TextGAN PyTorch
1.0.0
TextGan은 일반 텍스트 생성 모델 및 카테고리 텍스트 생성 모델을 포함하여 GANS (Generative Adversarial Networks) 기반 텍스트 생성 모델을위한 Pytorch 프레임 워크입니다. Textgan은 GAN 기반 텍스트 생성 모델에 대한 연구를 지원하는 벤치마킹 플랫폼 역할을합니다. 대부분의 GAN 기반 텍스트 생성 모델은 TensorFlow에 의해 구현되므로 TextGan은 Pytorch에 익숙해지는 사람들이 텍스트 생성 필드에 더 빨리 들어가도록 도울 수 있습니다.
내 구현에서 실수를 찾으면 알려주십시오! 또한 다른 모델을 추가하려면이 저장소에 자유롭게 기여하십시오.
설치하려면 pip install -r requirements.txt 실행하십시오. CUDA 문제의 경우 공식 Pytorch Get Start Guide에 문의하십시오.
안정적인 릴리스 및 unzip : http://kheafield.com/code/kenlm.tar.gz를 다운로드하십시오
부스트> = 1.42.0 및 bjam이 필요합니다
sudo apt-get install libboost-all-devbrew install boost; brew install bjamKenlm Directory 내에서 실행 :
mkdir -p build
cd build
cmake ..
make -j 4 pip install https://github.com/kpu/kenlm/archive/master.zip
Kenlm에 대한 자세한 내용은 https://github.com/kpu/kenlm 및 http://kheafield.com/code/kenlm/을 참조하십시오.
git clone https://github.com/williamSYSU/TextGAN-PyTorch.git
cd TextGAN-PyTorchImage COCO , EMNLP NEWs , Movie Review , Amazon Review )를 여기에서 다운로드 할 수 있습니다. cd run
python3 run_[model_name].py 0 0 # The first 0 is job_id, the second 0 is gpu_id
# For example
python3 run_seqgan.py 0 0강사
각 모델에 대해 전체 러닝 프로세스는 instructor/oracle_data/seqgan_instructor.py 에 정의됩니다. (예 : 합성 데이터 실험에서 Seqgan을 가져 가십시오). init_model() 및 optimize() 와 같은 일부 기본 기능은 instructor.py 의 기본 클래스 BasicInstructor 에 정의됩니다. 새로운 GAN 기반 텍스트 생성 모델을 추가하려면 instructor/oracle_data 아래에 새로운 강사를 만들고 모델의 교육 프로세스를 정의하십시오.
심상
utils/visualization.py 사용하여 모델 손실 및 메트릭스 점수를 포함하여 로그 파일을 시각화하십시오. len(color_list) 에 지나지 않는 log_file_list 에서 로그 파일을 사용자 정의하십시오. 로그 파일 이름은 .txt 제외해야합니다.
벌채 반출
Textgan-Pytorch는 Python의 logging 모듈을 사용하여 Generator의 손실 및 메트릭 점수와 같은 실행 프로세스를 기록합니다. 시각화의 편의를 위해 log/log_****_****.txt 및 save/**/log.txt . 또한이 코드는 모델의 상태 표시와 발전기 샘플의 배치 크기를 ./save/**/models 및 로그 단계 당 ./save/**/samples ** 자동으로 저장합니다.
실행되는 신호
사전 파일 run_signal.txt 기반으로 클래스 Signal ( utils/helpers.py 참조)로 교육 프로세스를 쉽게 제어 할 수 있습니다.
Signal 사용하려면 로컬 파일 run_signal.txt 편집하고 예를 들어 pre_sig Fasle 로 설정하면 프로그램이 사전 훈련 프로세스를 중지하고 다음 교육 단계로 나아갑니다. 현재 훈련이 충분하다고 생각되면 조기 훈련을 중단하는 것이 편리합니다.
Automatiaclly 선택 GPU
config.py 에서이 프로그램은 nvidia-smi 에서 최소 GPU-Util 갖는 GPU 장치를 자동으로 선택합니다. 이 기능은 기본적으로 활성화됩니다. GPU 장치를 수동으로 선택하려면 run_[run_model].py 의 --device args를 무책임하고 명령으로 GPU 장치를 지정하십시오.
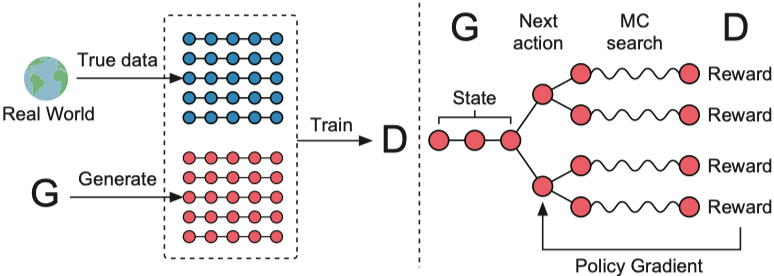
런 파일 : run_seqgan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (Seqgan에서)
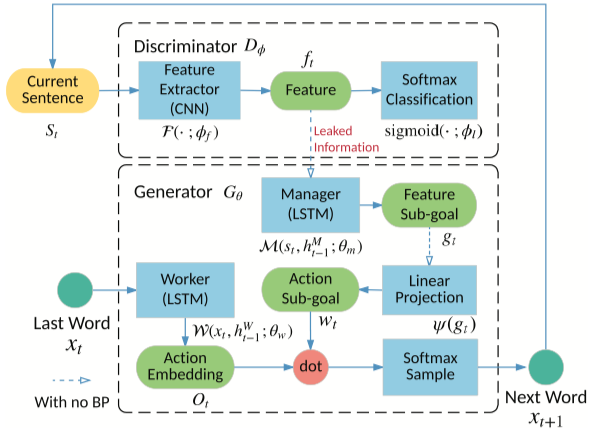
런 파일 : run_leakgan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (Leakgan에서)
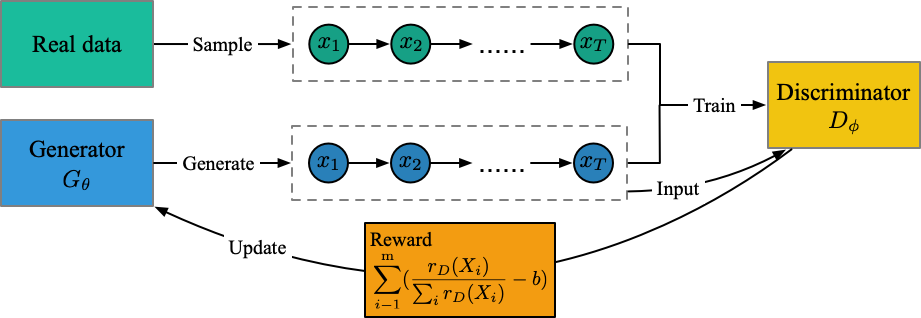
런 파일 : run_maligan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (내 이해로부터)
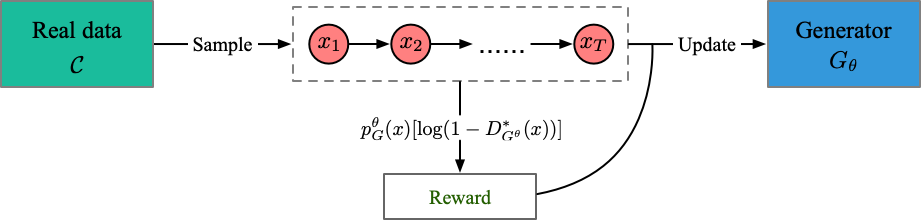
런 파일 : run_jsdgan.py
강사 : oracle_data, real_data
모델 : 발전기 (차별기 없음)
구조 (내 이해로부터)
런 파일 : run_relgan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (내 이해로부터)
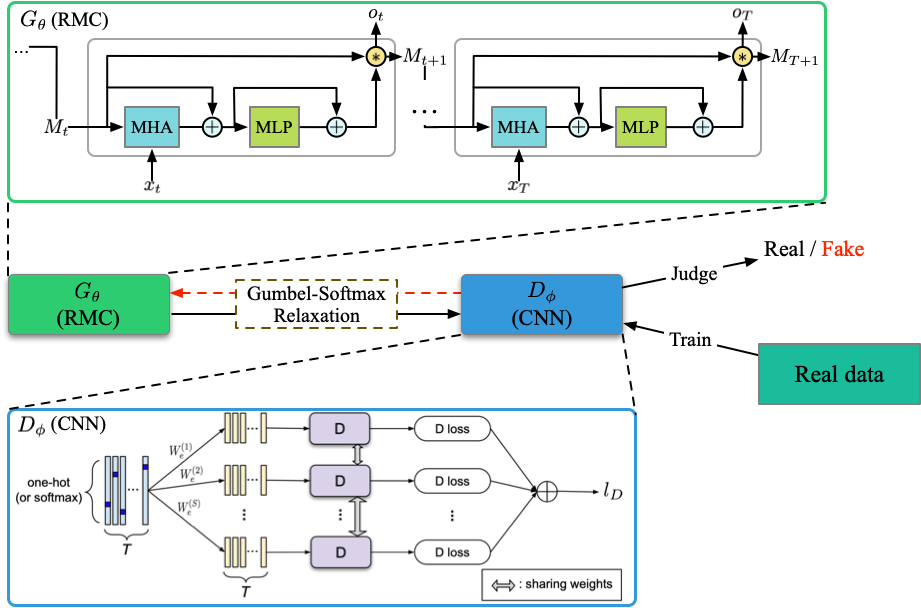
런 파일 : run_dpgan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (DPGAN)
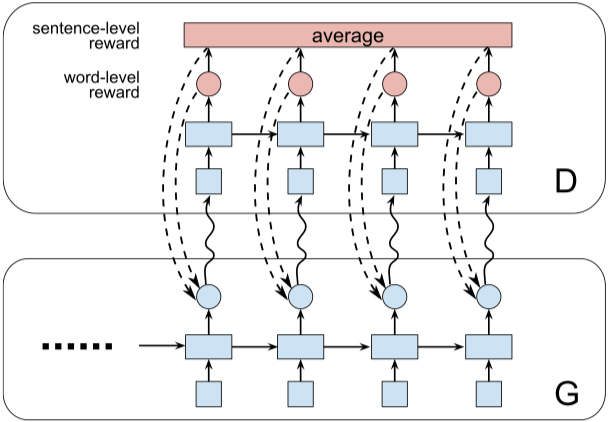
런 파일 : run_dgsan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
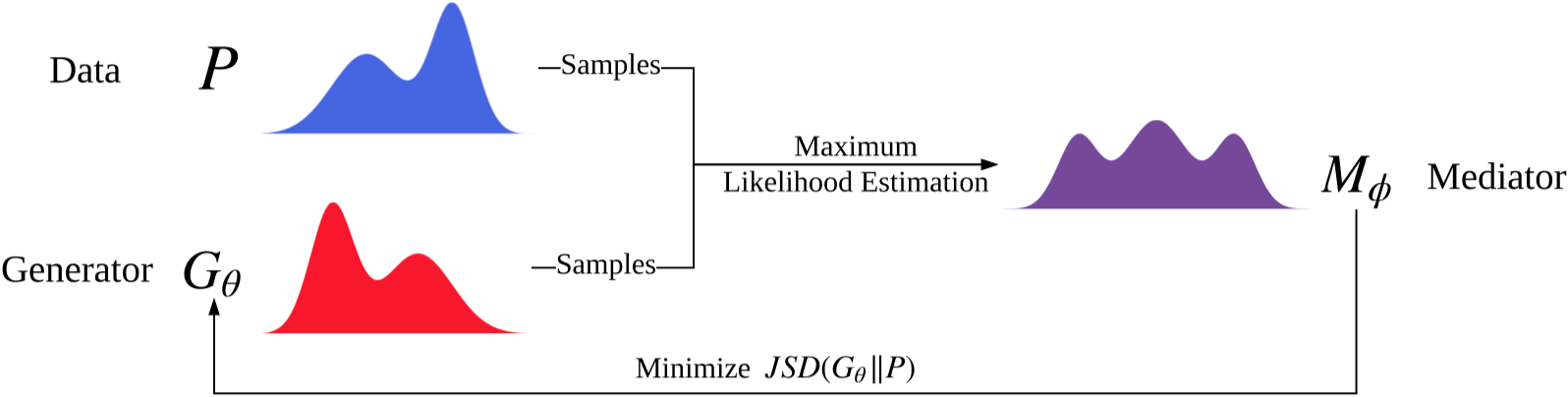
런 파일 : run_cot.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (COT에서)
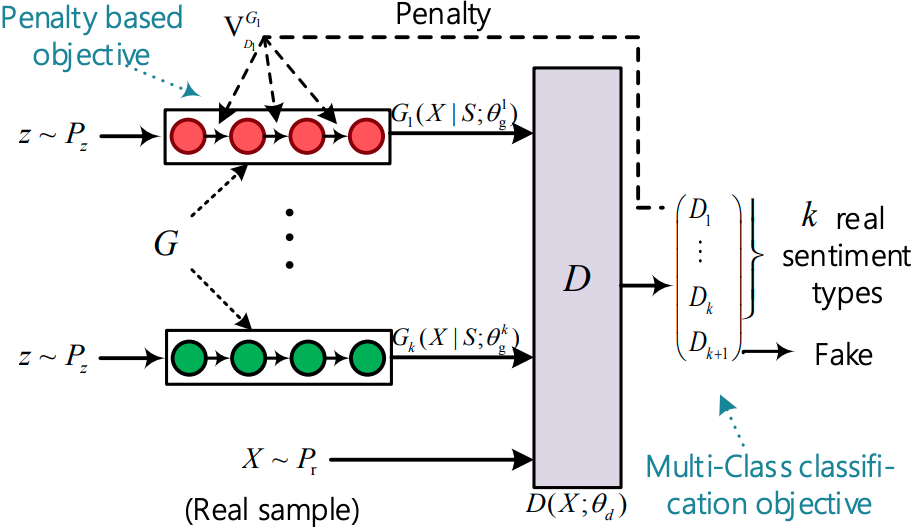
파일 런 : run_sentigan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (Sentigan에서)
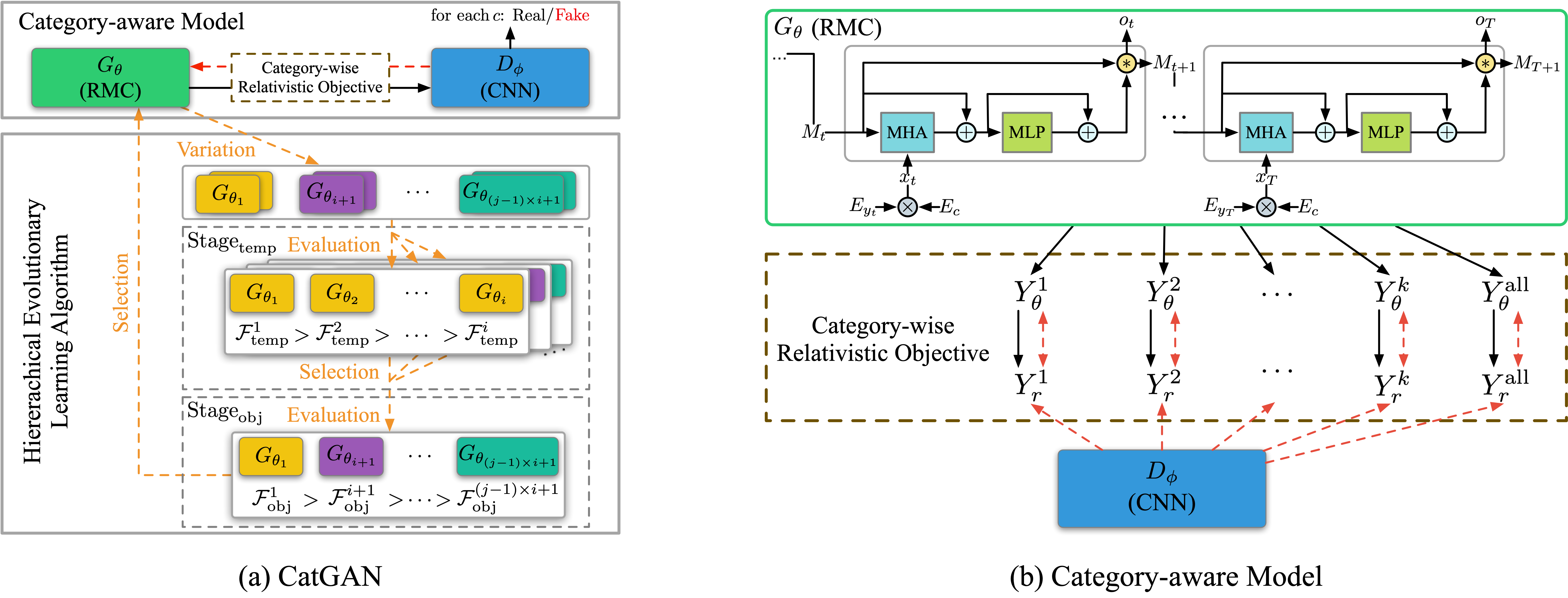
런 파일 : run_catgan.py
강사 : oracle_data, real_data
모델 : 발전기, 판별 자
구조 (Catgan에서)
Lincens


