codeqai
0.0.18
Busque su base de código semánticamente o chatea con ella desde CLI. Mantenga la base de datos Vector Superfast actualizada a los últimos cambios en el código. Soporte 100% local sin ningún DataLeaks.
Construido con Langchain, Treesitter, Frase-Transformers, Instructor Embeding, Faiss, Lama.cpp, Ollama, Streamlit.
Nota
Habrá mejores resultados si el código está bien documentado. Puede considerar DOC-COMMIONS-AI para la generación de documentación de código.
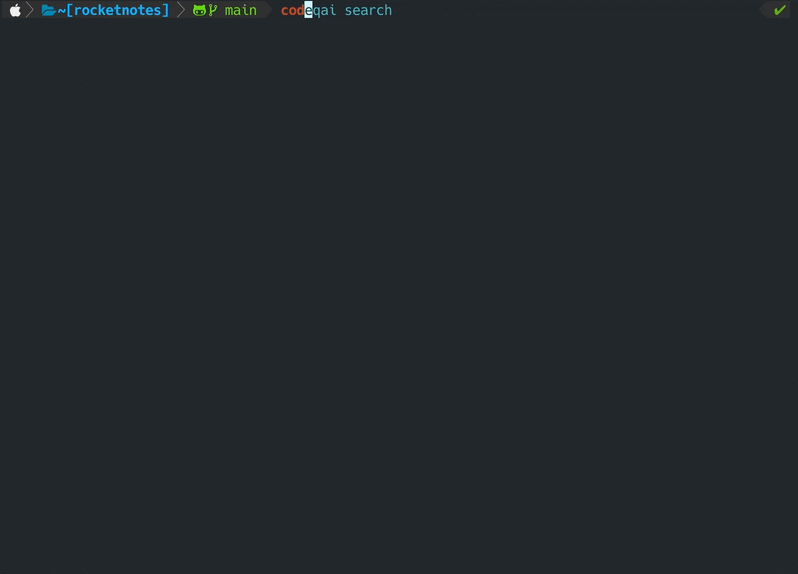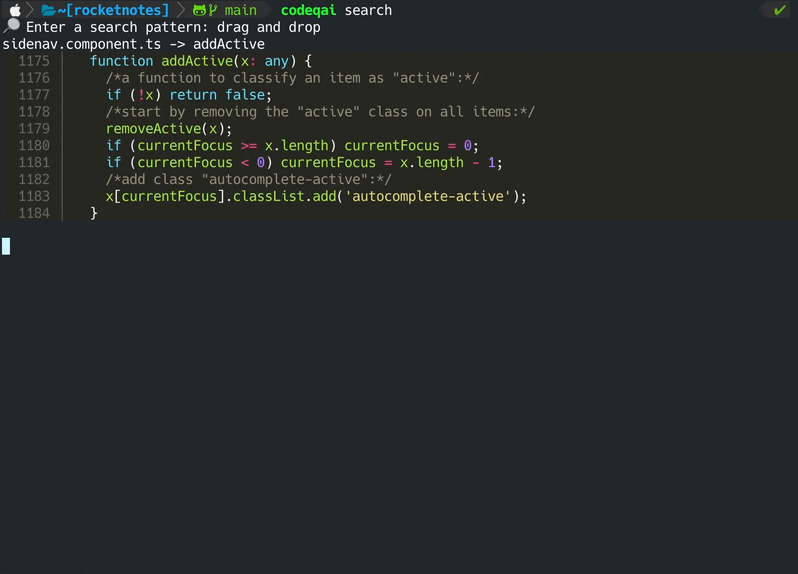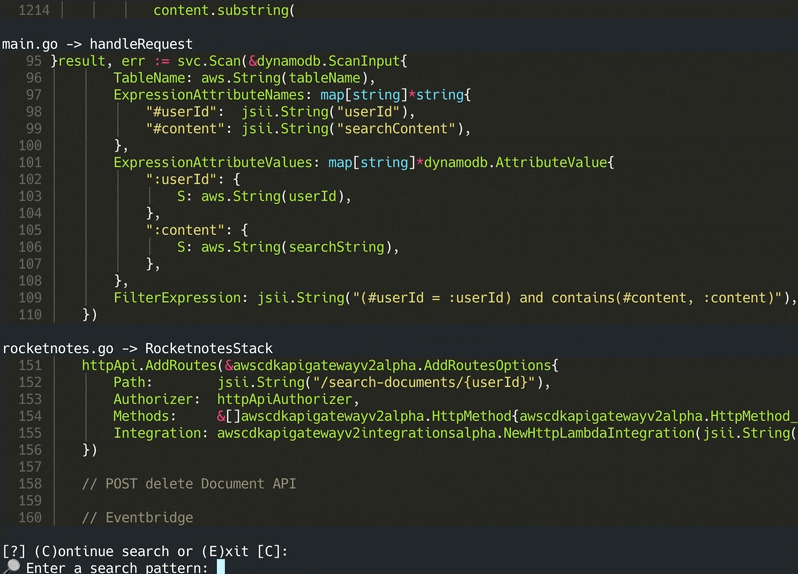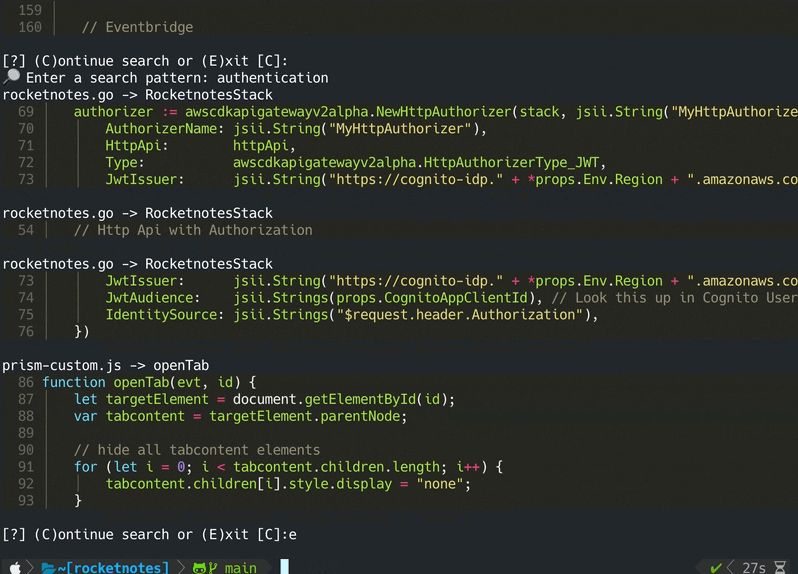
codeqai search
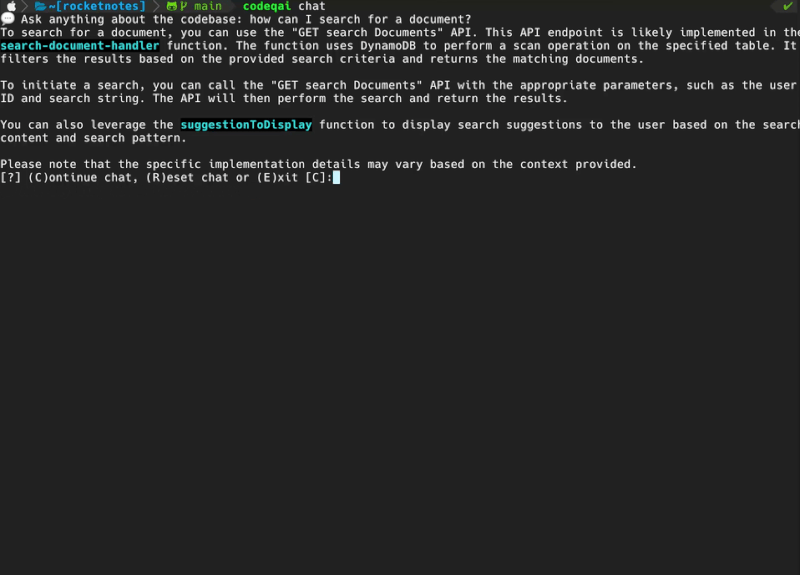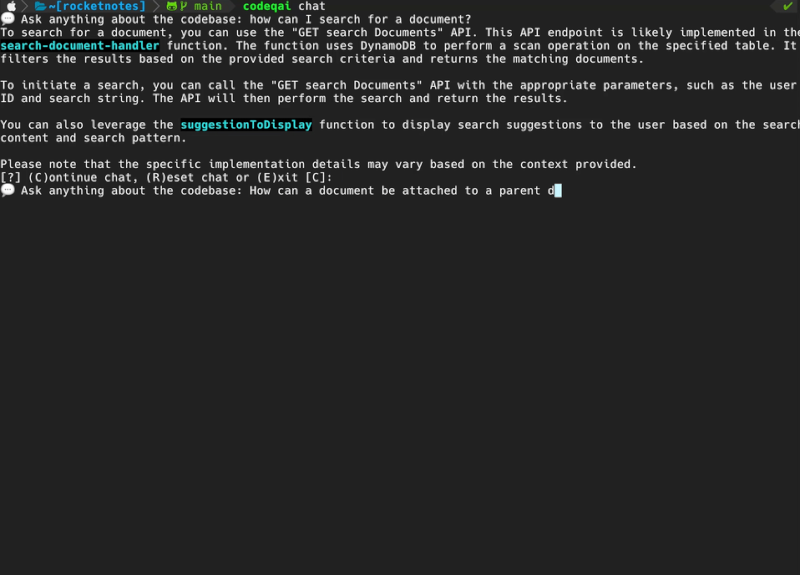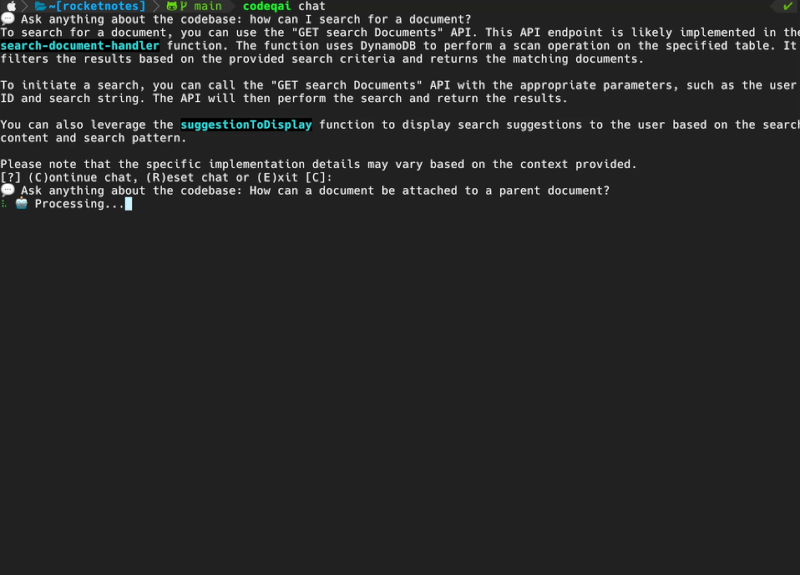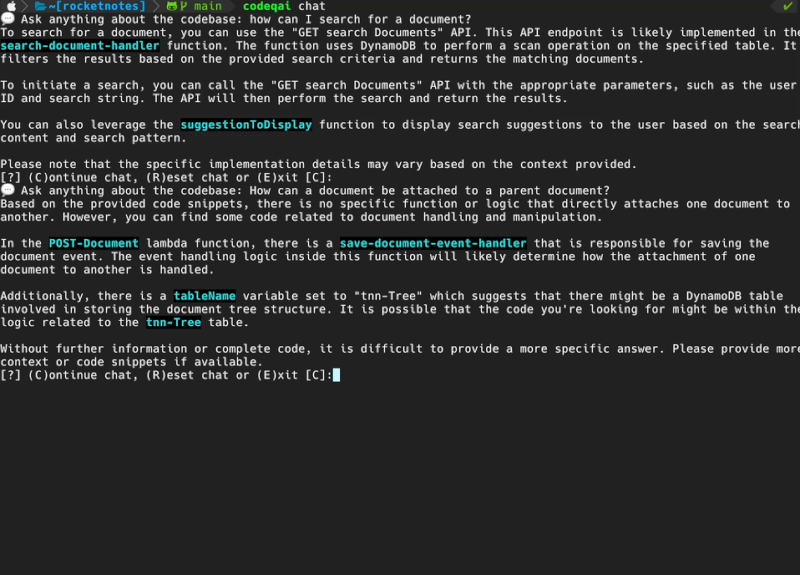
codeqai chat
codeqai sync
codeqai app
Nota
En el primer uso, el repositorio se indexará con el modelo de integración configurado que podría llevar un tiempo.
Instalar en un entorno aislado con pipx :
pipx install codeqai
Asegúrese de que PIPX esté usando Python> = 3.9, <3.12.
Para especificar la versión de Python explícitamente con PIPX, active la versión de Python deseada (por ejemplo, con pyenv shell 3.XX ) e instale con:
pipx install codeqai --python $(which python)
Si todavía enfrenta problemas con PIPX, también puede instalar directamente desde la fuente a través de PYPI con:
pip install codeqai
Sin embargo, se recomienda utilizar PIPX para beneficiarse de entornos aislados para las dependencias.
Visite la sección de solución de problemas para obtener soluciones de problemas conocidos durante la instalación.
Nota
Algunos paquetes no están instalados de forma predeterminada. Al primer uso se le pide que instale faiss-cpu o faiss-gpu . Se recomienda FAISS-GPU si el hardware admite CUDA 7.5+. Si se utilizan integridades locales y LLM, se le pedirá más que instalar transformadores de oraciones, instructor o llama.cpp.
En el primer uso o ejecutando
codeqai configure
Se inicia el proceso de configuración, donde se pueden elegir los incrustaciones y los LLM.
Importante
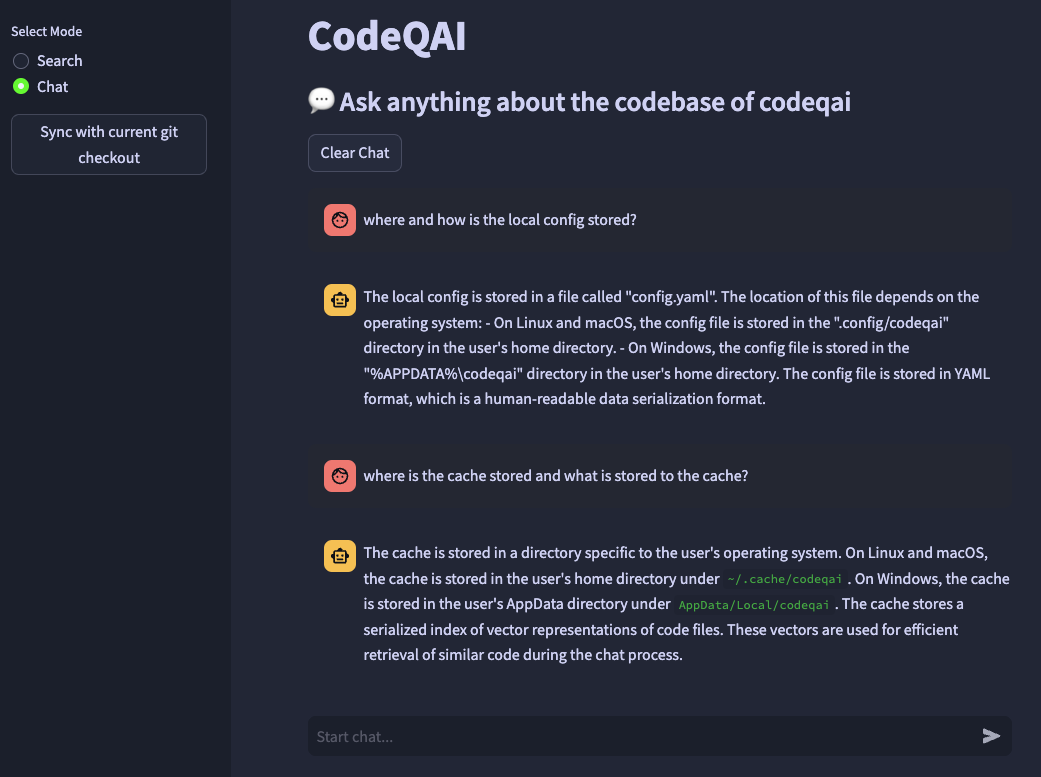
Si desea cambiar el modelo de incrustaciones en la configuración más adelante, elimine los archivos en caché en ~/.cache/codeqai . Luego, los archivos de la tienda Vector se vuelven a crear con el modelo de incrustaciones configurado reciente. Esto es necesario ya que la búsqueda de similitud no funciona si los modelos difieren.
Si se utilizan modelos remotos, se requieren las siguientes variables de entorno. Si las variables de entorno requeridas ya están establecidas, se utilizarán, de lo contrario se le pedirá que ingrese las que luego se almacenan en ~/.config/codeqai/.env .
export OPENAI_API_KEY = " your OpenAI api key " export OPENAI_API_TYPE = " azure "
export AZURE_OPENAI_ENDPOINT = " https://<your-endpoint>.openai.azure.com/ "
export OPENAI_API_KEY = " your Azure OpenAI api key "
export OPENAI_API_VERSION = " 2023-05-15 " export ANTHROPIC_API_KEY= " your Anthropic api key " Nota
Para cambiar las variables de entorno más adelante, actualice el ~/.config/codeqai/.env manualmente.
Todo el repositorio de GIT se analiza con árboles para extraer todos los métodos con documentaciones y se guarda en una base de datos Vector Faiss local con transformadores de oraciones, instructor-incrustación o el texto de OpenAI-Embeding-ADA-002.
La base de datos Vector se guarda en un archivo en su sistema y se cargará más tarde después de un uso adicional. Luego es posible realizar una búsqueda semántica en la base de código basada en el modelo de incrustaciones.
Para chatear con CodeBase localmente llama.cpp o ollama se utiliza especificando el modelo deseado. Para la sincronización de cambios recientes en el repositorio, los hash de cada archivo git de cada archivo junto con las ID de vector se guardan en un caché. Al sincronizar la base de datos Vector con el último estado de GIT, los hash de confirmación en caché se comparan con el hash GIT actual de cada archivo en el repositorio. Si los hashes de confirmación git difieren, los vectores relacionados se eliminan de la base de datos e se insertan nuevamente después de recrear las embedidas del vector. Uso de Llama.cpp El modelo especificado debe estar disponible en el sistema por adelantado. Usando Ollama, el contenedor Ollama con el modelo deseado debe ejecutarse localmente con anticipación en el puerto 11434. También se puede usar OpenAI o Azure-Openai para modelos de chat remotos.
Instale el huggingface-cli y descargue su modelo deseado desde el Model Hub. Por ejemplo
huggingface-cli download TheBloke/CodeLlama-13B-Python-GGUF codellama-13b-python.Q5_K_M.gguf
Descargará el modelo codellama-13b-python.Q5_K_M . Después de que la descarga haya terminado, la ruta absoluta del modelo .gguf se imprime en la consola.
Importante
llama.cpp Los modelos compatibles deben estar en formato .gguf .
pipx pip failed to build package: tiktoken
Some possibly relevant errors from pip install:
error: subprocess-exited-with-error
error: can't find Rust compiler
Asegúrese de que el compilador de óxido esté instalado en su sistema desde aquí.
faiss × Building wheel for faiss-cpu (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [12 lines of output]
running bdist_wheel
...
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for faiss-cpu
Failed to build faiss-cpu
ERROR: Could not build wheels for faiss-cpu, which is required to install pyproject.toml-based projects
Asegúrese de que CodeQai esté instalado con Python <3.12. Todavía no hay rueda Faiss disponible para Python 3.12.
Si le falta una característica o enfrenta un error, no dude en abrir un problema o plantear un PR. ¡Cualquier tipo de contribución es muy apreciada!
Para construir y ejecutar el proyecto en modo de desarrollo, asegúrese de instalar conda , conda-lock o poetry .
Mediante el uso de conda Run:
conda env create -f environment.yml -n codeqai
o usando conda-lock Run:
conda-lock install --name codeqai conda-<YOUR_PLATFORM>.lock
Activar el entorno e instalar dependencias con:
conda activate codeqai && poetry install
Mediante el uso de poetry Run:
poetry install && poetry shell
Ejecute EG codeqai chat dentro del entorno de desarrollo con:
poetry run codeqai chat
Ejecutar pruebas con:
poetry run pytest -s -vv


