TextGAN PyTorch
1.0.0
Textgan est un cadre Pytorch pour les modèles de génération de réseaux adversariaux génératifs (GANS), y compris des modèles généraux de génération de texte et des modèles de génération de texte de catégorie. Textgan sert de plate-forme d'analyse comparative pour soutenir la recherche sur les modèles de génération de texte basés sur GAN. Étant donné que la plupart des modèles de génération de texte basés sur GAN sont implémentés par TensorFlow, Textgan peut aider ceux qui s'habituent à Pytorch pour entrer plus rapidement dans le champ de génération de texte.
Si vous trouvez une erreur dans ma mise en œuvre, faites-le moi savoir! N'hésitez également pas à contribuer à ce référentiel si vous souhaitez ajouter d'autres modèles.
Pour installer, exécutez pip install -r requirements.txt . En cas de problèmes CUDA, consultez le guide officiel de démarrage de Pytorch.
Télécharger la version stable et unzip: http://kheafield.com/code/kenlm.tar.gz
Besoin de boost> = 1.42.0 et bjam
sudo apt-get install libboost-all-devbrew install boost; brew install bjamExécutez dans le répertoire Kenlm:
mkdir -p build
cd build
cmake ..
make -j 4 pip install https://github.com/kpu/kenlm/archive/master.zip
Pour plus d'informations sur Kenlm, voir: https://github.com/kpu/kenlm et http://kheafield.com/code/kenlm/
git clone https://github.com/williamSYSU/TextGAN-PyTorch.git
cd TextGAN-PyTorchImage COCO , EMNLP NEWs , Movie Review , Amazon Review ) peuvent être téléchargés à partir d'ici. cd run
python3 run_[model_name].py 0 0 # The first 0 is job_id, the second 0 is gpu_id
# For example
python3 run_seqgan.py 0 0Instructeur
Pour chaque modèle, l'ensemble du processus de course est défini dans instructor/oracle_data/seqgan_instructor.py . (Prenez SEQGAN dans l'expérience de données synthétiques par exemple). Certaines fonctions de base comme init_model() et optimize() sont définies dans la classe de base BasicInstructor dans instructor.py . Si vous souhaitez ajouter un nouveau modèle de génération de texte basé sur Gan, veuillez créer un nouvel instructeur sous instructor/oracle_data et définir le processus de formation du modèle.
Visualisation
Utilisez utils/visualization.py pour visualiser le fichier journal, y compris les scores de perte de modèle et de métriques. Custo vos fichiers journaux dans log_file_list , pas plus que len(color_list) . Le nom de fichier du journal doit exclure .txt .
Enregistrement
Le TextGan-Pytorch utilise le module logging dans Python pour enregistrer le processus en cours d'exécution, comme la perte du générateur et les scores métriques. Pour la commodité de la visualisation, il y aurait deux même fichiers journaux enregistrés dans log/log_****_****.txt et save/**/log.txt respectivement. En outre, le code économiserait automatiquement le dict d'état des modèles et un lot des échantillons du générateur dans ./save/**/models et ./save/**/samples par étape de journal, où ** dépend de vos hyper-paramètres.
Signal de course
Vous pouvez facilement contrôler le processus de formation avec le Signal de classe (veuillez vous référer à utils/helpers.py ) en fonction du fichier de dictionnaire run_signal.txt .
Pour utiliser le Signal , modifiez simplement le fichier local run_signal.txt et définissez pre_sig sur Fasle , par exemple, le programme arrêtera le processus de pré-formation et entrera dans la prochaine phase de formation. Il est pratique d'arrêter tôt la formation si vous pensez que la formation actuelle est suffisante.
Sélectionnez automatiquement GPU
Dans config.py , le programme sélectionnerait automatiquement un périphérique GPU avec le moins GPU-Util dans nvidia-smi . Cette fonction est activée par défaut. Si vous souhaitez sélectionner manuellement un périphérique GPU, veuillez décommenter les args --device dans run_[run_model].py et spécifier un périphérique GPU avec commande.
Fichier d'exécution: run_seqgan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de Seqgan)
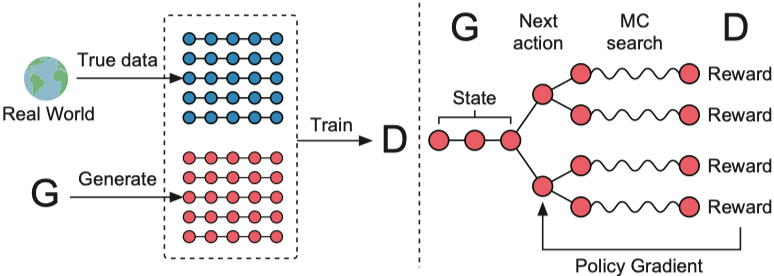
Fichier d'exécution: run_leakgan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de Leakgan)
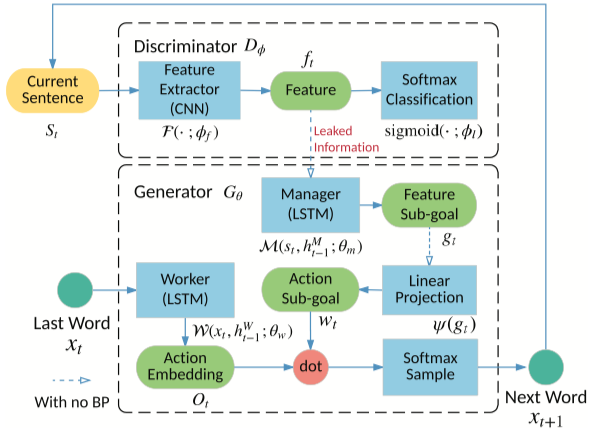
Fichier d'exécution: run_maligan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de ma compréhension)
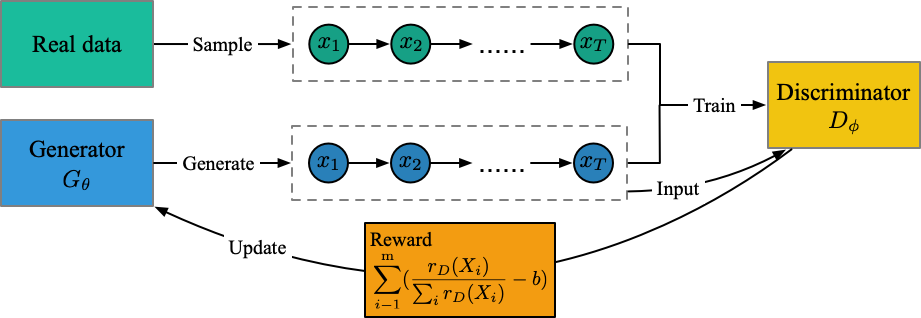
Fichier d'exécution: run_jsdgan.py
Instructeurs: Oracle_data, Real_data
Modèles: Générateur (pas de discriminateur)
Structure (de ma compréhension)
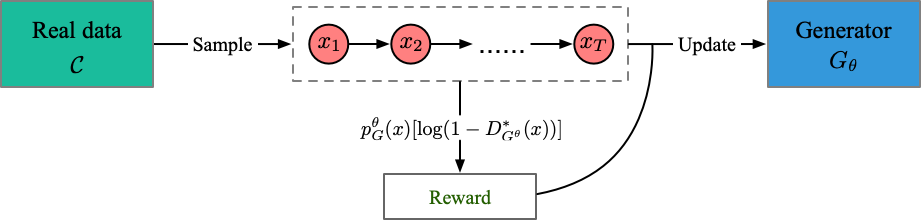
Fichier d'exécution: run_relgan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de ma compréhension)
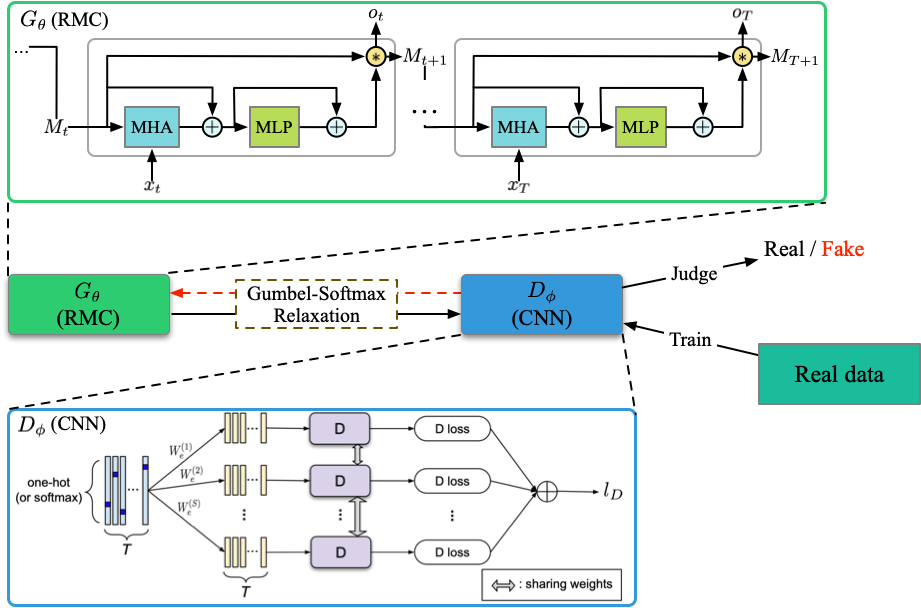
Fichier d'exécution: run_dpgan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de DPGAN)
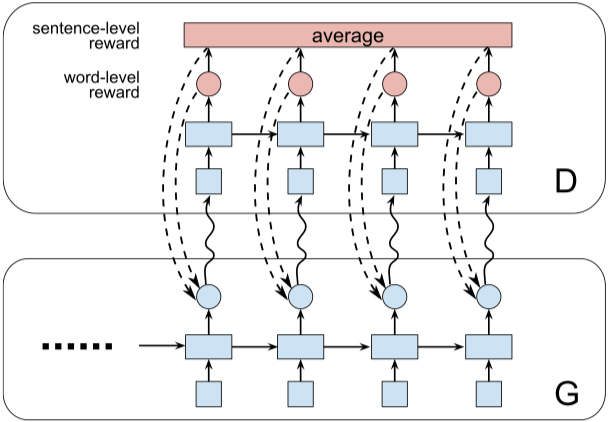
Fichier d'exécution: run_dgsan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
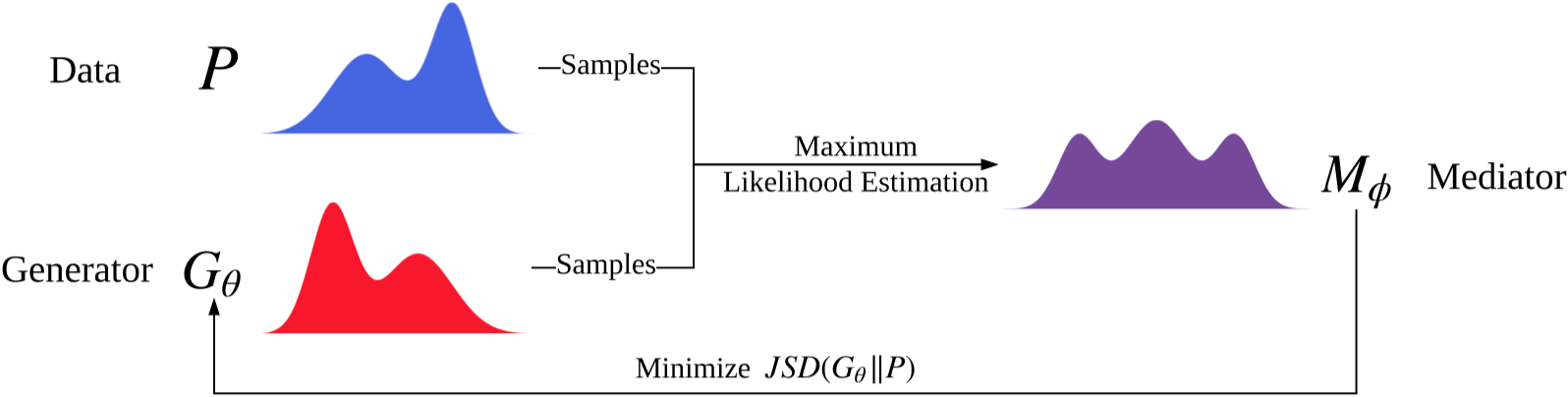
Fichier d'exécution: run_cot.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (à partir de COT)
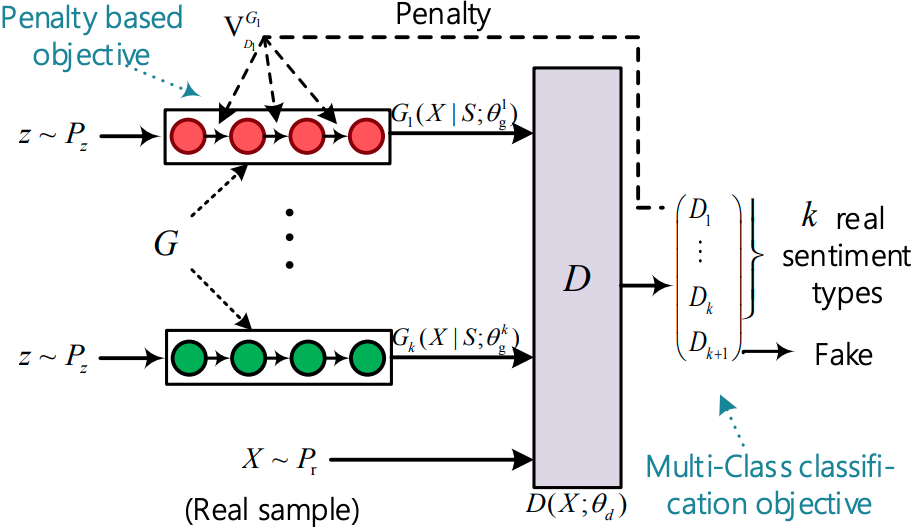
Fichier d'exécution: run_sentigan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de Sentigan)
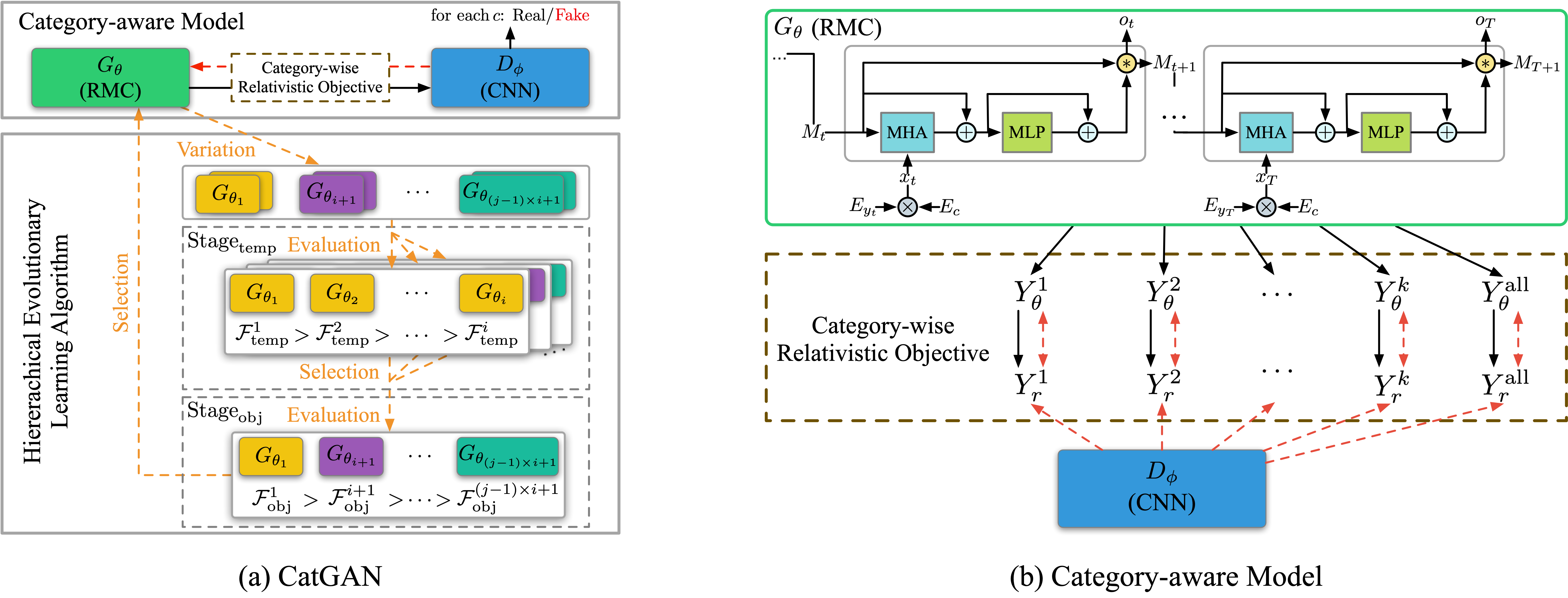
Fichier d'exécution: run_catgan.py
Instructeurs: Oracle_data, Real_data
Modèles: générateur, discriminateur
Structure (de Catgan)
MIT Lcence


