SDFT
1.0.0
SDFT는 자체 교육 프로젝트로, 주요 안정적인 확산 미세 조정 기술을 개요하는 것을 목표로합니다. 안정적인 확산 구현은 Huggingface Diffusers Library에서 가져옵니다.
개요 기술 :
모든 미세 조정 기술은 "Dark Fantasy"라는 손으로 만든 장난감 데이터 세트에서 수행되었습니다. 데이터 세트는 1970 년대와 1980 년대를 연상시키는 스타일로 어두운 전파와 같은 이미지를 생성하기 위해 안정적인 확산 XL Base-1.0 모델을 사용하여 세밀한 프롬프트를 사용하여 수집되었습니다. 목표는이 데이터 세트에서 모든 기술이 어떻게 요약되어 있는지 보여주는 것입니다.
데이터 세트는 datasets/ 디렉토리에서 찾을 수 있습니다.
lora와 함께 sdxl을 미세 조정하기 위해 :
accelerate launch train_lora_sdxl.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--allow_tf32
--mixed_precision= " fp16 "
--rank=32
--train_data_dir=datasets/dark_fantasy/
--caption_column= " text "
--dataloader_num_workers=16
--resolution=512
--use_center_crop
--use_random_flip
--train_batch_size=2
--gradient_accumulation_steps=4 --gradient_checkpointing
--max_train_steps=1500
--learning_rate=1e-04
--max_grad_norm=5
--lr_scheduler= " cosine_with_restarts "
--lr_warmup_steps=100
--output_dir=runs/lora_run/
--checkpointing_steps=100
--validation_epochs=10
--num_validation_images=4
--save_images_on_disk
--validation_prompt= " A picture of a misterious figure in cape, back view. "
--logging_dir= " logs "
--seed=1337LORA 체크 포인트와의 추론을 실행하려면 :
accelerate launch run_lora_inference.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--output_dir=runs/lora_v1/
--lora_checkpoint_path=runs/lora_run/checkpoint-100/
--resolution=1024
--num_images_to_generate=5
--guidance_scale=5.0
--num_inference_steps=40
--prompt= " A picture of a misterious figure in cape, back view. "
--negative_prompt= " logo, watermark, text, blurry "
--seed=1337LORA -LORA 이미지 비교 없음. 동일한 잠복을 사용하여 이미지 쌍이 생성되었습니다.
"A picture of a heavy red Kenworth truck riding in the night across the abanoned city streets."

"A picture of a wounded orc warrior, climbing in misty mountains, front view, exhausted face, looking at the camera."

"A picture of space rocket launching, Earth on the background, candid photo."

"A picture of a supermassive black hole, devouring the galaxy, cinematic picture"

"A picture of a human woman warrior, black hair, looking at the camera, front view."

텍스트 반전 (TI)으로 SDXL을 미세 조정하기 위해 :
accelerate launch train_ti_sdxl.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--allow_tf32
--mixed_precision= " fp16 "
--train_data_dir=datasets/skull
--learnable_property= " style "
--placeholder_token= " <skull_lamp> "
--initializer_token= " skull "
--num_vectors=8
--resolution=1024
--repeats=1
--train_batch_size=2
--gradient_accumulation_steps=4 --gradient_checkpointing
--max_train_steps=5000
--learning_rate=3e-3
--lr_scheduler= " piecewise_constant "
--lr_warmup_steps=30
--output_dir= " runs/ti_run "
--validation_prompt= " A painting of Eiffel tower in the style of <skull_lamp> "
--num_validation_images=4
--validation_steps=100
--embeddings_save_steps=500
--save_images_on_disk
--use_random_flip
--use_center_crop
--seed=1337 훈련 된 TI 임베딩과의 추론을 실행하려면 :
accelerate launch run_ti_inference.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--output_dir=runs/ti_run
--path_to_embeddings=runs/ti_run/ti-embeddings-final.safetensors
--resolution=1024
--num_images_to_generate=1
--guidance_scale=5.0
--num_inference_steps=50
--placeholder_token= " <skull_lamp> "
--prompt= " A <skull_lamp>, made of lego "
--negative_prompt= " logo, watermark, text, blurry, bad quality "
--seed=1337TI -TI 이미지 비교가 없습니다. 동일한 잠복을 사용하여 이미지 쌍이 생성되었습니다.
참고 : 교육 데이터 세트는 기본 캡션이있는 5 개의 이미지로만 구성되므로 결과는 그다지 고무적이지 않지만 더 세밀하게 그리운 캡션을 도입하면 훨씬 더 나을 것입니다.
"A <skull_lamp>, made of lego."

"A painting of Eiffel tower in the style of <skull_lamp>."
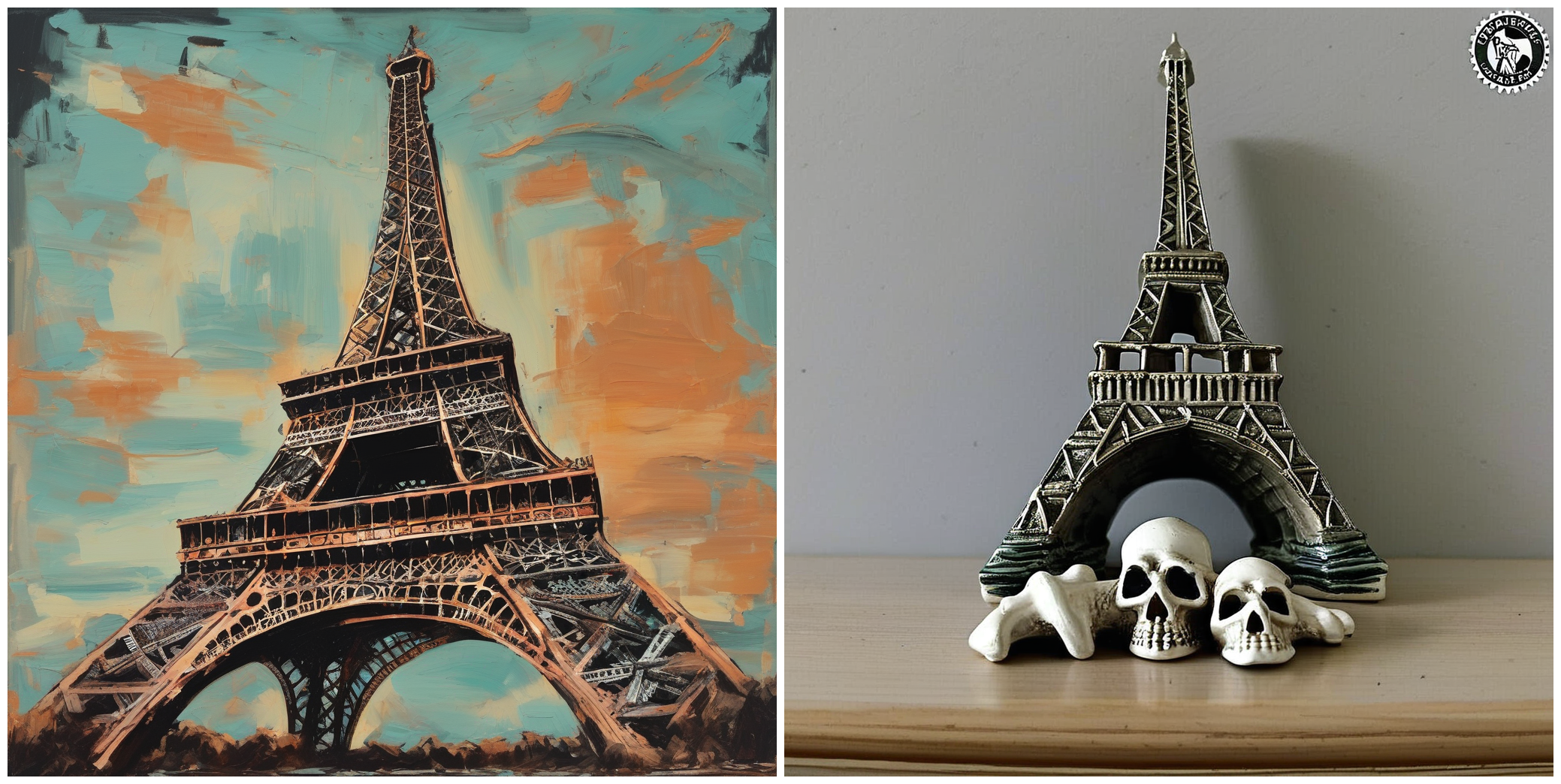
"A painting of the great pyramids in the style of <skull_lamp>."

"An oil painting of a skyscraper in the style of <skull_lamp>."

"The painting of a mug in the style of <skull_lamp>."



