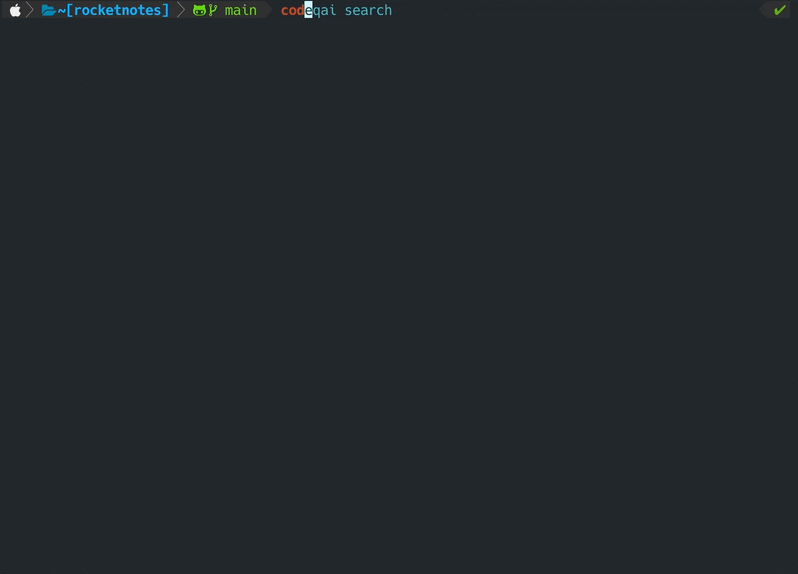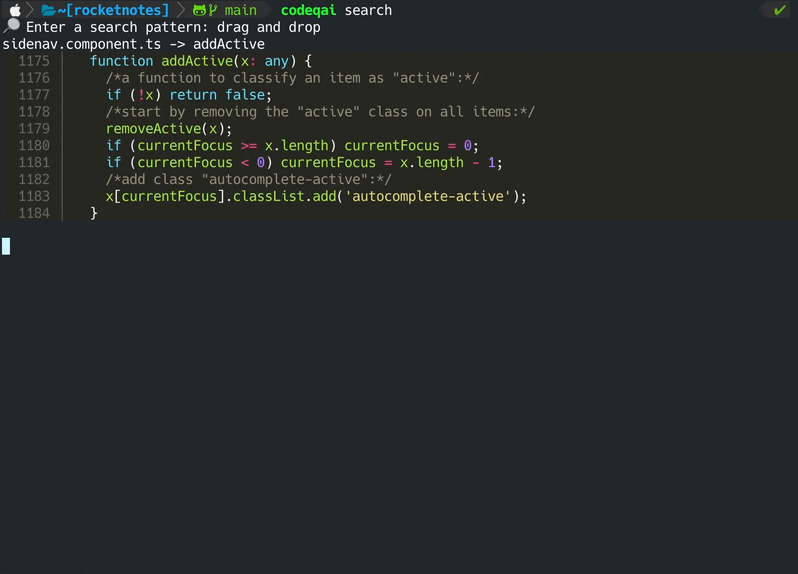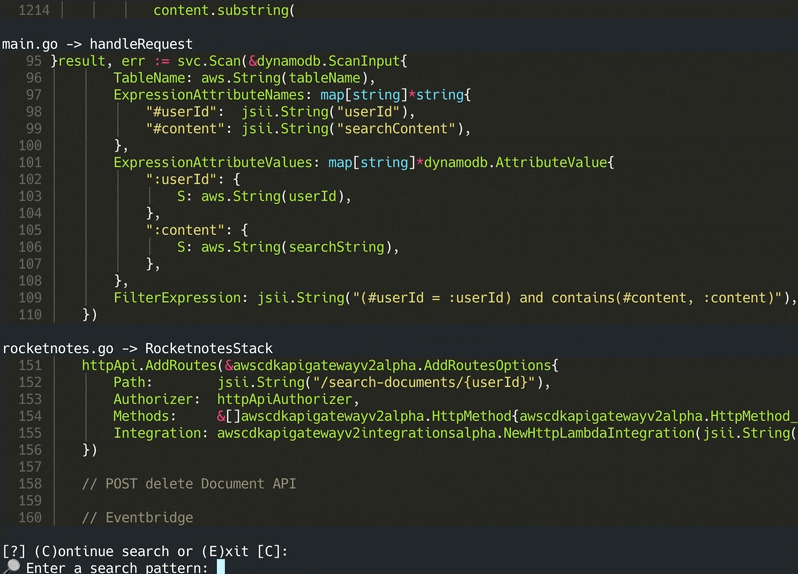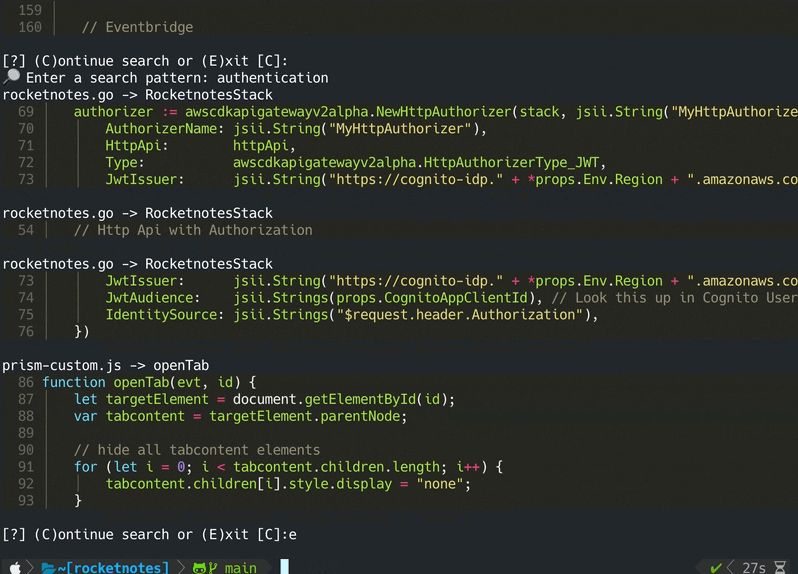
codeqai chat
codeqai sync
codeqai app
Observação
No primeiro uso, o repositório será indexado com o modelo de incorporação configurado que pode demorar um pouco.
Instale em um ambiente isolado com pipx :
pipx install codeqai
Verifique se o PIPX está usando Python> = 3,9, <3,12.
Para especificar a versão Python explicitamente com o PIPX, ative a versão Python desejada (por exemplo, com pyenv shell 3.XX ) e instale com:
pipx install codeqai --python $(which python)
Se você ainda estiver enfrentando problemas usando o PIPX, também pode instalar diretamente da fonte através do Pypi com:
pip install codeqai
No entanto, é recomendável usar o PIPX para se beneficiar de ambientes isolados para as dependências.
Visite a seção Solução de problemas para obter soluções de questões conhecidas durante a instalação.
Observação
Alguns pacotes não são instalados por padrão. No primeiro uso, é solicitado que ele instale faiss-cpu ou faiss-gpu . O FAISS-GPU é recomendado se o hardware suportar o CUDA 7.5+. Se forem usadas incorporações e LLMs locais, será solicitado que ele instale o Instrutor, instrutor ou llama.cpp.
No primeiro uso ou correndo
codeqai configure
O processo de configuração é iniciado, onde as incorporações e LLMs podem ser escolhidos.
Importante
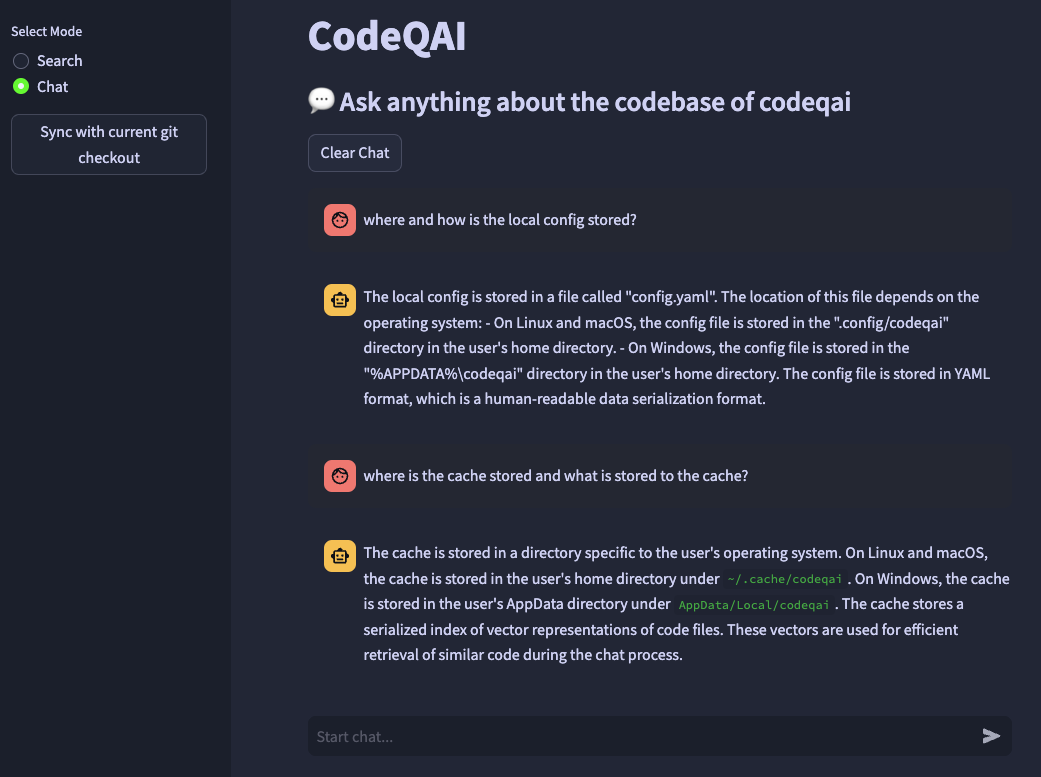
Se você deseja alterar o modelo de incorporação na configuração posteriormente, exclua os arquivos em cache em ~/.cache/codeqai . Posteriormente, os arquivos do Vector Store são criados novamente com o modelo recente de incorporação configurada. Isso é necessário, pois a pesquisa de similaridade não funciona se os modelos diferentes.
Se os modelos remotos forem usados, as seguintes variáveis de ambiente serão necessárias. Se as variáveis de ambiente necessárias já estiverem definidas, elas serão usadas, caso contrário, você será solicitado a inseri -las que serão armazenadas em ~/.config/codeqai/.env .
export OPENAI_API_KEY = " your OpenAI api key " export OPENAI_API_TYPE = " azure "
export AZURE_OPENAI_ENDPOINT = " https://<your-endpoint>.openai.azure.com/ "
export OPENAI_API_KEY = " your Azure OpenAI api key "
export OPENAI_API_VERSION = " 2023-05-15 " export ANTHROPIC_API_KEY= " your Anthropic api key " Observação
Para alterar as variáveis de ambiente posteriormente, atualize o ~/.config/codeqai/.env manualmente.
Todo o repositório Git é analisado com o Treesitter para extrair todos os métodos com documentações e salvo para um banco de dados de vetor de FAISS local com transformadores de frases, instrutores-Enceddings ou o Text-Ada-002 do OpenAi.
O banco de dados vetorial é salvo em um arquivo no seu sistema e será carregado mais tarde novamente após uso adicional. Posteriormente, é possível fazer pesquisa semântica na base de código com base no modelo de incorporação.
Para conversar com a base de código localmente llama.cpp ou ollama é usado especificando o modelo desejado. Para a sincronização de alterações recentes no repositório, os hashes do Git Commit de cada arquivo junto com os IDs do vetor são salvos em um cache. Ao sincronizar o banco de dados vetorial com o estado Git mais recente, os hashes de comprometimento em cache são comparados com o hash git atual de cada arquivo no repositório. Se os hashes do Commit Git diferentes, os vetores relacionados serão excluídos do banco de dados e inseridos novamente após a recriação das incorporações do vetor. Usando llama.cpp O modelo especificado precisa estar disponível com antecedência. Usando Ollama, o contêiner Ollama com o modelo desejado precisa estar executando localmente com antecedência na porta 11434. Também o OpenAI ou o Azure-Openai pode ser usado para modelos de bate-papo remoto.
Instale o huggingface-cli e faça o download do modelo desejado no hub do modelo. Por exemplo
huggingface-cli download TheBloke/CodeLlama-13B-Python-GGUF codellama-13b-python.Q5_K_M.gguf
Faça o download do modelo codellama-13b-python.Q5_K_M . Depois que o download terminar o caminho absoluto do modelo. O arquivo .gguf é impresso no console.
Importante
Os modelos compatíveis llama.cpp devem estar no formato .gguf .
pipx pip failed to build package: tiktoken
Some possibly relevant errors from pip install:
error: subprocess-exited-with-error
error: can't find Rust compiler
Verifique se o compilador de ferrugem está instalado no seu sistema a partir daqui.
faiss × Building wheel for faiss-cpu (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [12 lines of output]
running bdist_wheel
...
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for faiss-cpu
Failed to build faiss-cpu
ERROR: Could not build wheels for faiss-cpu, which is required to install pyproject.toml-based projects
Certifique -se de instalar o CodeQAI com Python <3,12. Ainda não existe uma roda FAISS disponível para o Python 3.12.
Se você está perdendo um recurso ou enfrentando um bug, não hesite em abrir um problema ou aumentar um PR. Qualquer tipo de contribuição é muito apreciada!
Para construir e executar o projeto no modo de desenvolvimento, certifique-se de ter conda , conda-lock ou poetry instalado.
Usando conda RONA:
conda env create -f environment.yml -n codeqai
ou usando a execução conda-lock :
conda-lock install --name codeqai conda-<YOUR_PLATFORM>.lock
Ative o ambiente e instale dependências com:
conda activate codeqai && poetry install
Usando a run poetry :
poetry install && poetry shell
Execute eG codeqai chat no ambiente de desenvolvimento com:
poetry run codeqai chat
Execute testes com:
poetry run pytest -s -vv


