TextGAN PyTorch
1.0.0
Textgan ist ein Pytorch -Framework für generative kontroverse Netzwerke (GANS) -basierte Textgenerierungsmodelle, einschließlich allgemeiner Textgenerierungsmodelle und Kategorie -Textgenerierungsmodelle. Textgan dient als Benchmarking-Plattform, um die Forschung zu GAN-basierten Textgenerierungsmodellen zu unterstützen. Da die meisten GaN-basierten Textgenerierungsmodelle von TensorFlow implementiert werden, kann Textgan denjenigen helfen, die sich an Pytorch gewöhnen, um das Feld der Textgenerierung schneller einzugeben.
Wenn Sie einen Fehler in meiner Implementierung finden, lassen Sie es mich bitte wissen! Bitte zögern Sie nicht, zu diesem Repository beizutragen, wenn Sie andere Modelle hinzufügen möchten.
Ausführen von pip install -r requirements.txt ausführen.txt. Bei CUDA -Problemen wenden Sie sich an den offiziellen Pytorch -Get -Got -Leitfaden.
Download Stable Release und Unzip: http://kheapielfield.com/code/kenlm.tar.gz
Benötigen Boost> = 1.42.0 und Bjam
sudo apt-get install libboost-all-devbrew install boost; brew install bjamIm Kenlm -Verzeichnis laufen:
mkdir -p build
cd build
cmake ..
make -j 4 pip install https://github.com/kpu/kenlm/archive/master.zip
Weitere Informationen zu kenlm finden
git clone https://github.com/williamSYSU/TextGAN-PyTorch.git
cd TextGAN-PyTorchImage COCO , EMNLP NEWs , Movie Review , Amazon Review ) von hier heruntergeladen werden. cd run
python3 run_[model_name].py 0 0 # The first 0 is job_id, the second 0 is gpu_id
# For example
python3 run_seqgan.py 0 0Lehrer
Für jedes Modell ist der gesamte Runing -Prozess in instructor/oracle_data/seqgan_instructor.py definiert. (Nehmen Sie zum Beispiel Seqgan in synthetische Datenexperiment). Einige grundlegende Funktionen wie init_model() und optimize() werden in der Basisklasse BasicInstructor in instructor.py definiert. Wenn Sie ein neues GaN-basierter Textgenerierungsmodell hinzufügen möchten, erstellen Sie bitte einen neuen Ausbilder unter instructor/oracle_data und definieren Sie den Trainingsprozess für das Modell.
Visualisierung
Verwenden Sie utils/visualization.py , um die Protokolldatei zu visualisieren, einschließlich Modellverlust- und Metrik -Bewertungen. Stellen Sie Ihre Protokolldateien in log_file_list an, nicht mehr als len(color_list) . Der Protokolldateiname sollte .txt ausschließen.
Protokollierung
Der Textgan-Pytorch verwendet das logging in Python, um den Laufprozess wie den Verlust des Generators und die Metrikwerte aufzuzeichnen. Für die Bequemlichkeit der Visualisierung wird zwei gleiche Protokolldatei in log/log_****_****.txt und save/**/log.txt gespeichert. Darüber hinaus würde der Code automatisch das Statusdikte von Modellen und eine Batch-Größe der Muster des Generators in ./save/**/models und ./save/**/samples per log-Schritt speichern, wo ** von Ihren Hyper-Parametern abhängt.
Laufsignal
Sie können den Trainingsprozess einfach mit dem Signal (bitte unter utils/helpers.py ) basierend auf der Wörterbuchdatei run_signal.txt steuern.
Für die Verwendung des Signal bearbeiten Sie einfach die lokale Datei run_signal.txt und setzen Sie pre_sig beispielsweise auf Fasle ein. Das Programm stoppt den Vorauslaufprozess und tritt in die nächste Trainingsphase ein. Es ist bequem, das Training zu frühzeitig einzustellen, wenn Sie der Meinung sind, dass das aktuelle Training ausreicht.
Automatiaclly wählen Sie GPU
In config.py würde das Programm automatisch ein GPU-Gerät mit dem geringsten GPU-Util in nvidia-smi auswählen. Diese Funktion ist standardmäßig aktiviert. Wenn Sie ein GPU -Gerät manuell auswählen möchten, wenden Sie sich bitte an die Argumente von --device in run_[run_model].py und geben Sie ein GPU -Gerät mit dem Befehl an.
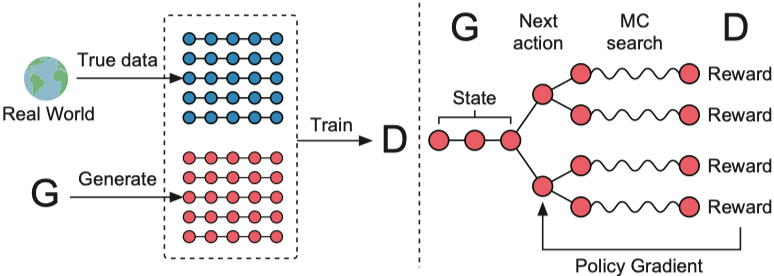
Ausführen von Datei: run_seqgan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (aus Seqgan)
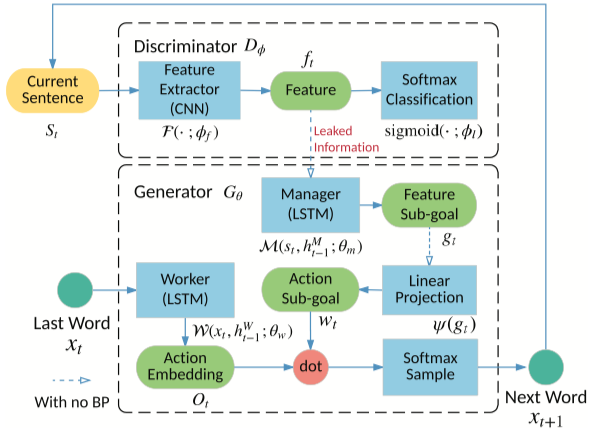
Datei ausführen: run_leakgan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (von Leakgan)
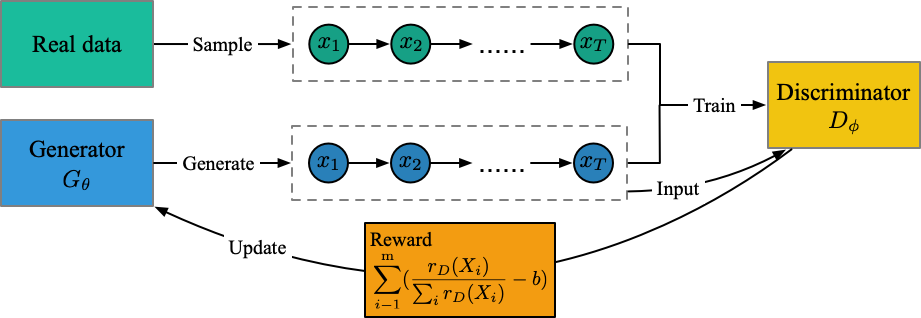
Ausführen von Datei: run_maligan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (aus meinem Verständnis)
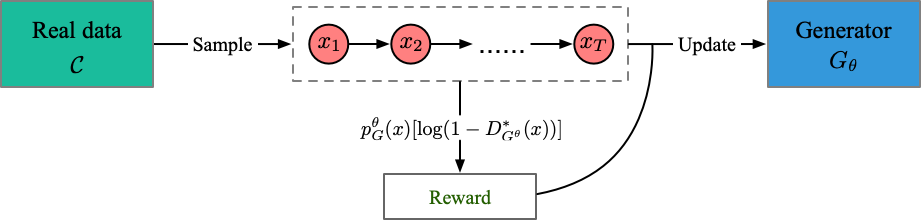
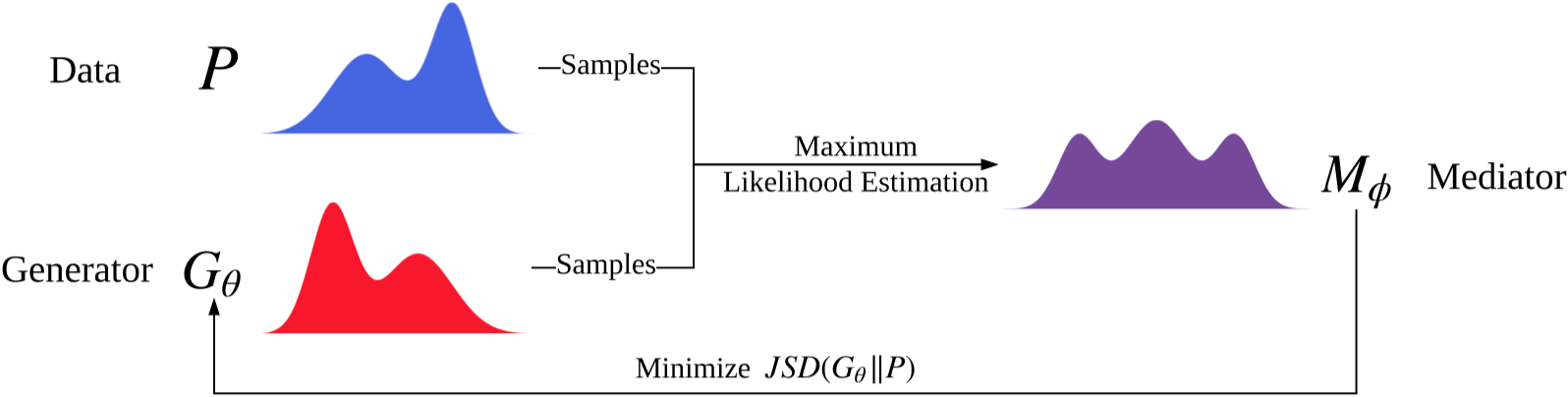
Datei ausführen: run_jsdgan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator (kein Diskriminator)
Struktur (aus meinem Verständnis)
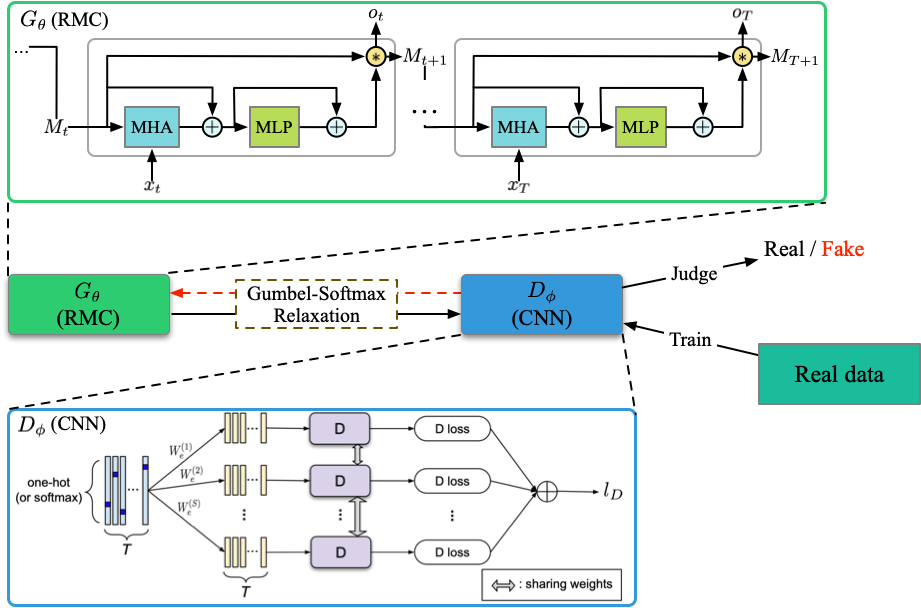
Ausführen von Datei: run_relgan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (aus meinem Verständnis)
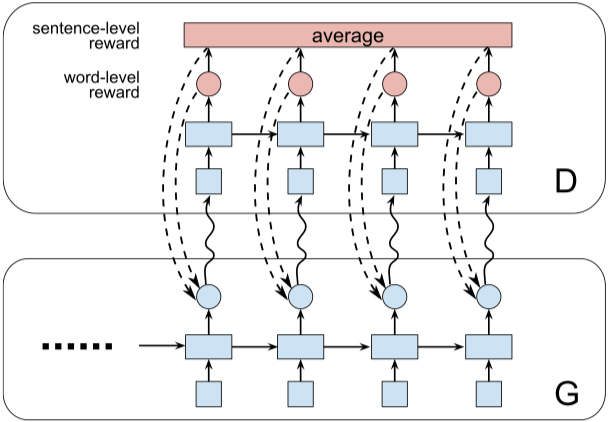
Datei ausführen: run_dpgan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (von DPGAN)
Datei ausführen: run_dgsan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Datei ausführen: run_cot.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (aus Kinderbett)
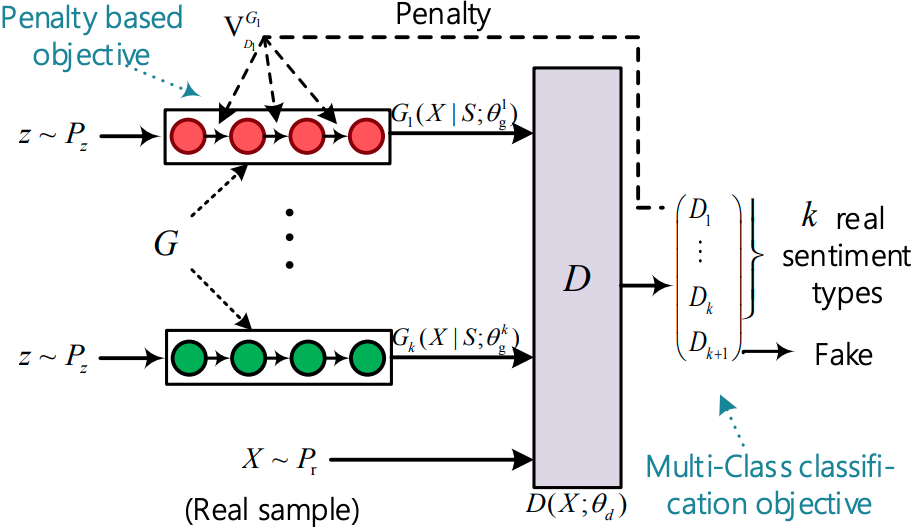
Datei ausführen: run_sentigan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (von Sentigan)
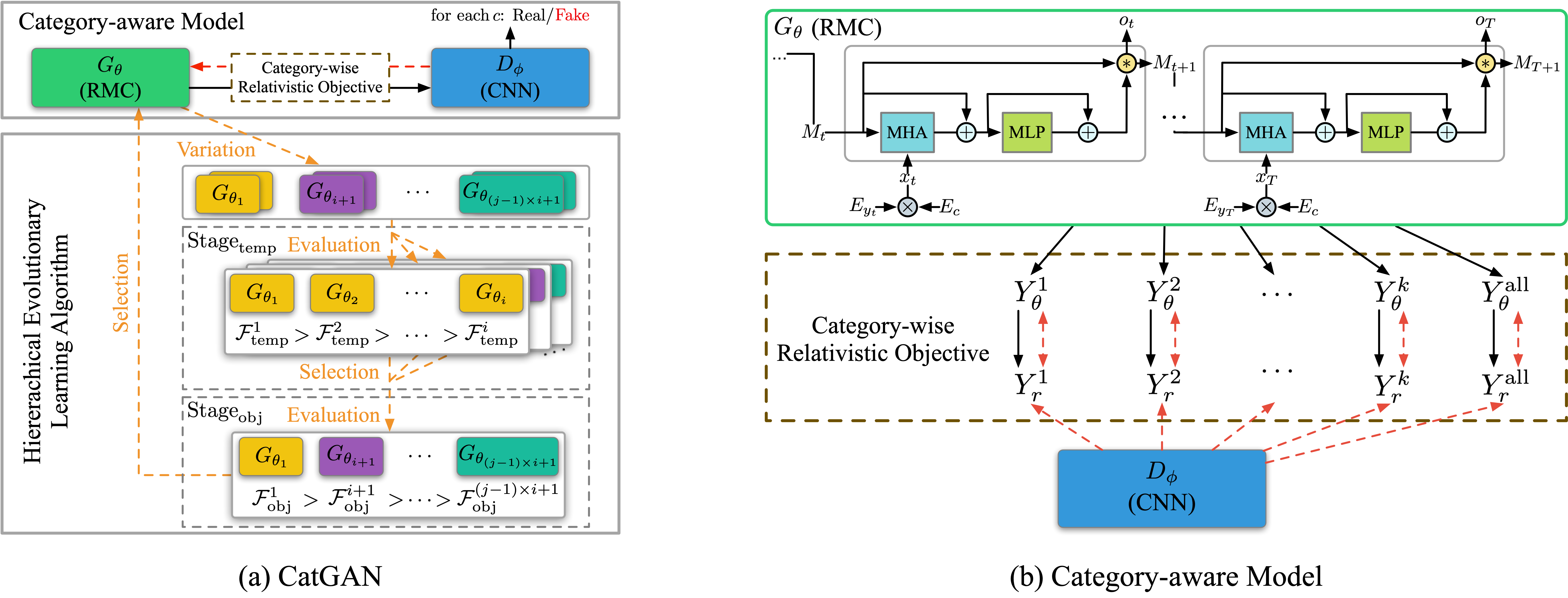
Datei ausführen: run_catgan.py
Ausbilder: Oracle_data, real_data
Modelle: Generator, Diskriminator
Struktur (aus Catgan)
MIT -Linienz


