VQLite
1.0.0
中文点这里
VQLite est un moteur de recherche de similitude vectorielle léger et simple basé sur Google Scann. VQLite fournit une API reposante simple pour la construction de services de recherche de similitude vectorielle.
La raison pour laquelle nous créons ce projet est qu'il n'y a actuellement aucune solution qui répond à nos besoins (comme décrit dans le paragraphe suivant), et nous pensons que les moteurs de recherche vectoriels disponibles sur le marché sont trop lourds, nécessitant souvent un cluster Kubernetes avec plusieurs répliques. Cela peut être un gaspillage de ressources et un fardeau pour de nombreux projets.
Les moteurs de recherche de similitudes vectoriels couramment utilisés (tels que Milvus, Qdrant, Vearch) sont gérés par les dimensions vectorielles et fonctionnent sur des vecteurs. En revanche, VQLite traite les données basées sur des documents sous forme de dimensions. Nous avons constaté que dans de nombreux cas, il n'y a pas de relation un à un entre les documents et les vecteurs, mais plutôt une relation un-à-plusieurs où un document peut avoir plusieurs vecteurs. La gestion des données basées uniquement sur les vecteurs peut être lourde et entraîner des ressources gaspillées lors du stockage de plusieurs copies de métadonnées. Par conséquent, la conception de VQLite permet plusieurs vecteurs par document tout en permettant le stockage de métadonnées sans s'appuyer sur des solutions de stockage supplémentaires telles que MySQL ou Redis.
Si vous souhaitez vraiment utiliser ce projet, comprenez la structure et la conception de VQLite, ou si vous souhaitez apporter des modifications à VQLite pour l'adapter à vos propres besoins, il est fortement recommandé de lire Design.md.
Bien sûr, l'aspect le plus important est la vitesse de récupération; Par conséquent, nous utilisons Scan de Google au cœur de notre système, car il peut actuellement être la méthode de recherche de similitude des vecteurs publics le plus rapide disponible. En fait, nous encapsulons simplement scann
L'image suivante vient de Scann.
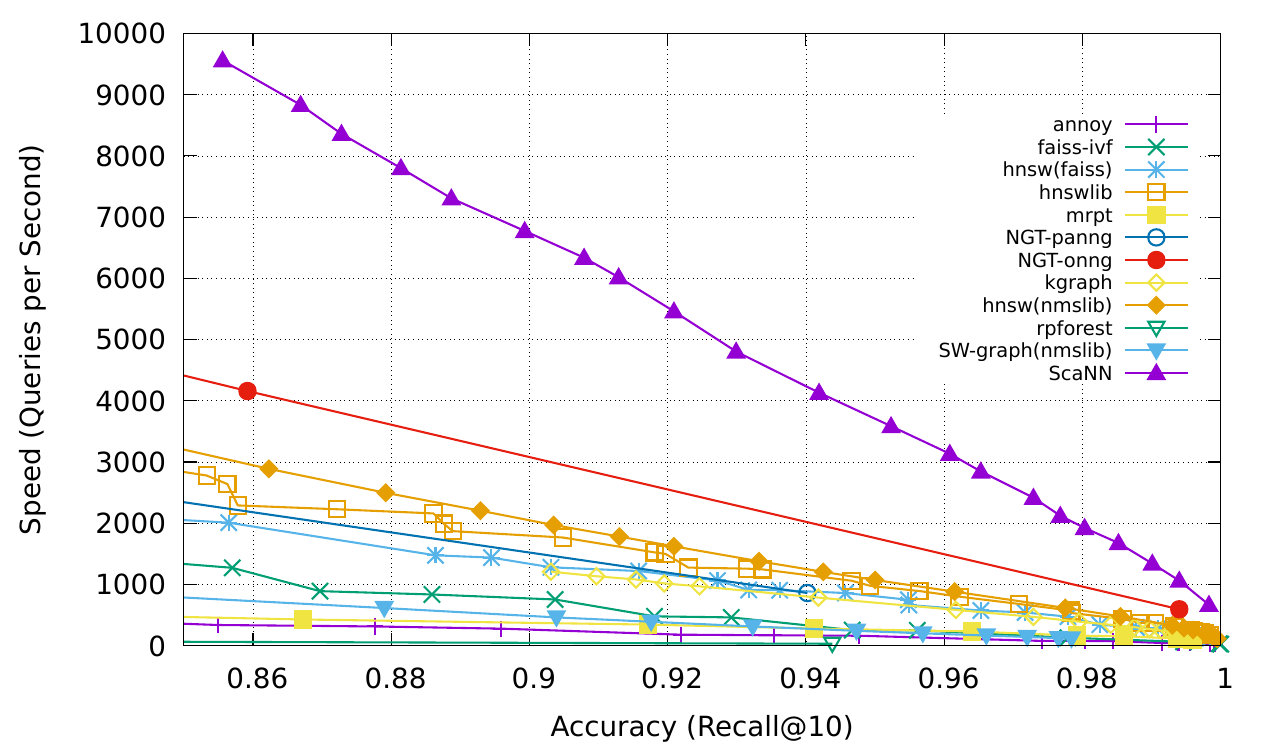
Nous avons utilisé 13 millions de vecteurs pour construire la base de données sur les machines AWS. Vous trouverez ci-dessous les résultats des tests.
| Machine | QPS | Params (nprobe, réorganisation, topk) |
|---|---|---|
| C5.9xlarge | 7600 | 256 156,30 |
| C7G.8xlARGE | 2900 | 256 156,30 |
| R5.8xlARGE | 6900 | 256 156,30 |
Nous fournissons deux façons de l'utiliser, de compiler à partir du code source et d'utiliser Docker. Nous vous recommandons d'utiliser le Docker.
git clone --recurse-submodules https://github.com/VQLite/VQLite.git
# git submodule update --remote --merge
cd vqindex
bash build.sh vqindex_api
cp bazel-bin/scann/scann_ops/cc/libvqlite_api.so /usr/local/lib/
cp bazel-bin//external/local_config_tf/libtensorflow_framework. * /usr/local/lib/
cd ..
go build cmd/vqlite.goTout d'abord, copiez le vqlite.yaml sur votre machine et apportez des modifications appropriées.
docker pull ghcr.io/vqlite/vqlite:latest
docker run --restart=always -d --name vqlite -p 8880:8880
-v $( pwd ) /vqlite.yaml:/app/vqlite.yaml
-v $( pwd ) /vqlite_data:/app/vqlite_data
vqliteVous pouvez vérifier le répertoire Python_SDK pour un exemple de code.


