SDFT
1.0.0
SDFT ist ein selbstbildendes Projekt, das darauf abzielt, die Hauptdiffusions-Feinabstimmungstechniken zu übersehen. Die Implementierung der stabilen Diffusion stammt aus der Huggingface -Diffusors -Bibliothek.
Techniken zur Übersicht:
Alle Feinabstimmentechniken wurden auf einem handgefertigten Spielzeugdatensatz mit dem Namen "Dark Fantasy" durchgeführt. Der Datensatz wurde unter Verwendung feinkörniger Eingabeaufforderungen mit dem stabilen Diffusion XL Base-1.0-Modell von Stabilityai gesammelt, um dunkel-fantasievolle Bilder in einem Stil zu erzeugen, der an die 1970er und 1980er Jahre erinnert. Ziel ist es zu demonstrieren, wie alle Techniken auf diesem Datensatz funktionieren.
Der Datensatz ist unter den datasets/ Verzeichnissen zu finden.
SDXL mit LORA zu optimieren:
accelerate launch train_lora_sdxl.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--allow_tf32
--mixed_precision= " fp16 "
--rank=32
--train_data_dir=datasets/dark_fantasy/
--caption_column= " text "
--dataloader_num_workers=16
--resolution=512
--use_center_crop
--use_random_flip
--train_batch_size=2
--gradient_accumulation_steps=4 --gradient_checkpointing
--max_train_steps=1500
--learning_rate=1e-04
--max_grad_norm=5
--lr_scheduler= " cosine_with_restarts "
--lr_warmup_steps=100
--output_dir=runs/lora_run/
--checkpointing_steps=100
--validation_epochs=10
--num_validation_images=4
--save_images_on_disk
--validation_prompt= " A picture of a misterious figure in cape, back view. "
--logging_dir= " logs "
--seed=1337Inferenz mit Lora Checkpoint durchführen:
accelerate launch run_lora_inference.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--output_dir=runs/lora_v1/
--lora_checkpoint_path=runs/lora_run/checkpoint-100/
--resolution=1024
--num_images_to_generate=5
--guidance_scale=5.0
--num_inference_steps=40
--prompt= " A picture of a misterious figure in cape, back view. "
--negative_prompt= " logo, watermark, text, blurry "
--seed=1337Kein Lora - Lora Images -Vergleich. Bilderpaare wurden unter Verwendung der gleichen Leitungen erzeugt.
"A picture of a heavy red Kenworth truck riding in the night across the abanoned city streets."

"A picture of a wounded orc warrior, climbing in misty mountains, front view, exhausted face, looking at the camera."

"A picture of space rocket launching, Earth on the background, candid photo."

"A picture of a supermassive black hole, devouring the galaxy, cinematic picture"

"A picture of a human woman warrior, black hair, looking at the camera, front view."

SDXL mit Textinversion (TI) zugunsten:
accelerate launch train_ti_sdxl.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--allow_tf32
--mixed_precision= " fp16 "
--train_data_dir=datasets/skull
--learnable_property= " style "
--placeholder_token= " <skull_lamp> "
--initializer_token= " skull "
--num_vectors=8
--resolution=1024
--repeats=1
--train_batch_size=2
--gradient_accumulation_steps=4 --gradient_checkpointing
--max_train_steps=5000
--learning_rate=3e-3
--lr_scheduler= " piecewise_constant "
--lr_warmup_steps=30
--output_dir= " runs/ti_run "
--validation_prompt= " A painting of Eiffel tower in the style of <skull_lamp> "
--num_validation_images=4
--validation_steps=100
--embeddings_save_steps=500
--save_images_on_disk
--use_random_flip
--use_center_crop
--seed=1337 Inferenz mit ausgebildeten Ti -Einbettungen durchführen:
accelerate launch run_ti_inference.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--output_dir=runs/ti_run
--path_to_embeddings=runs/ti_run/ti-embeddings-final.safetensors
--resolution=1024
--num_images_to_generate=1
--guidance_scale=5.0
--num_inference_steps=50
--placeholder_token= " <skull_lamp> "
--prompt= " A <skull_lamp>, made of lego "
--negative_prompt= " logo, watermark, text, blurry, bad quality "
--seed=1337Kein Ti -Ti -Bildervergleich. Bilderpaare wurden unter Verwendung der gleichen Leitungen erzeugt.
HINWEIS : Da Trainingsdatensatz nur aus 5 Bildern mit Standardunterschriften besteht, sind die Ergebnisse nicht so inspirierend, sondern die Einführung von feinmaschigeren Bildunterschriften würde es viel besser machen.
"A <skull_lamp>, made of lego."

"A painting of Eiffel tower in the style of <skull_lamp>."
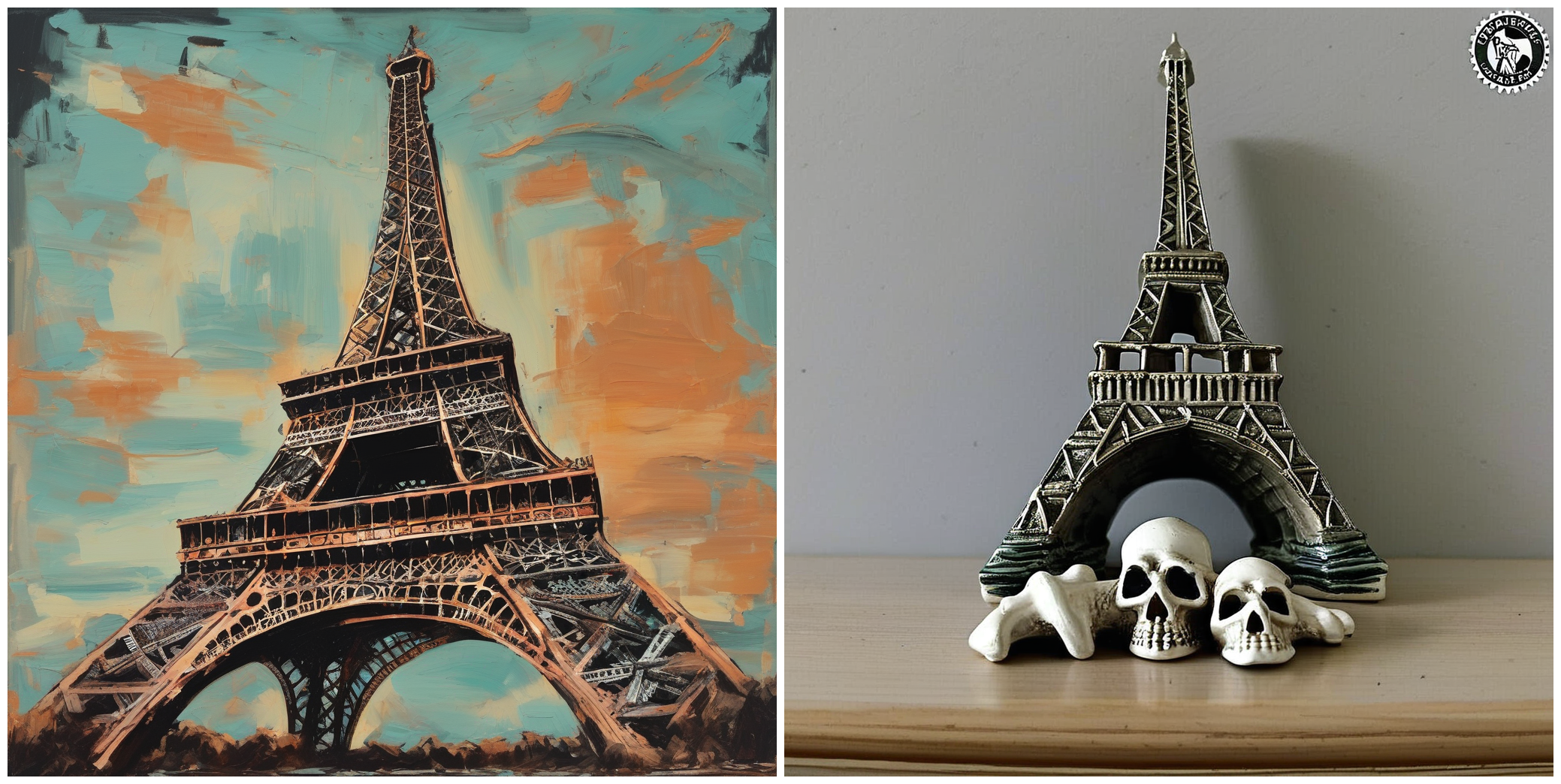
"A painting of the great pyramids in the style of <skull_lamp>."

"An oil painting of a skyscraper in the style of <skull_lamp>."

"The painting of a mug in the style of <skull_lamp>."



