VQLite
1.0.0
中文点这里
VQLite es un motor de búsqueda de similitud vectorial ligero y simple basado en Google Scann. VQLITE proporciona una API relajante simple para la creación de servicios de búsqueda de similitud vectorial.
La razón por la que estamos creando este proyecto es que actualmente no hay una solución que satisfaga nuestras necesidades (como se describe en el siguiente párrafo), y creemos que los motores de búsqueda vectoriales disponibles en el mercado son demasiado pesados, a menudo requieren un clúster de Kubernetes con múltiples réplicas. Esto puede ser un desperdicio de recursos y una carga para muchos proyectos.
Los motores de búsqueda de similitud vectorial comúnmente utilizados (como Milvus, Qdrant, Vearch) se administran por dimensiones vectoriales y operan en vectores. En contraste, VQLite procesa datos basados en documentos como dimensiones. Descubrimos que en muchos casos, no existe una relación individual entre documentos y vectores, sino más bien una relación de uno a muchos donde un documento puede tener múltiples vectores. Administrar datos basados únicamente en vectores puede ser engorroso y dar como resultado recursos desperdiciados al almacenar múltiples copias de metadatos. Por lo tanto, el diseño de VQLite permite múltiples vectores por documento al tiempo que permite el almacenamiento de metadatos sin depender de soluciones de almacenamiento adicionales como MySQL o Redis.
Si realmente desea utilizar este proyecto, comprenda la estructura y el diseño de VQLite, o si desea hacer algunas modificaciones a VQLite para adaptarlo a sus propias necesidades, se recomienda encarecidamente que lea Design.md.
Por supuesto, el aspecto más importante es la velocidad de recuperación; Por lo tanto, utilizamos el escaneo de Google en el núcleo de nuestro sistema, ya que actualmente puede ser el método de búsqueda de similitud de vectores públicos más rápidos disponibles. De hecho, simplemente encapsulamos escaneo
La siguiente imagen proviene de Scann.
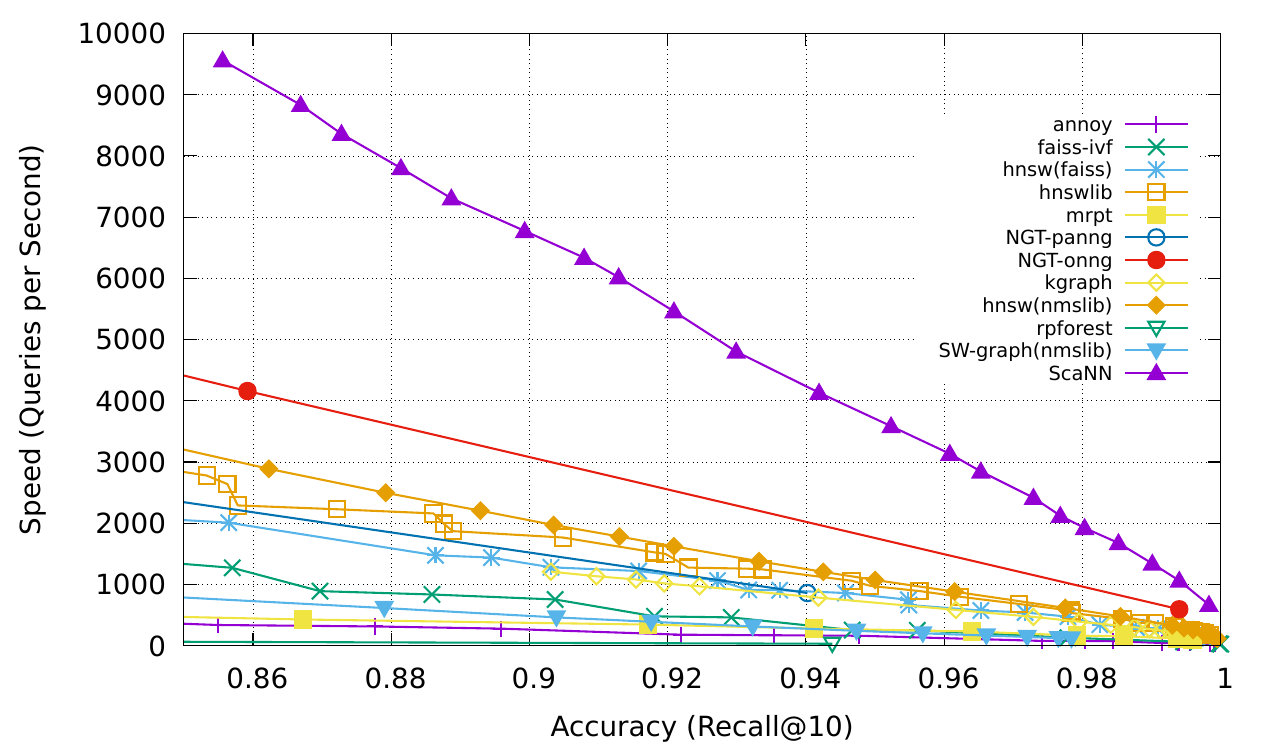
Utilizamos 13 millones de vectores para construir la base de datos en las máquinas AWS. A continuación se presentan los resultados de la prueba.
| Máquina | QPS | Params (nprobe, reordener, topk) |
|---|---|---|
| c5.9xLarge | 7600 | 256,256,30 |
| c7g.8xLarge | 2900 | 256,256,30 |
| R5.8XLARGE | 6900 | 256,256,30 |
Proporcionamos dos formas de usarlo, compilando el código fuente y el uso de Docker. Recomendamos usar el Docker.
git clone --recurse-submodules https://github.com/VQLite/VQLite.git
# git submodule update --remote --merge
cd vqindex
bash build.sh vqindex_api
cp bazel-bin/scann/scann_ops/cc/libvqlite_api.so /usr/local/lib/
cp bazel-bin//external/local_config_tf/libtensorflow_framework. * /usr/local/lib/
cd ..
go build cmd/vqlite.goPrimero, copie el vqlite.yaml a su máquina y haga modificaciones apropiadas.
docker pull ghcr.io/vqlite/vqlite:latest
docker run --restart=always -d --name vqlite -p 8880:8880
-v $( pwd ) /vqlite.yaml:/app/vqlite.yaml
-v $( pwd ) /vqlite_data:/app/vqlite_data
vqlitePuede verificar el directorio Python_SDK para el código de muestra.


