Expressive FastSpeech2
1.0.0
Non-autoregressive Expressive TTS :このプロジェクトはEmotional TTSやConversational TTSを含む非自動脱着表現TTSに関する将来の研究と応用の基礎を提供することを目的としています。データセットの場合、AIHUBマルチモーダルビデオAIデータセットとIEMOCAPデータベースは、それぞれ韓国語と英語用に選ばれます。
注:GST-TacotronまたはVae-Tacotronのような表現型のTTSモデルに興味があるが、非自動性のデコード下では、Styler [Demo、Code]にも興味があるかもしれません。
Annotated Data Processing :このプロジェクトは、非自動性感情的なTTSのトレーニングを成功させるために、異なる言語であっても、新しいデータセットを処理する方法に光を当てました。
English and Korean TTS :英語に加えて、このプロジェクトは、言語固有の機能の下で追加のデータ処理を考慮する必要がある非自動節約TTSの韓国語を扱う幅広い見解を提供します(例えば、モントリオールのトレーニングは、独自の言語とデータセットでアライナーを強制します)。 text/を詳しく調べてください。
Adopting Own Language :他の言語の適応に興味がある人のために、カテゴリブランチの「独自のデータセット(独自の言語)」セクションを参照してください。
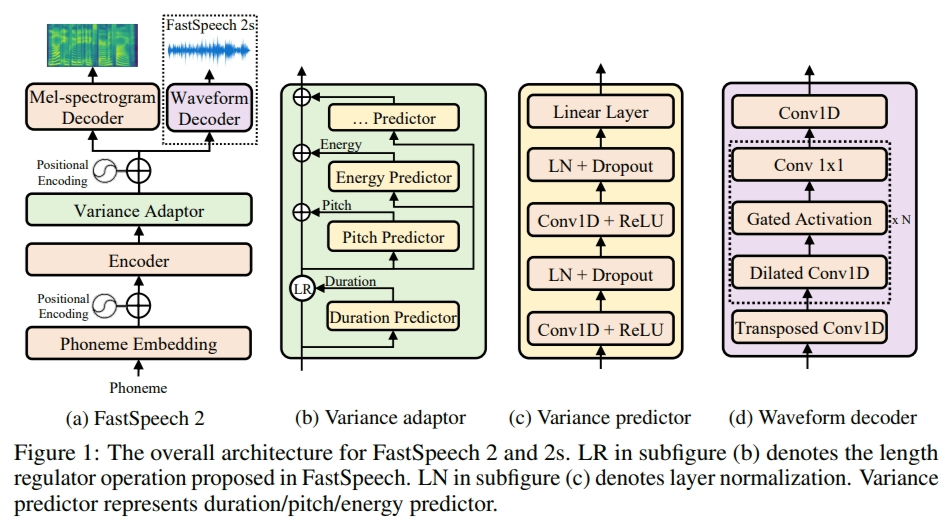
このプロジェクトでは、fastspeech2はベースの非自動網膜マルチスピーカーTTSフレームワークとして適合しているため、最初に論文とコードを読むと役立ちます(FastSpeech2ブランチも参照)。
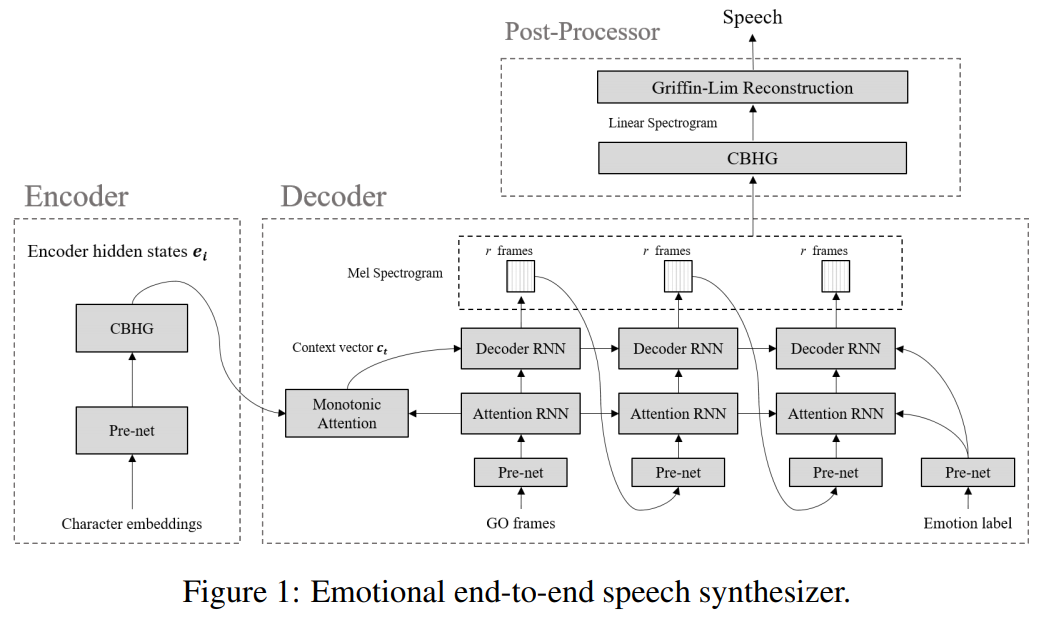
Emotional TTS :次の枝には、感情的なエンドツーエンドの神経発話シンセサイザーによって絡み合った基本的なパラダイムの実装が含まれています。
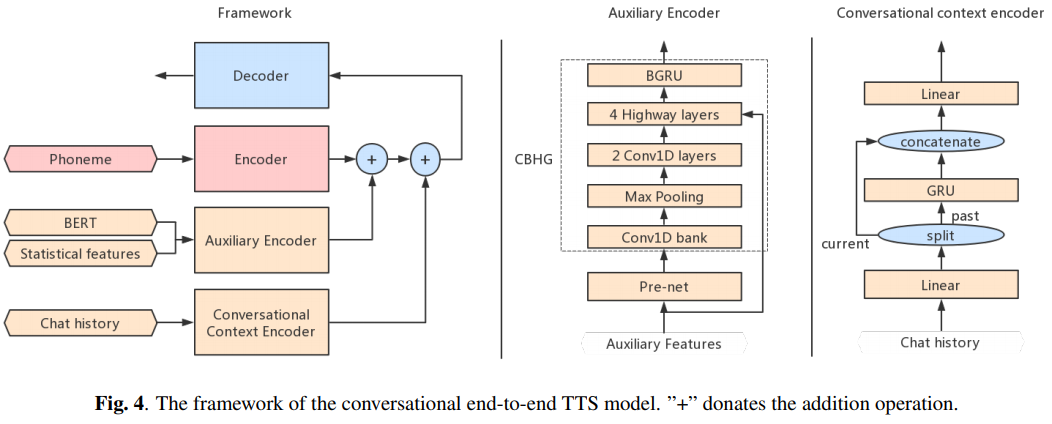
Conversational TTS :次のブランチには、音声エージェント用の会話型エンドツーエンドTTSの実装が含まれています
この実装を使用または参照したい場合は、リポジトリを引用してください。
@misc{lee2021expressive_fastspeech2,
author = {Lee, Keon},
title = {Expressive-FastSpeech2},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = { u rl{https://github.com/keonlee9420/Expressive-FastSpeech2}}
}

