vits2_pytorch
1.0.0
Inoffizielle Implementierung des Vits2 -Papiers, Fortsetzung von Vits Paper. (Danke an die Autoren für ihre Arbeit!)
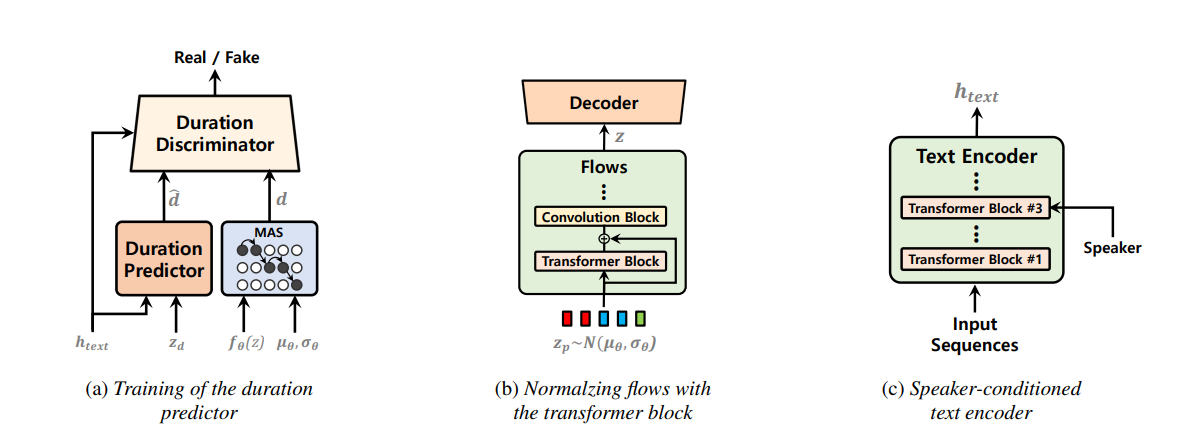
Einstufige Text-zu-Sprache-Modelle wurden in letzter Zeit aktiv untersucht, und ihre Ergebnisse haben zweistufige Pipeline-Systeme übertroffen. Obwohl das vorherige einstufige Modell große Fortschritte erzielt hat, gibt es in Bezug auf die zeitweilige Unnaturalität, die Recheneffizienz und die starke Abhängigkeit von der Phonemkonvertierung Verbesserung. In dieser Arbeit stellen wir Vits2 vor, ein einstufiges Text-zu-Sprach-Modell, das eine natürlichere Sprache effizient synthetisiert, indem sie verschiedene Aspekte der vorherigen Arbeiten verbessern. Wir schlagen verbesserte Strukturen und Trainingsmechanismen vor und präsentieren, dass die vorgeschlagenen Methoden die Natürlichkeit, die Ähnlichkeit der Sprachmerkmale in einem Modell mit mehreren Sprechern und die Effizienz von Training und Inferenz wirksam sind. Darüber hinaus zeigen wir, dass die starke Abhängigkeit von der Phonemumwandlung in früheren Arbeiten mit unserer Methode erheblich reduziert werden kann, was einen vollständig end-toend-einstufigen Ansatz ermöglicht.
apt-get install espeakln -s /path/to/LJSpeech-1.1/wavs DUMMY1ln -s /path/to/VCTK-Corpus/downsampled_wavs DUMMY2 Link zum Dataset -Ordner um oder erstellen # Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for LJ Speech and VCTK have been already provided.
# python preprocess.py --text_index 1 --filelists filelists/ljs_audio_text_train_filelist.txt filelists/ljs_audio_text_val_filelist.txt filelists/ljs_audio_text_test_filelist.txt
# python preprocess.py --text_index 2 --filelists filelists/vctk_audio_sid_text_train_filelist.txt filelists/vctk_audio_sid_text_val_filelist.txt filelists/vctk_audio_sid_text_test_filelist.txt import torch
from models import SynthesizerTrn
net_g = SynthesizerTrn (
n_vocab = 256 ,
spec_channels = 80 , # <--- vits2 parameter (changed from 513 to 80)
segment_size = 8192 ,
inter_channels = 192 ,
hidden_channels = 192 ,
filter_channels = 768 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
resblock = "1" ,
resblock_kernel_sizes = [ 3 , 7 , 11 ],
resblock_dilation_sizes = [[ 1 , 3 , 5 ], [ 1 , 3 , 5 ], [ 1 , 3 , 5 ]],
upsample_rates = [ 8 , 8 , 2 , 2 ],
upsample_initial_channel = 512 ,
upsample_kernel_sizes = [ 16 , 16 , 4 , 4 ],
n_speakers = 0 ,
gin_channels = 0 ,
use_sdp = True ,
use_transformer_flows = True , # <--- vits2 parameter
# (choose from "pre_conv", "fft", "mono_layer_inter_residual", "mono_layer_post_residual")
transformer_flow_type = "fft" , # <--- vits2 parameter
use_spk_conditioned_encoder = True , # <--- vits2 parameter
use_noise_scaled_mas = True , # <--- vits2 parameter
use_duration_discriminator = True , # <--- vits2 parameter
)
x = torch . LongTensor ([[ 1 , 2 , 3 ],[ 4 , 5 , 6 ]]) # token ids
x_lengths = torch . LongTensor ([ 3 , 2 ]) # token lengths
y = torch . randn ( 2 , 80 , 100 ) # mel spectrograms
y_lengths = torch . Tensor ([ 100 , 80 ]) # mel spectrogram lengths
net_g (
x = x ,
x_lengths = x_lengths ,
y = y ,
y_lengths = y_lengths ,
)
# calculate loss and backpropagate # LJ Speech
python train.py -c configs/vits2_ljs_nosdp.json -m ljs_base # no-sdp; (recommended)
python train.py -c configs/vits2_ljs_base.json -m ljs_base # with sdp;
# VCTK
python train_ms.py -c configs/vits2_vctk_base.json -m vctk_base
# for onnx export of trained models
python export_onnx.py --model-path= " G_64000.pth " --config-path= " config.json " --output= " vits2.onnx "
python infer_onnx.py --model= " vits2.onnx " --config-path= " config.json " --output-wav-path= " output.wav " --text= " hello world, how are you? " 

