VQLite
1.0.0
中文点这里
VQLITE는 Google 스캔을 기반으로 한 가볍고 간단한 벡터 유사성 검색 엔진입니다. VQLITE는 벡터 유사성 검색 서비스를 구축하기위한 간단한 편안한 API를 제공합니다.
우리 가이 프로젝트를 만들고있는 이유는 현재 우리의 요구를 충족시키는 솔루션이 없기 때문에 (다음 단락에 설명 된 바와 같이) 시장에서 사용할 수있는 벡터 검색 엔진이 너무 무겁기 때문에 종종 여러 복제본이있는 Kubernetes 클러스터가 필요하다고 생각합니다. 이것은 자원 낭비와 많은 프로젝트의 부담 일 수 있습니다.
일반적으로 사용되는 벡터 유사성 검색 엔진 (예 : Milvus, Qdrant, Vearch)은 벡터 치수에 의해 관리되며 벡터에서 작동합니다. 대조적으로, vqlite는 문서를 기반으로 데이터를 차원으로 처리합니다. 우리는 많은 경우 문서와 벡터 사이에 일대일 관계가 없으며 문서에 여러 벡터가있을 수있는 일대일 관계가 있음을 발견했습니다. 벡터를 기반으로 한 데이터를 관리하는 것은 번거롭고 여러 메타 데이터 사본을 저장할 때 자원이 낭비됩니다. 따라서 VQLITE의 디자인은 문서 당 여러 벡터를 허용하면서 MySQL 또는 Redis와 같은 추가 스토리지 솔루션에 의존하지 않고 메타 데이터를 저장할 수 있습니다.
이 프로젝트를 실제로 사용하려면 vqlite의 구조와 디자인을 이해하거나 VQLite를 자신의 요구에 맞게 수정하려면 Design.md를 읽는 것이 좋습니다.
물론 가장 중요한 측면은 검색 속도입니다. 따라서 우리는 현재 사용 가능한 가장 빠른 공개 벡터 유사성 검색 방법 일 수 있으므로 시스템의 핵심에서 Google 스캐를 사용합니다. 실제로, 우리는 단순히 스캐를 캡슐화합니다
다음 이미지는 스캔에서 나옵니다.
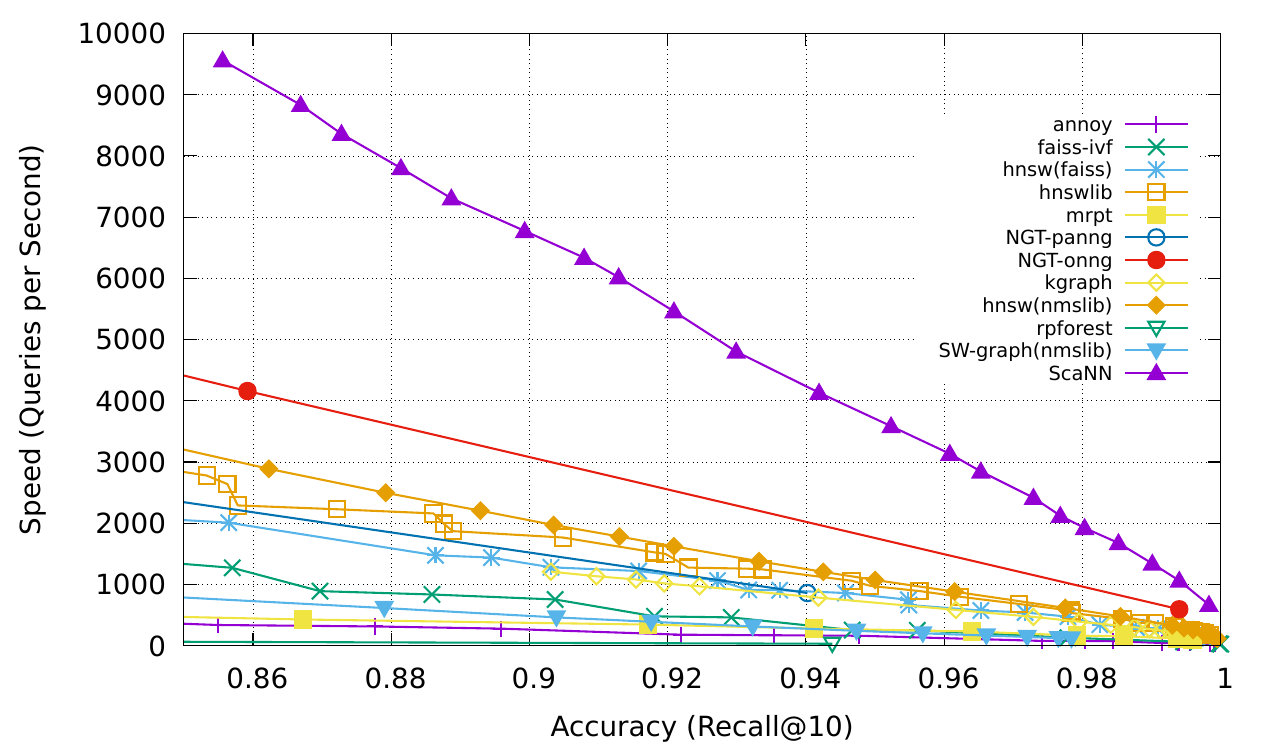
우리는 1,300 만 개의 벡터를 사용하여 AWS 기계에 데이터베이스를 구축했습니다. 아래는 테스트 결과입니다.
| 기계 | QPS | 매개 변수 (NPROBE, REARDER, TOPK) |
|---|---|---|
| C5.9xlarge | 7600 | 256,256,30 |
| C7G.8xlarge | 2900 | 256,256,30 |
| R5.8xlarge | 6900 | 256,256,30 |
소스 코드에서 컴파일하고 Docker를 사용하는 두 가지 방법을 사용합니다. Docker를 사용하는 것이 좋습니다.
git clone --recurse-submodules https://github.com/VQLite/VQLite.git
# git submodule update --remote --merge
cd vqindex
bash build.sh vqindex_api
cp bazel-bin/scann/scann_ops/cc/libvqlite_api.so /usr/local/lib/
cp bazel-bin//external/local_config_tf/libtensorflow_framework. * /usr/local/lib/
cd ..
go build cmd/vqlite.go먼저 vqlite.yaml을 컴퓨터에 복사하고 적절한 수정을하십시오.
docker pull ghcr.io/vqlite/vqlite:latest
docker run --restart=always -d --name vqlite -p 8880:8880
-v $( pwd ) /vqlite.yaml:/app/vqlite.yaml
-v $( pwd ) /vqlite_data:/app/vqlite_data
vqlite샘플 코드는 Python_SDK 디렉토리를 확인할 수 있습니다.


