codeqai
0.0.18
Suchen Sie Ihre Codebasis semantisch oder chatten Sie mit CLI mit ihm. Halten Sie die Vector -Datenbank übernommen auf dem neuesten Stand der neuesten Codeänderungen. 100% lokaler Support ohne Dataleaks.
Erbaut mit Langchain, Treesitter, Satztransformatoren, Ausbilder-Embedding, Faiss, Lama.cpp, Ollama, Strom.
Notiz
Es wird bessere Ergebnisse geben, wenn der Code gut dokumentiert ist. Sie können DOC-Comments-AI für die Erzeugung von Code-Dokumentationen in Betracht ziehen.
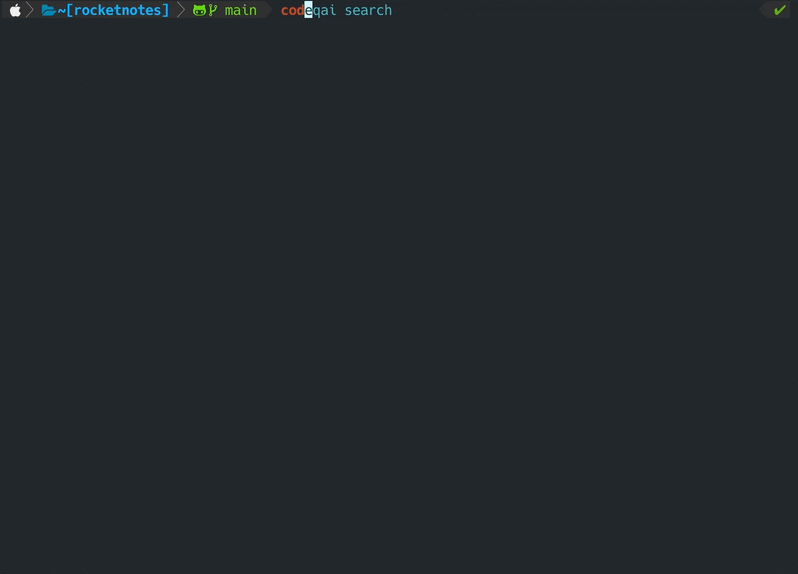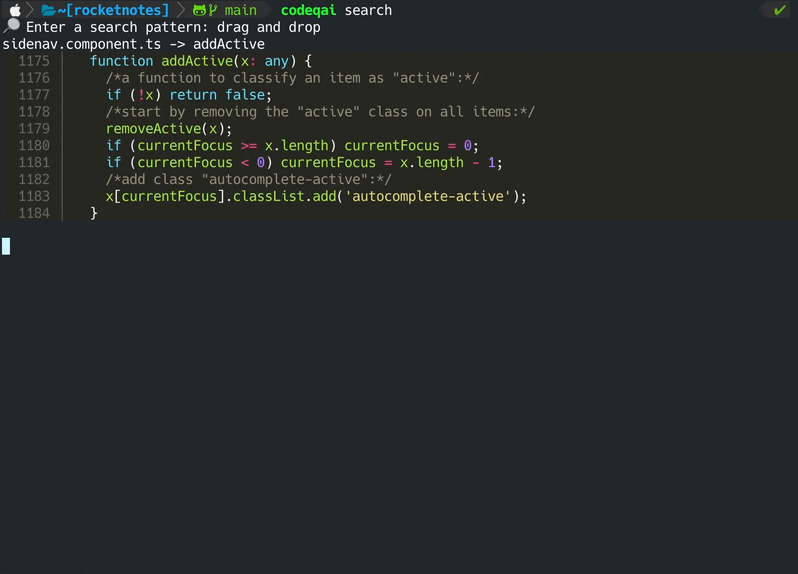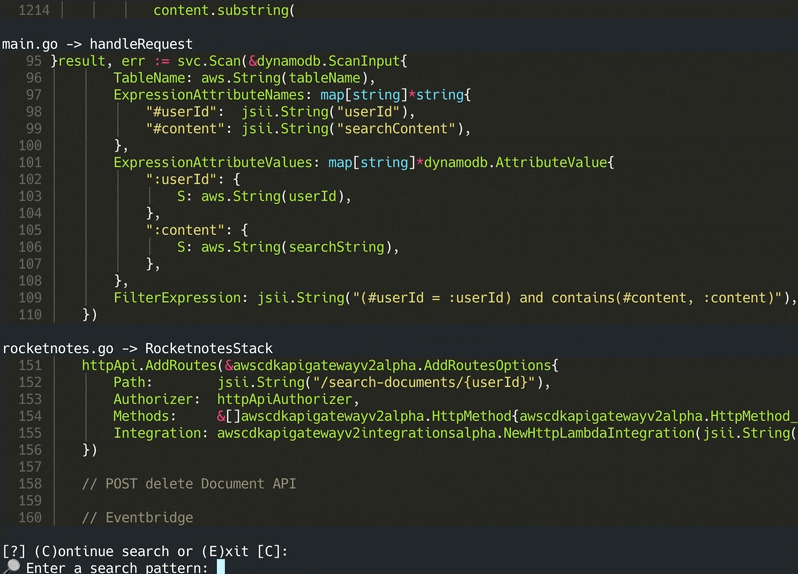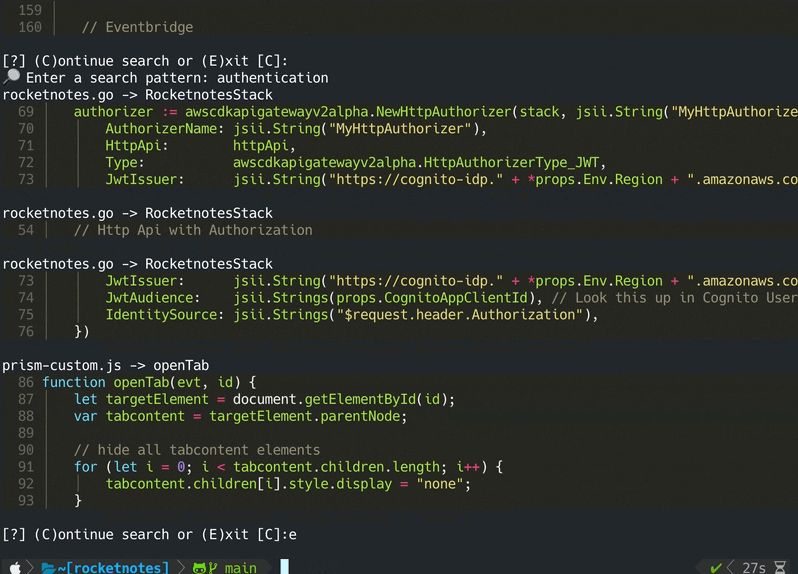
codeqai search
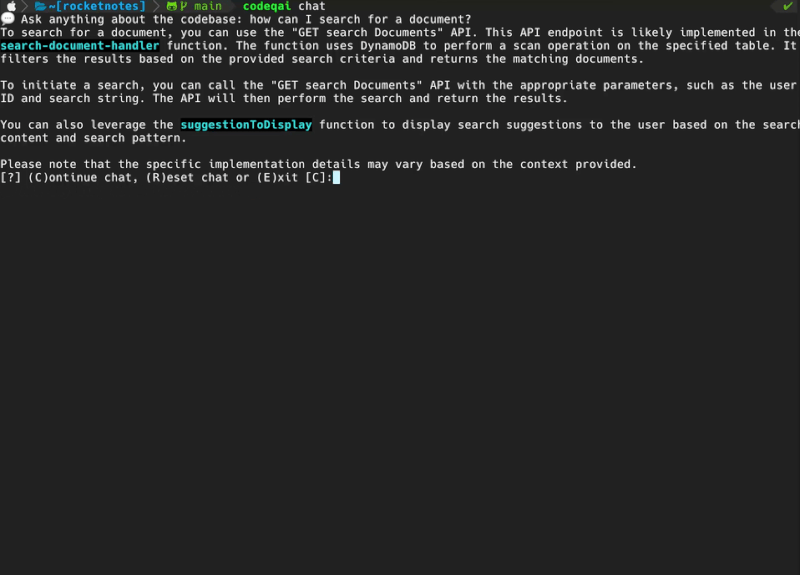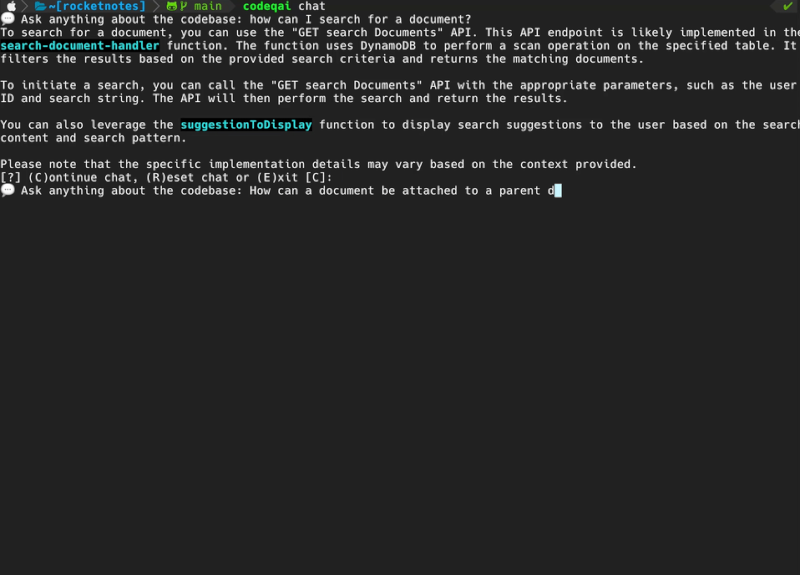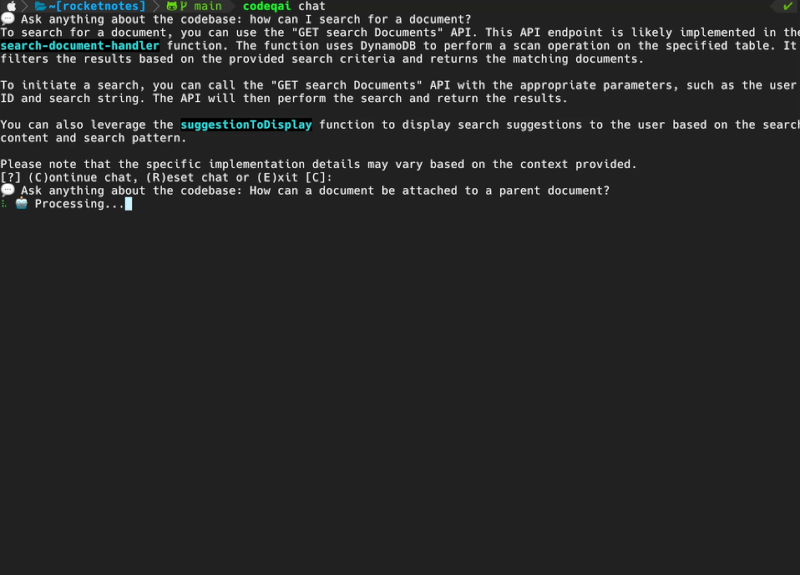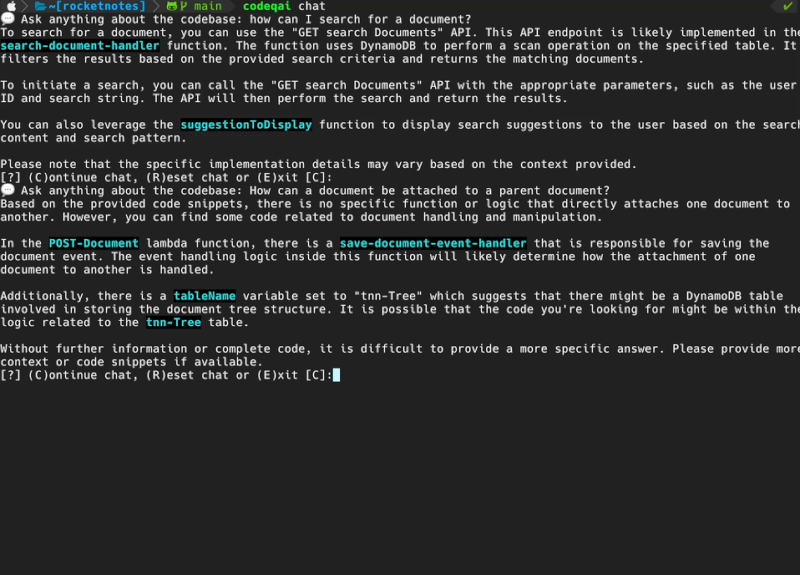
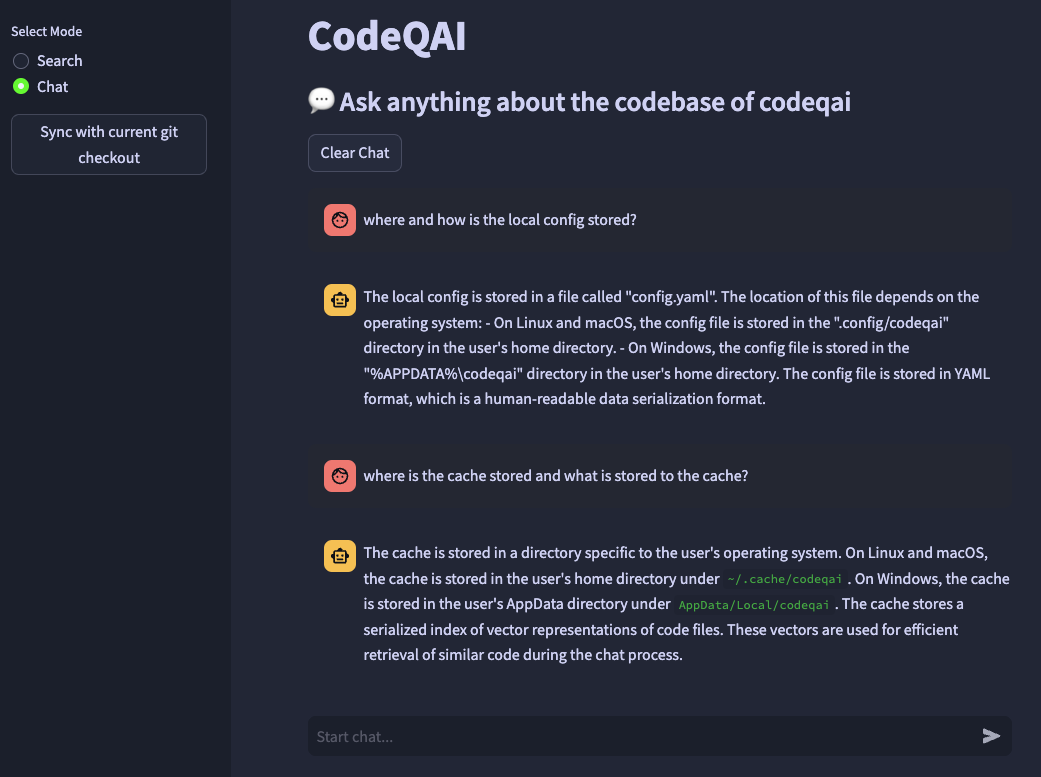
codeqai chat
codeqai sync
codeqai app
Notiz
Bei der ersten Verwendung wird das Repository mit dem konfigurierten Emboden -Modell indexiert, das möglicherweise eine Weile dauern kann.
In einer isolierten Umgebung mit pipx installieren:
pipx install codeqai
Stellen Sie sicher, dass PIPX Python> = 3,9, <3,12 verwendet.
Aktivieren Sie die gewünschte Python -Version (z. B. mit pyenv shell 3.XX ) und installieren Sie die gewünschte Python -Version (z.
pipx install codeqai --python $(which python)
Wenn Sie mit PIPX weiterhin Probleme haben, können Sie auch direkt über PYPI mit:
pip install codeqai
Es wird jedoch empfohlen, PIPX zu verwenden, um von isolierten Umgebungen für die Abhängigkeiten zu profitieren.
Besuchen Sie den Abschnitt zur Fehlerbehebung für Lösungen bekannter Probleme während der Installation.
Notiz
Einige Pakete sind standardmäßig nicht installiert. Auf den ersten Gebrauch wird gebeten, faiss-cpu oder faiss-gpu zu installieren. Faiss-GPU wird empfohlen, wenn die Hardware CUDA 7.5+ unterstützt. Wenn lokale Einbettungen und LLMs verwendet werden, wird dies weiter aufgefordert, Satztransformatoren, Ausbilder oder Lama.cpp zu installieren.
Auf den ersten Gebrauch oder durch Laufen
codeqai configure
Der Konfigurationsprozess wird initiiert, wobei die Einbettungen und LLMs ausgewählt werden können.
Wichtig
Wenn Sie das Embettdings -Modell später in der Konfiguration ändern möchten, löschen Sie die zwischengespeicherten Dateien in ~/.cache/codeqai . Danach werden die Vektorspeicherdateien erneut mit dem aktuellen konfigurierten Embodendings -Modell erstellt. Dies ist teuer, da die Ähnlichkeitssuche nicht funktioniert, wenn sich die Modelle unterscheiden.
Wenn Remote -Modelle verwendet werden, sind die folgenden Umgebungsvariablen erforderlich. Wenn die erforderlichen Umgebungsvariablen bereits festgelegt sind, werden sie verwendet. Andernfalls werden Sie aufgefordert, sie einzugeben, die dann in ~/.config/codeqai/.env gespeichert werden.
export OPENAI_API_KEY = " your OpenAI api key " export OPENAI_API_TYPE = " azure "
export AZURE_OPENAI_ENDPOINT = " https://<your-endpoint>.openai.azure.com/ "
export OPENAI_API_KEY = " your Azure OpenAI api key "
export OPENAI_API_VERSION = " 2023-05-15 " export ANTHROPIC_API_KEY= " your Anthropic api key " Notiz
Um die Umgebungsvariablen später zu ändern, aktualisieren Sie die ~/.config/codeqai/.env manuell.
Das gesamte Git-Repo wird mit Treesitter analysiert, um alle Methoden mit Dokumentationen zu extrahieren, und in einer lokalen Faiss-Vektor-Datenbank mit Satztransformen, Ausbilder-Embedings oder OpenAIs Text-Embedding-ada-002 gespeichert.
Die Vektordatenbank wird in einer Datei in Ihrem System gespeichert und wird später nach weiterer Verwendung erneut geladen. Anschließend ist es möglich, semantische Suche in der Codebasis basierend auf dem Emboden -Modell durchzuführen.
Um mit der Codebase lokal llama.cpp oder Ollama zu chatten, wird durch Angabe des gewünschten Modells verwendet. Für die Synchronisation der jüngsten Änderungen im Repository werden die Git -Hashes jeder Datei zusammen mit den Vektor -IDs in einem Cache gespeichert. Bei der Synchronisierung der Vektordatenbank mit dem neuesten Git -Status werden die zwischengespeicherten Komitee -Hashes mit dem aktuellen Git -Hash jeder Datei im Repository verglichen. Wenn sich die Git Commit -Hashes unterscheiden, werden die zugehörigen Vektoren aus der Datenbank gelöscht und nach der Nachbildung der Vektor -Einbettungen erneut eingefügt. Mit LLAMA.CPP muss das angegebene Modell im Voraus auf dem System verfügbar sein. Mit Ollama muss der OLLAMA-Container mit dem gewünschten Modell im Voraus auf Port 11434 ausgeführt werden. Auch Openai oder Azure-OpenAI kann für Remote-Chat-Modelle verwendet werden.
Installieren Sie das huggingface-cli und laden Sie Ihr gewünschtes Modell aus dem Modell-Hub herunter. Zum Beispiel
huggingface-cli download TheBloke/CodeLlama-13B-Python-GGUF codellama-13b-python.Q5_K_M.gguf
Laden Sie das Modell codellama-13b-python.Q5_K_M herunter. Nachdem der Download den absoluten Pfad des Modells beendet hat .gguf -Datei wird in die Konsole gedruckt.
Wichtig
llama.cpp -kompatible Modelle müssen im .gguf -Format sein.
pipx pip failed to build package: tiktoken
Some possibly relevant errors from pip install:
error: subprocess-exited-with-error
error: can't find Rust compiler
Stellen Sie sicher, dass der Rost -Compiler von hier auf Ihrem System installiert ist.
faiss × Building wheel for faiss-cpu (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [12 lines of output]
running bdist_wheel
...
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for faiss-cpu
Failed to build faiss-cpu
ERROR: Could not build wheels for faiss-cpu, which is required to install pyproject.toml-based projects
Stellen Sie sicher, dass Codesqai mit Python <3.12 installiert ist. Für Python 3.12 ist noch kein Faiss -Rad verfügbar.
Wenn Ihnen eine Funktion fehlt oder sich einen Fehler gegenübersehen, zögern Sie nicht, ein Problem zu eröffnen oder eine PR zu erhöhen. Jede Art von Beitrag wird sehr geschätzt!
Um das Projekt im Entwicklungsmodus zu erstellen und auszuführen, achten Sie darauf, dass conda , conda-lock oder poetry installiert sind.
Durch die Verwendung von conda Run:
conda env create -f environment.yml -n codeqai
oder durch Verwendung von conda-lock Run:
conda-lock install --name codeqai conda-<YOUR_PLATFORM>.lock
Aktivieren Sie die Umgebung und installieren Sie Abhängigkeiten mit:
conda activate codeqai && poetry install
Durch die Verwendung von poetry -Lauf:
poetry install && poetry shell
Führen Sie den EG codeqai chat in der Entwicklungsumgebung aus mit:
poetry run codeqai chat
Führen Sie Tests mit: aus:
poetry run pytest -s -vv


