Expressive FastSpeech2
1.0.0
Non-autoregressive Expressive TTS : Proyek ini bertujuan untuk menyediakan landasan untuk penelitian dan aplikasi di masa depan pada TT ekspresif non-autoregresif termasuk Emotional TTS dan Conversational TTS . Untuk set data, AIHUB Multimodal Video AI Dataset dan database IEMOCAP masing -masing dipilih untuk Korea dan Inggris.
CATATAN : Jika Anda tertarik dengan GST-Tacotron atau VAE-Tacotron seperti model TTS gaya ekspresif tetapi di bawah decoding non-otegresif, Anda juga mungkin tertarik pada styler [demo, kode].
Annotated Data Processing : Proyek ini menjelaskan cara menangani dataset baru, bahkan dengan bahasa yang berbeda, untuk pelatihan keberhasilan TT emosional non-otomatis.
English and Korean TTS : Selain bahasa Inggris, proyek ini memberikan pandangan luas tentang memperlakukan Korea untuk TT non-otegresif di mana pemrosesan data tambahan harus dipertimbangkan di bawah fitur spesifik bahasa (misalnya, pelatihan Montreal memaksa pelurus dengan bahasa dan dataset Anda sendiri). Harap lihat dengan cermat text/ .
Adopting Own Language : Bagi mereka yang tertarik untuk mengadaptasi bahasa lain, silakan merujuk ke bagian "Pelatihan dengan Dataset Anda Sendiri (Bahasa Sendiri)" dari Cabang Kategori.
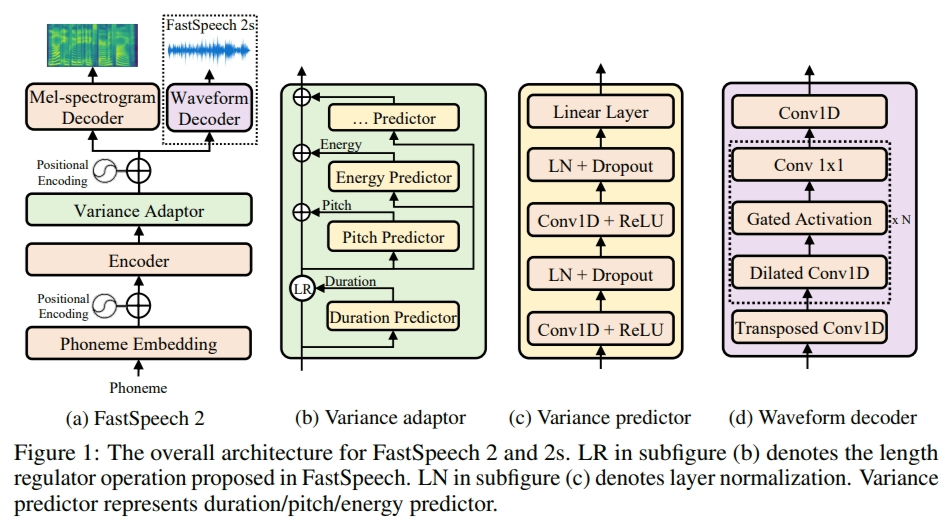
Dalam proyek ini, FastSpeech2 diadaptasi sebagai kerangka kerja TTS multi-speaker non-autoregresif, jadi akan sangat membantu membaca kertas dan kode terlebih dahulu (juga lihat cabang FastSpeech2).
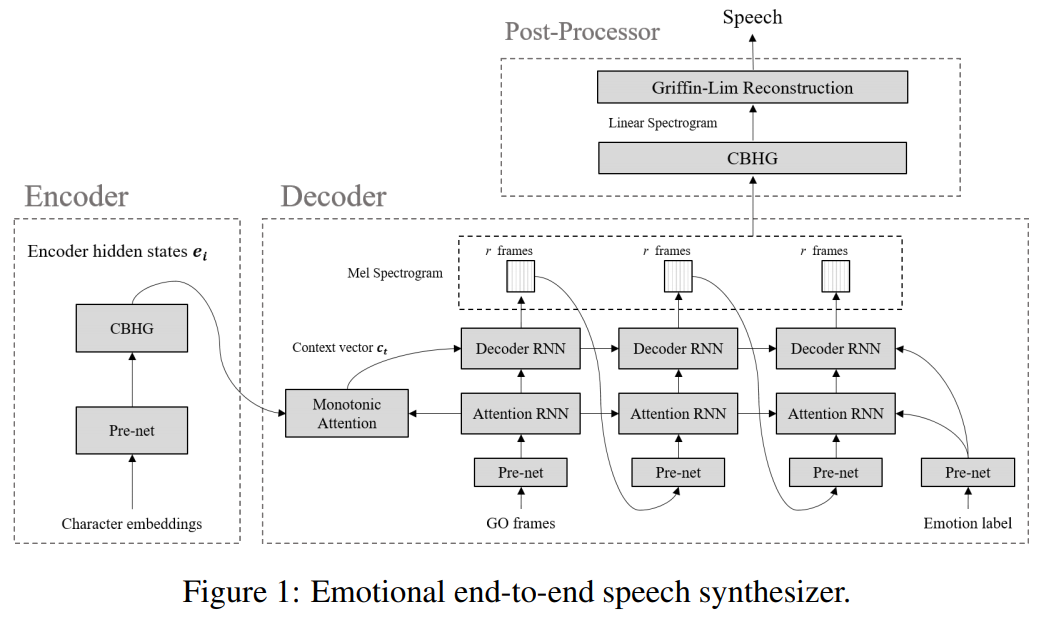
Emotional TTS : Cabang-cabang berikut berisi implementasi paradigma dasar yang tidak diselesaikan oleh synthesizer ucapan saraf end-to-end yang emosional.
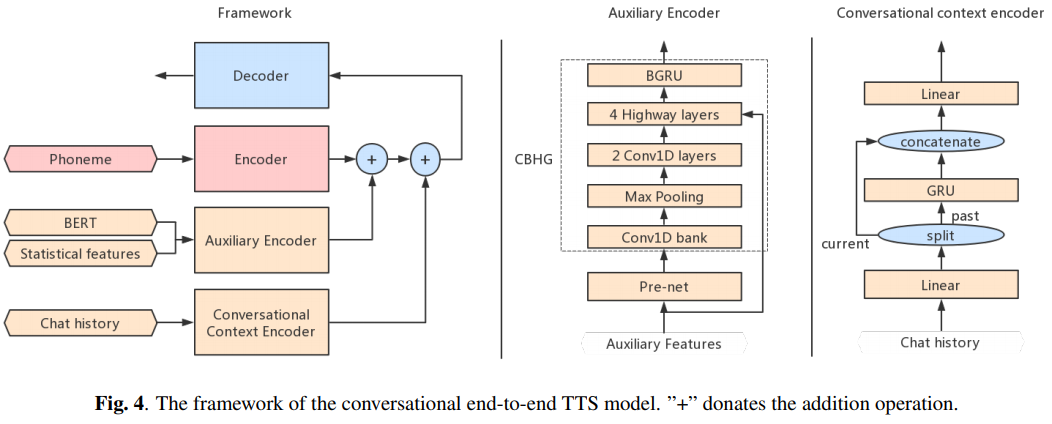
Conversational TTS : Cabang berikut berisi implementasi TTS end-to-end percakapan untuk agen suara
Jika Anda ingin menggunakan atau merujuk pada implementasi ini, silakan mengutip repo.
@misc{lee2021expressive_fastspeech2,
author = {Lee, Keon},
title = {Expressive-FastSpeech2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/keonlee9420/Expressive-FastSpeech2}}
}

