codeqai
0.0.18
Recherchez votre base de code sémantiquement ou discutez avec CLI. Gardez à jour la base de données vectorielle à jour pour les dernières modifications de code. Prise en charge locale à 100% sans aucun dataleaks.
Construit avec Langchain, Treesitter, Transformateurs de phrases, instructrice-embouchée, Faiss, Lama.cpp, Olllama, rational.
Note
Il y aura de meilleurs résultats si le code est bien documenté. Vous pourriez considérer Doc-Comements-AI pour la génération de documentation du code.
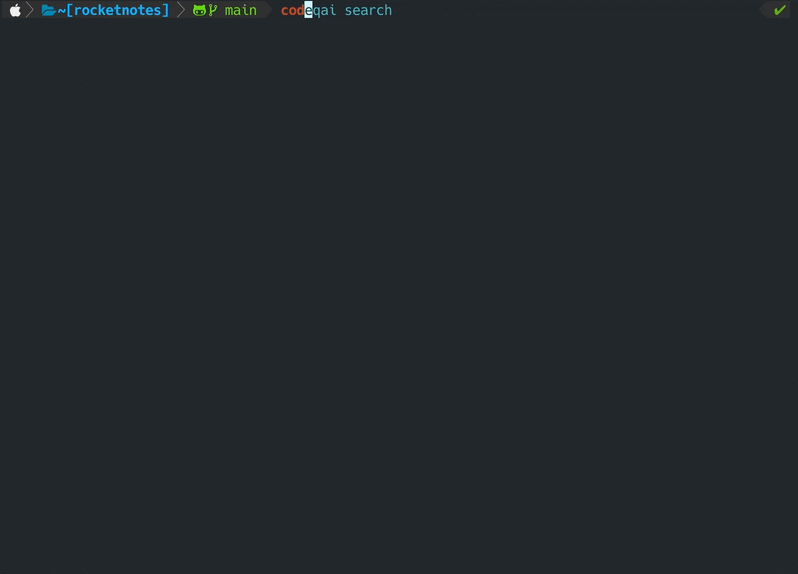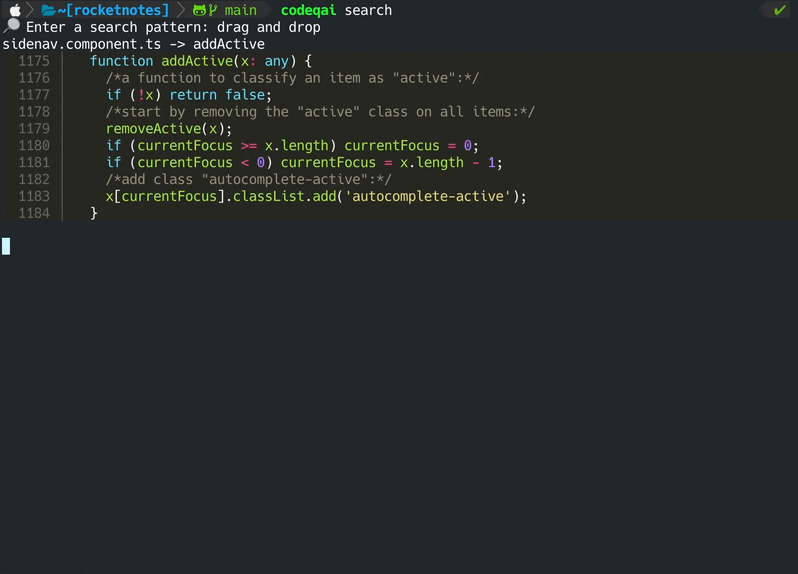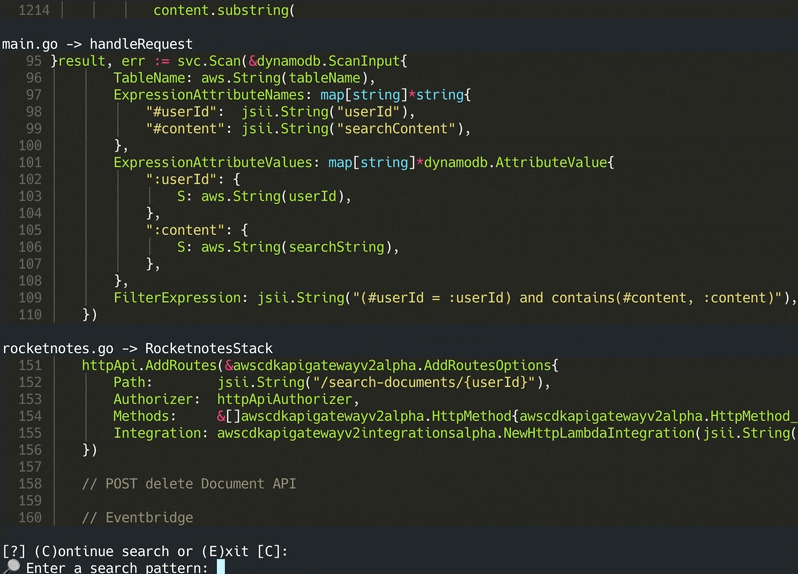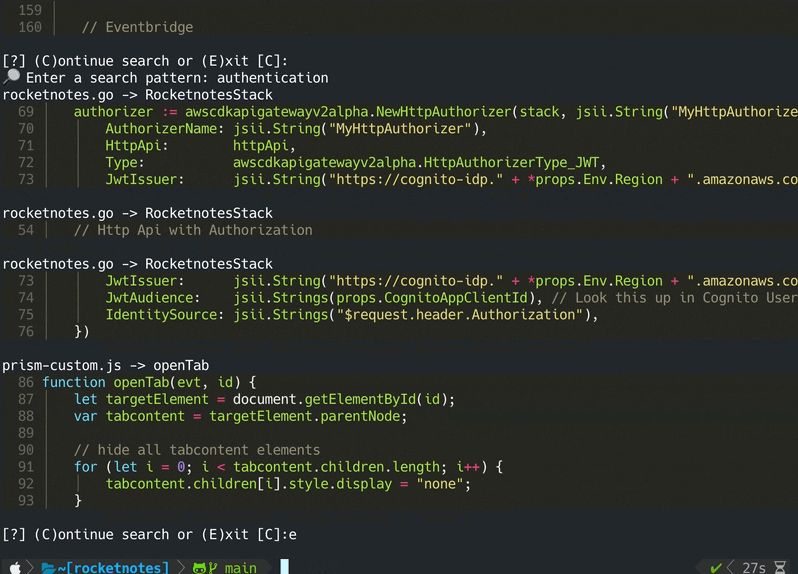
codeqai search
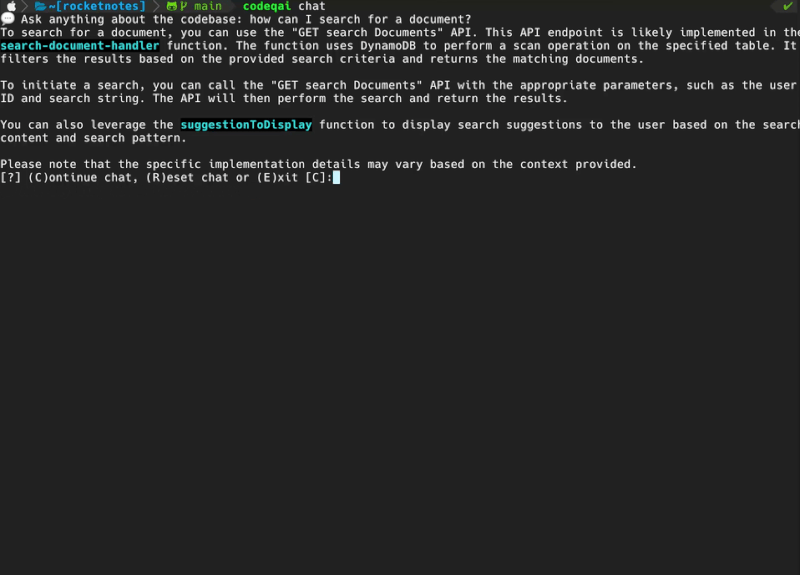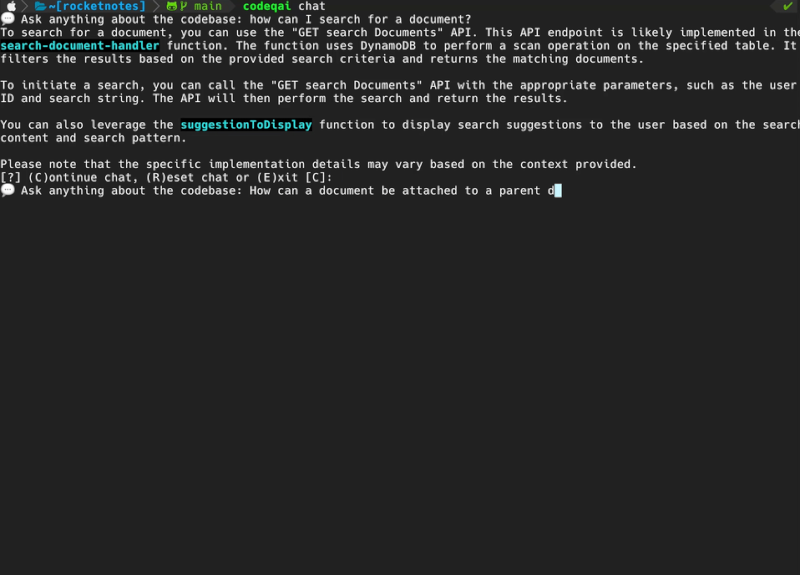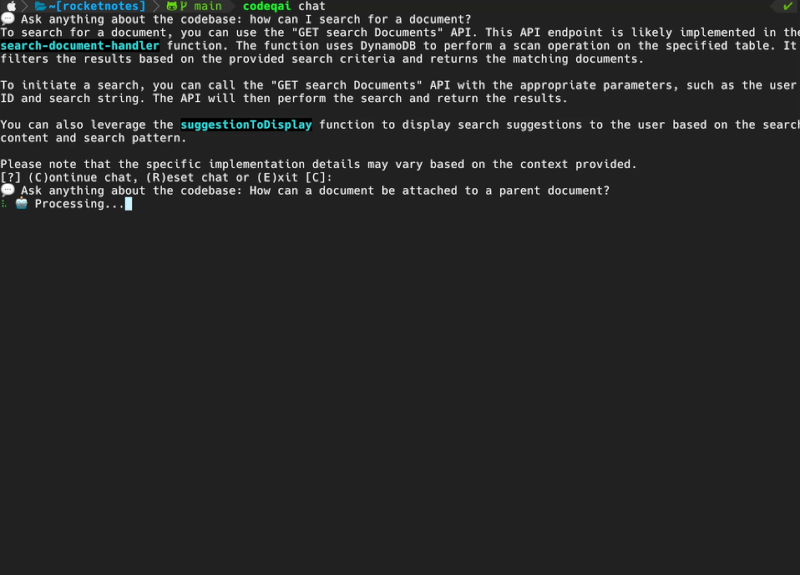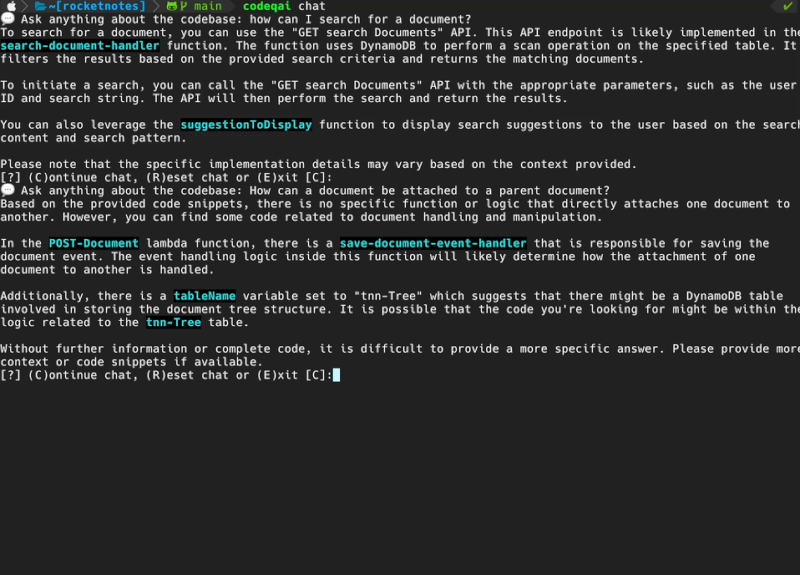
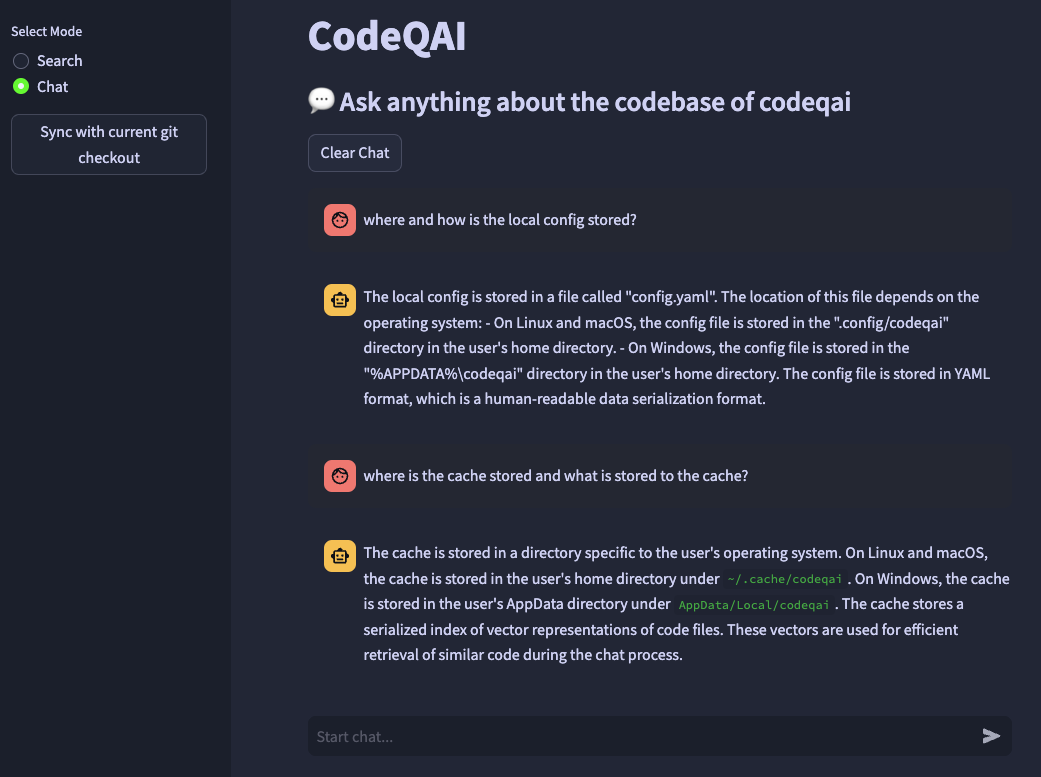
codeqai chat
codeqai sync
codeqai app
Note
À première utilisation, le référentiel sera indexé avec le modèle d'intégration configuré qui pourrait prendre un certain temps.
Installez dans un environnement isolé avec pipx :
pipx install codeqai
Assurez-vous que Pipx utilise Python> = 3,9, <3.12.
Pour spécifier la version Python explicitement avec PIPX, activez la version Python souhaitée (par exemple avec pyenv shell 3.XX ) et installez avec:
pipx install codeqai --python $(which python)
Si vous êtes toujours confronté à des problèmes en utilisant PIPX, vous pouvez également installer directement à partir de la source via PYPI avec:
pip install codeqai
Cependant, il est recommandé d'utiliser PIPX pour bénéficier d'environnements isolés pour les dépendances.
Visitez la section de dépannage pour les solutions de problèmes connus lors de l'installation.
Note
Certains packages ne sont pas installés par défaut. À première utilisation, il est demandé d'installer faiss-cpu ou faiss-gpu . FAISS-GPU est recommandé si le matériel prend en charge CUDA 7.5+. Si des intégres locaux et des LLM sont utilisés, il sera en outre demandé d'installer des transformateurs de phrases, instructor ou llama.cpp.
À première utilisation ou en courant
codeqai configure
Le processus de configuration est initié, où les incorporations et les LLM peuvent être choisis.
Important
Si vous souhaitez modifier le modèle Embeddings dans la configuration ultérieurement, supprimez les fichiers mis en cache dans ~/.cache/codeqai . Ensuite, les fichiers de magasin vectoriel sont à nouveau créés avec le modèle d'intégration configuré récent. Ceci est nécessaire car la recherche de similitude ne fonctionne pas si les modèles diffèrent.
Si des modèles distants sont utilisés, les variables d'environnement suivantes sont nécessaires. Si les variables d'environnement requises sont déjà définies, elles seront utilisées, sinon vous serez invité à les entrer qui sont ensuite stockés dans ~/.config/codeqai/.env .
export OPENAI_API_KEY = " your OpenAI api key " export OPENAI_API_TYPE = " azure "
export AZURE_OPENAI_ENDPOINT = " https://<your-endpoint>.openai.azure.com/ "
export OPENAI_API_KEY = " your Azure OpenAI api key "
export OPENAI_API_VERSION = " 2023-05-15 " export ANTHROPIC_API_KEY= " your Anthropic api key " Note
Pour modifier les variables d'environnement plus tard, mettez à jour manuellement le ~/.config/codeqai/.env .
L'ensemble du dépôt Git est analysé avec Treesitter pour extraire toutes les méthodes avec des documentations et enregistrée dans une base de données VAIS Vector locale avec des transformateurs de phrases, des instructeurs-embouchés ou du texte-Embedding-ADA-002 d'OpenAI.
La base de données vectorielle est enregistrée dans un fichier sur votre système et sera à nouveau chargée plus tard après une utilisation supplémentaire. Ensuite, il est possible de faire une recherche sémantique sur la base de code basée sur le modèle Embeddings.
Pour discuter avec la base de code localement llama.cpp ou olllama est utilisé en spécifiant le modèle souhaité. Pour la synchronisation des changements récents dans le référentiel, les hachages GIT commet de chaque fichier avec les ID vectoriels sont enregistrés sur un cache. Lors de la synchronisation de la base de données vectorielle avec le dernier état GIT, les hachages de validation en cache sont comparés au hachage GIT actuel de chaque fichier dans le référentiel. Si les hachages de validation GIT diffèrent, les vecteurs associés sont supprimés de la base de données et insérés à nouveau après avoir recréé les intégres vectoriels. En utilisant LLAMA.CPP, le modèle spécifié doit être disponible à l'avance sur le système. Utilisation d'Olllama Le conteneur Olllama avec le modèle souhaité doit être exécuté localement à l'avance sur le port 11434. Openai ou Azure-Openai peuvent être utilisés pour des modèles de chat distants.
Installez le huggingface-cli et téléchargez votre modèle souhaité à partir du Hub Model. Par exemple
huggingface-cli download TheBloke/CodeLlama-13B-Python-GGUF codellama-13b-python.Q5_K_M.gguf
Téléchargera le modèle codellama-13b-python.Q5_K_M . Une fois le téléchargement terminé, le chemin absolu du modèle .gguf Le fichier est imprimé sur la console.
Important
Les modèles compatibles llama.cpp doivent être au format .gguf .
pipx pip failed to build package: tiktoken
Some possibly relevant errors from pip install:
error: subprocess-exited-with-error
error: can't find Rust compiler
Assurez-vous que le compilateur de rouille est installé sur votre système à partir d'ici.
faiss × Building wheel for faiss-cpu (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [12 lines of output]
running bdist_wheel
...
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for faiss-cpu
Failed to build faiss-cpu
ERROR: Could not build wheels for faiss-cpu, which is required to install pyproject.toml-based projects
Assurez-vous que CodeQai soit installé avec Python <3.12. Il n'y a pas encore de roue FAISS disponible pour Python 3.12.
Si vous manquez une fonctionnalité ou confronté un bug, n'hésitez pas à ouvrir un problème ou à soulever un RP. Tout type de contribution est très apprécié!
Pour construire et exécuter le projet en mode de développement, assurez-vous de faire installer conda , conda-lock ou poetry .
En utilisant conda Run:
conda env create -f environment.yml -n codeqai
ou en utilisant la course conda-lock :
conda-lock install --name codeqai conda-<YOUR_PLATFORM>.lock
Activez l'environnement et installez les dépendances avec:
conda activate codeqai && poetry install
En utilisant la run poetry :
poetry install && poetry shell
Exécutez par exemple codeqai chat dans l'environnement de développement avec:
poetry run codeqai chat
Exécutez des tests avec:
poetry run pytest -s -vv


