VQLite
1.0.0
中文点这里
VQLiteは、Googleスキャンに基づいた軽量でシンプルなベクター類似性検索エンジンです。 VQLiteは、ベクトルの類似性検索サービスを構築するためのシンプルなRESTFUL APIを提供します。
このプロジェクトを作成している理由は、現在(次の段落で説明されているように)ニーズを満たすソリューションがないためです。また、市場で利用可能なベクター検索エンジンは重すぎて、複数のレプリカを備えたKubernetesクラスターを必要とすることが多いと感じています。これは、リソースの無駄であり、多くのプロジェクトの負担になる可能性があります。
一般的に使用されるベクトル類似性検索エンジン(Milvus、Qdrant、Vearchなど)は、ベクトル寸法によって管理され、ベクターで動作します。対照的に、VQLiteはドキュメントに基づいて寸法としてデータを処理します。多くの場合、ドキュメントとベクトルの間には1対1の関係があるのではなく、ドキュメントに複数のベクトルがある場合がある1対多の関係があることがわかりました。ベクトルのみに基づいたデータの管理は面倒であり、複数のメタデータコピーを保存する際に無駄なリソースをもたらす可能性があります。したがって、VQLiteの設計により、ドキュメントごとに複数のベクトルが可能になり、MySQLやRedisなどの追加のストレージソリューションに依存せずにメタデータを保存できます。
このプロジェクトを本当に使用したい場合は、VQLiteの構造と設計を理解する場合、またはVQLiteに変更を加えて自分のニーズに適応する場合は、Design.mdを読むことを強くお勧めします。
もちろん、最も重要な側面は検索速度です。したがって、現在最速のパブリックベクトル類似性検索方法である可能性があるため、システムのコアでGoogleのスキャンを使用しています。実際、私たちは単にスキャンをカプセル化します
次の画像は、スキャンから来ています。
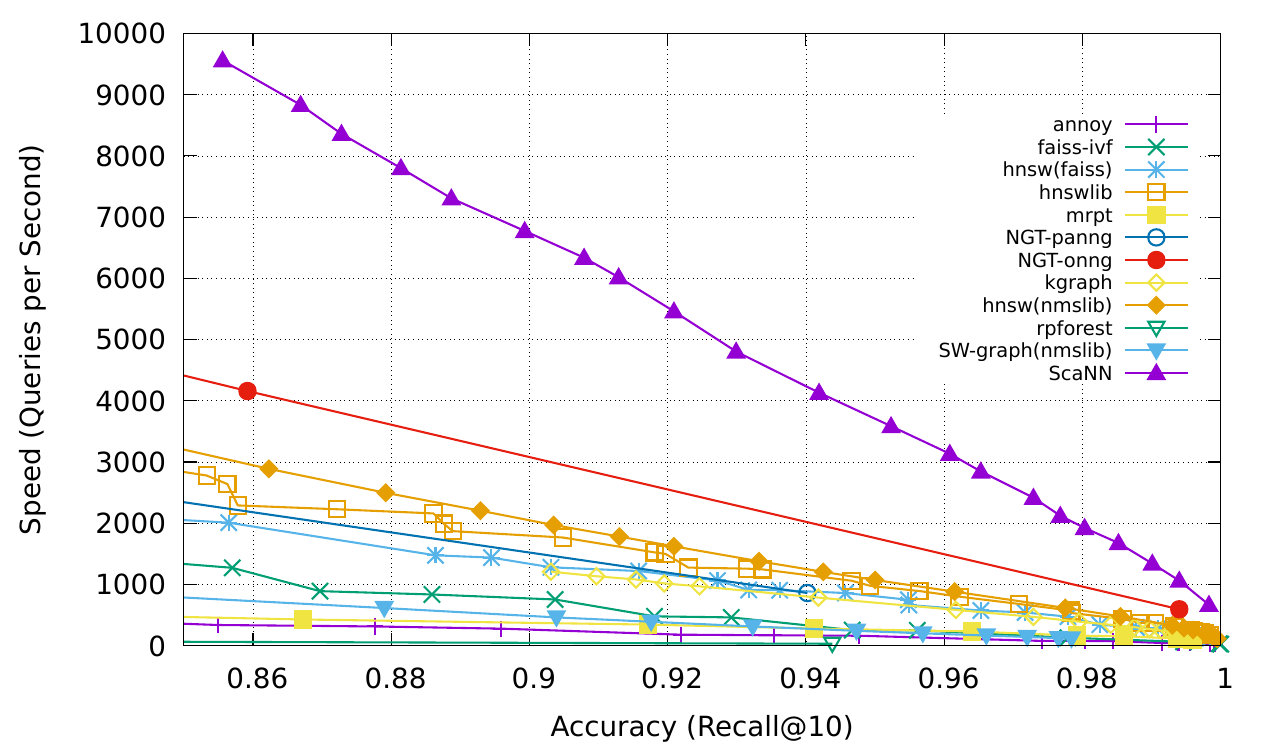
1300万個のベクターを使用して、AWSマシンにデータベースを構築しました。以下はテスト結果です。
| 機械 | QPS | Params(nprobe、Reorder、topk) |
|---|---|---|
| c5.9xlarge | 7600 | 256,256,30 |
| c7g.8xlarge | 2900 | 256,256,30 |
| r5.8xlarge | 6900 | 256,256,30 |
ソースコードからコンパイルし、Dockerを使用する2つの方法を使用します。 Dockerを使用することをお勧めします。
git clone --recurse-submodules https://github.com/VQLite/VQLite.git
# git submodule update --remote --merge
cd vqindex
bash build.sh vqindex_api
cp bazel-bin/scann/scann_ops/cc/libvqlite_api.so /usr/local/lib/
cp bazel-bin//external/local_config_tf/libtensorflow_framework. * /usr/local/lib/
cd ..
go build cmd/vqlite.goまず、vqlite.yamlをマシンにコピーして、適切な変更を加えます。
docker pull ghcr.io/vqlite/vqlite:latest
docker run --restart=always -d --name vqlite -p 8880:8880
-v $( pwd ) /vqlite.yaml:/app/vqlite.yaml
-v $( pwd ) /vqlite_data:/app/vqlite_data
vqliteサンプルコードについては、python_sdkディレクトリを確認できます。


