vits2_pytorch
1.0.0
VITS2 용지의 비공식적 구현, VITS PAPER의 속편. (작가들에게 감사합니다!)
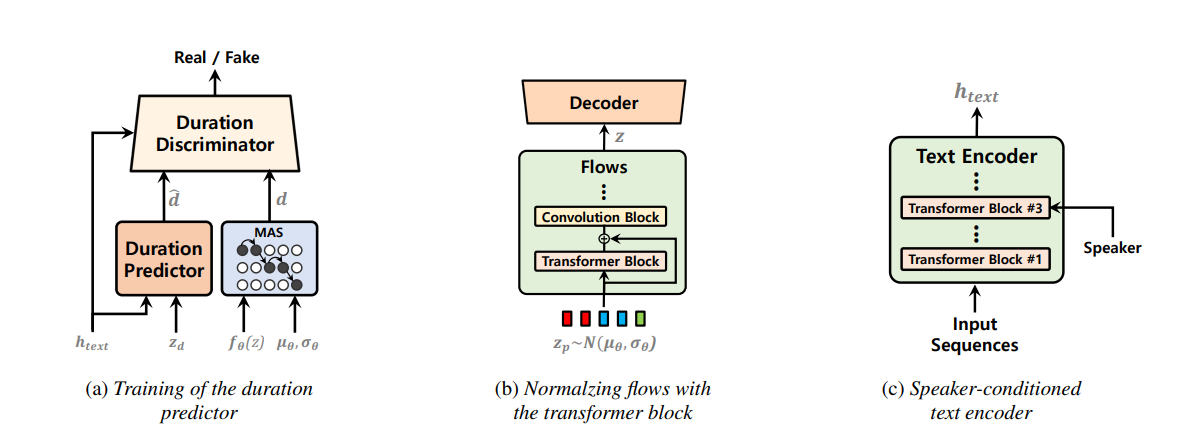
단일 단계 텍스트 음성 연설 모델은 최근에 적극적으로 연구되었으며 그 결과는 2 단계 파이프 라인 시스템을 능가했습니다. 이전의 단일 단계 모델은 큰 진전을 이루었지만 간헐적 인 부 자연성, 계산 효율 및 음소 전환에 대한 강력한 의존성 측면에서 개선의 여지가 있습니다. 이 작업에서, 우리는 이전 작업의 여러 측면을 개선하여보다 자연스러운 음성을 효율적으로 합성하는 단일 단계 텍스트 연설 모델 인 VITS2를 소개합니다. 우리는 개선 된 구조 및 훈련 메커니즘을 제안하고 제안 된 방법이 자연성을 향상시키는 데 효과적이며, 멀티 스피커 모델에서 언어 특성의 유사성, 훈련 및 추론의 효율성을 제시합니다. 또한, 우리는 이전 작품에서 음소 전환에 대한 강력한 의존성이 우리의 방법으로 크게 줄어들 수 있음을 보여줍니다.
apt-get install espeak 해야 할 수도 있습니다.ln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt import torch
from models import SynthesizerTrn
net_g = SynthesizerTrn (
n_vocab = 256 ,
spec_channels = 80 , # <--- vits2 parameter (changed from 513 to 80)
segment_size = 8192 ,
inter_channels = 192 ,
hidden_channels = 192 ,
filter_channels = 768 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
resblock = "1" ,
resblock_kernel_sizes = [ 3 , 7 , 11 ],
resblock_dilation_sizes = [[ 1 , 3 , 5 ], [ 1 , 3 , 5 ], [ 1 , 3 , 5 ]],
upsample_rates = [ 8 , 8 , 2 , 2 ],
upsample_initial_channel = 512 ,
upsample_kernel_sizes = [ 16 , 16 , 4 , 4 ],
n_speakers = 0 ,
gin_channels = 0 ,
use_sdp = True ,
use_transformer_flows = True , # <--- vits2 parameter
# (choose from "pre_conv", "fft", "mono_layer_inter_residual", "mono_layer_post_residual")
transformer_flow_type = "fft" , # <--- vits2 parameter
use_spk_conditioned_encoder = True , # <--- vits2 parameter
use_noise_scaled_mas = True , # <--- vits2 parameter
use_duration_discriminator = True , # <--- vits2 parameter
)
x = torch . LongTensor ([[ 1 , 2 , 3 ],[ 4 , 5 , 6 ]]) # token ids
x_lengths = torch . LongTensor ([ 3 , 2 ]) # token lengths
y = torch . randn ( 2 , 80 , 100 ) # mel spectrograms
y_lengths = torch . Tensor ([ 100 , 80 ]) # mel spectrogram lengths
net_g (
x = x ,
x_lengths = x_lengths ,
y = y ,
y_lengths = y_lengths ,
)
# calculate loss and backpropagate # LJ Speech
python train.py -c configs/vits2_ljs_nosdp.json -m ljs_base # no-sdp; (recommended)
python train.py -c configs/vits2_ljs_base.json -m ljs_base # with sdp;
# VCTK
python train_ms.py -c configs/vits2_vctk_base.json -m vctk_base
# for onnx export of trained models
python export_onnx.py --model-path= " G_64000.pth " --config-path= " config.json " --output= " vits2.onnx "
python infer_onnx.py --model= " vits2.onnx " --config-path= " config.json " --output-wav-path= " output.wav " --text= " hello world, how are you? " 

