SDFT
1.0.0
SDFTは、主な安定した拡散微調整技術を概要することを目的とした自己教育プロジェクトです。安定した拡散実装は、Huggingface Diffusers Libraryから取得されます。
概要のテクニック:
すべての微調整技術は、「Dark Fantasy」という名前の手作りのおもちゃデータセットで実行されました。データセットは、1970年代と1980年代を連想させるスタイルでダークファンタジーのような画像を生成するために、安定性拡散XL base-1.0モデルを使用して、安定した拡散XL base-1.0モデルを使用して収集されました。目標は、このデータセットで概説したすべての手法がどのように機能するかを示すことです。
データセットはdatasets/ディレクトリの下にあります。
sdxlをloraで微調整するには:
accelerate launch train_lora_sdxl.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--allow_tf32
--mixed_precision= " fp16 "
--rank=32
--train_data_dir=datasets/dark_fantasy/
--caption_column= " text "
--dataloader_num_workers=16
--resolution=512
--use_center_crop
--use_random_flip
--train_batch_size=2
--gradient_accumulation_steps=4 --gradient_checkpointing
--max_train_steps=1500
--learning_rate=1e-04
--max_grad_norm=5
--lr_scheduler= " cosine_with_restarts "
--lr_warmup_steps=100
--output_dir=runs/lora_run/
--checkpointing_steps=100
--validation_epochs=10
--num_validation_images=4
--save_images_on_disk
--validation_prompt= " A picture of a misterious figure in cape, back view. "
--logging_dir= " logs "
--seed=1337LORAチェックポイントで推論を実行するには:
accelerate launch run_lora_inference.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--output_dir=runs/lora_v1/
--lora_checkpoint_path=runs/lora_run/checkpoint-100/
--resolution=1024
--num_images_to_generate=5
--guidance_scale=5.0
--num_inference_steps=40
--prompt= " A picture of a misterious figure in cape, back view. "
--negative_prompt= " logo, watermark, text, blurry "
--seed=1337ロラなし-LORA画像の比較。同じ潜伏物を使用して、画像のペアが生成されました。
"A picture of a heavy red Kenworth truck riding in the night across the abanoned city streets."

"A picture of a wounded orc warrior, climbing in misty mountains, front view, exhausted face, looking at the camera."

"A picture of space rocket launching, Earth on the background, candid photo."

"A picture of a supermassive black hole, devouring the galaxy, cinematic picture"

"A picture of a human woman warrior, black hair, looking at the camera, front view."

テキストの反転(TI)でSDXLを微調整する:
accelerate launch train_ti_sdxl.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--allow_tf32
--mixed_precision= " fp16 "
--train_data_dir=datasets/skull
--learnable_property= " style "
--placeholder_token= " <skull_lamp> "
--initializer_token= " skull "
--num_vectors=8
--resolution=1024
--repeats=1
--train_batch_size=2
--gradient_accumulation_steps=4 --gradient_checkpointing
--max_train_steps=5000
--learning_rate=3e-3
--lr_scheduler= " piecewise_constant "
--lr_warmup_steps=30
--output_dir= " runs/ti_run "
--validation_prompt= " A painting of Eiffel tower in the style of <skull_lamp> "
--num_validation_images=4
--validation_steps=100
--embeddings_save_steps=500
--save_images_on_disk
--use_random_flip
--use_center_crop
--seed=1337 訓練されたTI埋め込みで推論を実行するには:
accelerate launch run_ti_inference.py
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix
--output_dir=runs/ti_run
--path_to_embeddings=runs/ti_run/ti-embeddings-final.safetensors
--resolution=1024
--num_images_to_generate=1
--guidance_scale=5.0
--num_inference_steps=50
--placeholder_token= " <skull_lamp> "
--prompt= " A <skull_lamp>, made of lego "
--negative_prompt= " logo, watermark, text, blurry, bad quality "
--seed=1337ti -ti画像の比較はありません。同じ潜伏物を使用して、画像のペアが生成されました。
注:トレーニングデータセットはデフォルトのキャプションを持つ5つの画像のみで構成されているため、結果はそれほど刺激的ではありませんが、より細かいキャプションを導入すると、それがはるかに良くなります。
"A <skull_lamp>, made of lego."

"A painting of Eiffel tower in the style of <skull_lamp>."
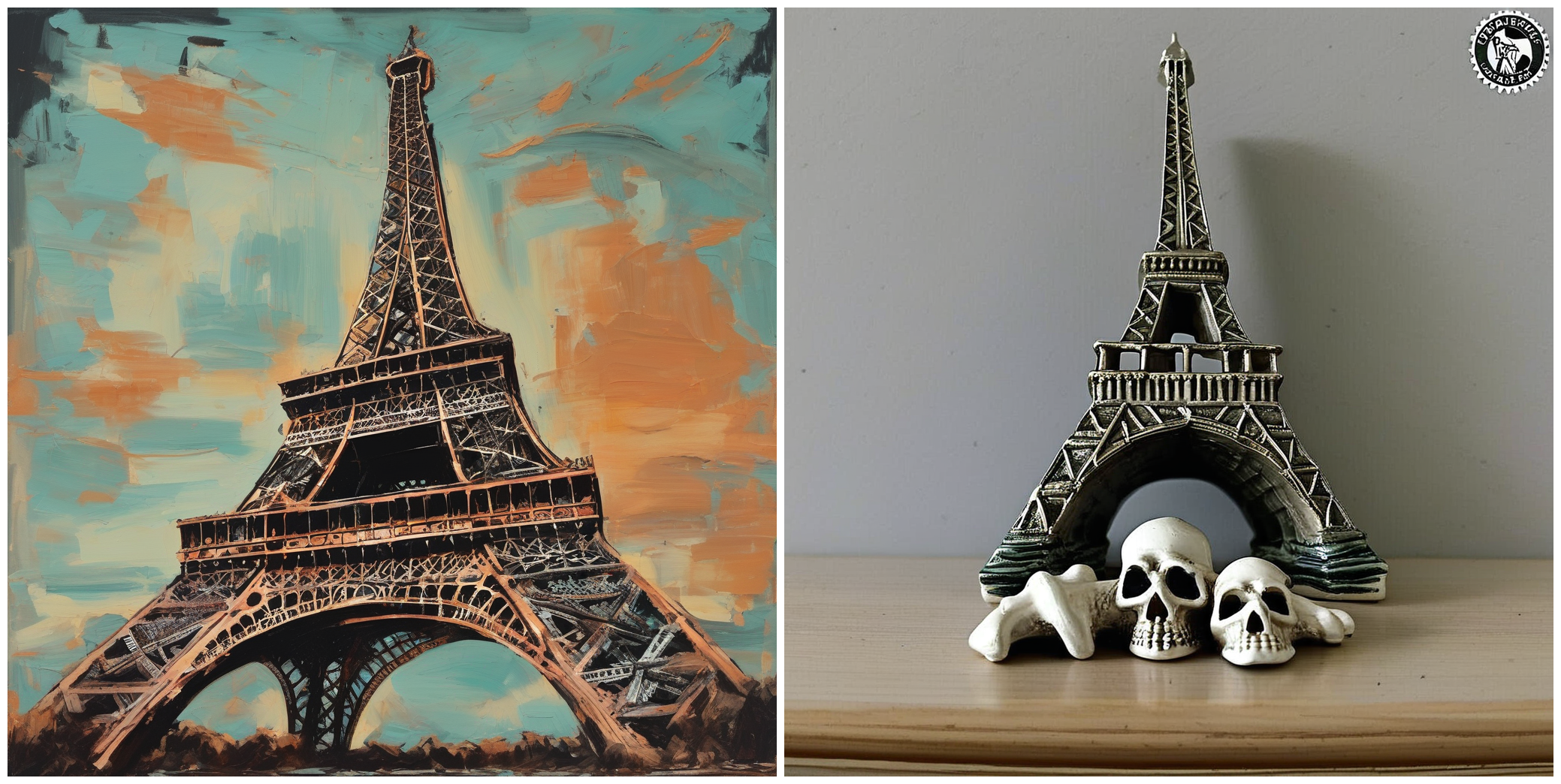
"A painting of the great pyramids in the style of <skull_lamp>."

"An oil painting of a skyscraper in the style of <skull_lamp>."

"The painting of a mug in the style of <skull_lamp>."



