Expressive FastSpeech2
1.0.0
Non-autoregressive Expressive TTS :이 프로젝트는 Emotional TTS 및 Conversational TTS 에 대한 미래의 연구 및 응용 프로그램을위한 초석을 제공하는 것을 목표로합니다. 데이터 세트의 경우 AIHUB 멀티 모달 비디오 AI 데이터 세트 및 IEMOCAP 데이터베이스가 각각 한국과 영어로 선택됩니다.
참고 : GST-Tacotron 또는 VAE-Tacotron과 같은 표현 스타일 TTS 모델에 관심이 있지만 비 유적지의 디코딩 하에서 스타일러 [데모, 코드]에 관심이있을 수 있습니다.
Annotated Data Processing :이 프로젝트는 다른 언어를 사용하여 새로운 데이터 세트를 처리하는 방법에 대해 밝히지 않습니다.
English and Korean TTS : 영어 외에도이 프로젝트는 언어 별 특징 (예 : 몬트리올 강제 정렬 기준 자신의 언어 및 데이터 세트에 따라 추가 데이터 처리를 고려해야하는 비 유포적 TTS에 대한 한국 치료에 대한 광범위한 견해를 제공합니다. text/ 를 자세히 살펴보십시오.
Adopting Own Language : 다른 언어를 조정하는 데 관심이있는 사람들은 범주 형 지점의 "자신의 데이터 세트 (자체 언어를 사용한 훈련”"섹션을 참조하십시오.
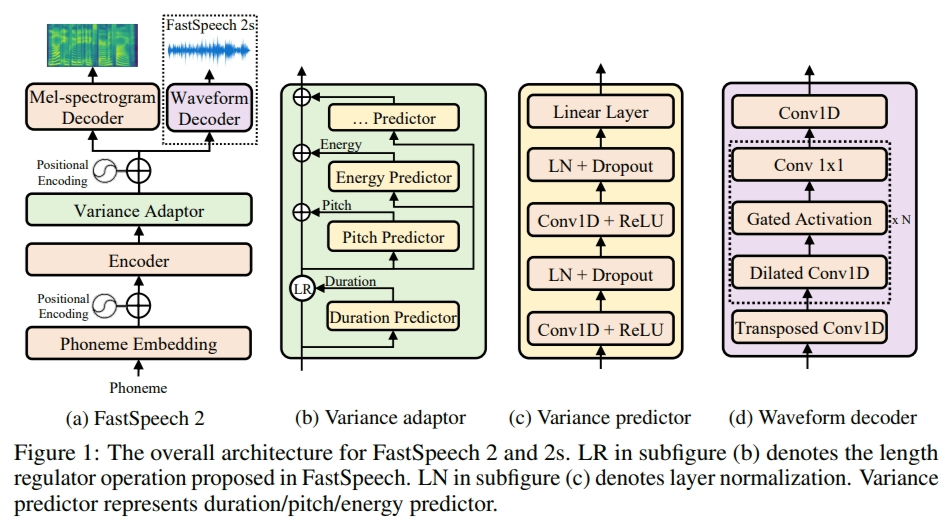
이 프로젝트에서 FastSpeech2는 기본이 아닌 사람들이 아닌 다중 스피커 TTS 프레임 워크로 조정되므로 먼저 용지와 코드를 읽는 것이 도움이됩니다 (FastSpeech2 지점 참조).
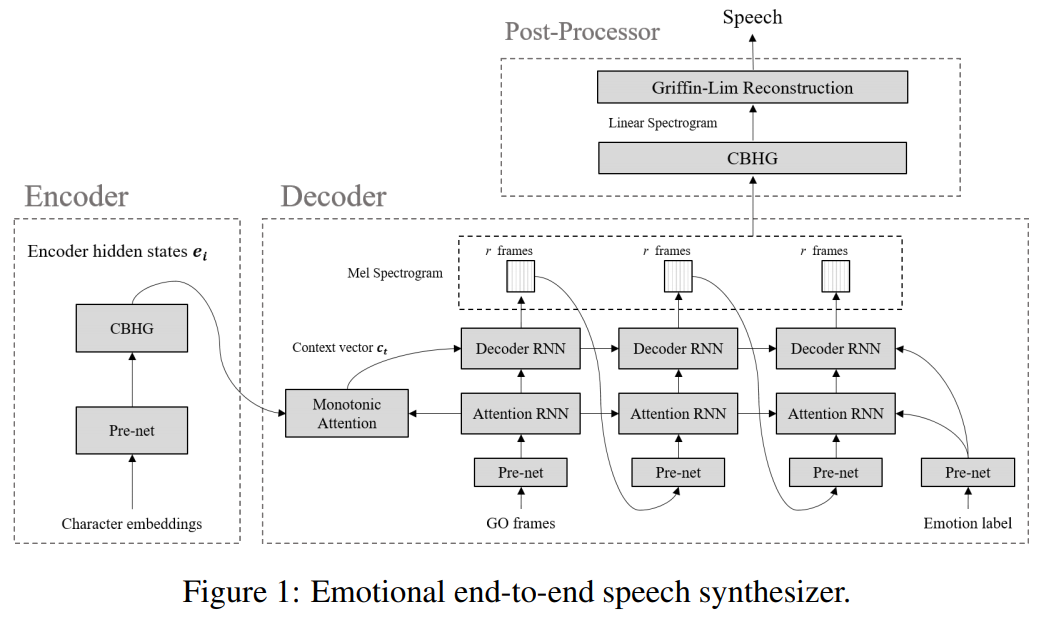
Emotional TTS : 다음 지점에는 감정적 인 종점 신경 연설 합성기에 의해 격리 된 기본 패러다임의 구현이 포함되어 있습니다.
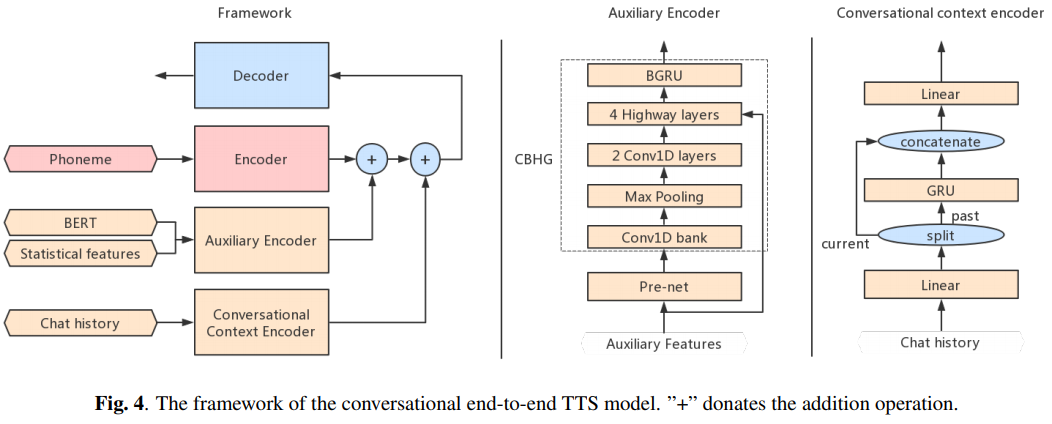
Conversational TTS : 다음 지점에 음성 에이전트를위한 대화 엔드 투 엔드 TTS 구현이 포함되어 있습니다.
이 구현을 사용하거나 참조하려면 Repo를 인용하십시오.
@misc{lee2021expressive_fastspeech2,
author = {Lee, Keon},
title = {Expressive-FastSpeech2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/keonlee9420/Expressive-FastSpeech2}}
}

